n->1 MPI_Reduce MPI_Gather
1. MPI_Reduce函数
int MPI_Reduce(void *sendBuf, void *receiveBuf, int count, MPI_Datatype dataType,
MPI_Op operator, int root, MPI_Comm comm)
每个进程从sendBuf向root进程的receiveBuf发数据,通过opration函数(例如MPI_SUM)来汇总数据。
2. 图型示例
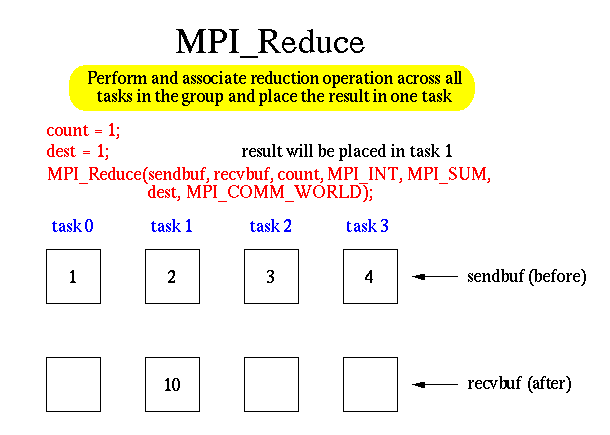
3. 举例
#include<stdio.h>
#include"mpi.h"
#define SIZE 4
int main(int argc, char *argv[]){
int totalNumTasks, rankID;
float sendBuf[SIZE][SIZE] = {
{1.0, 2.0, 3.0, 4.0},
{5.0, 6.0, 7.0, 8.0},
{9.0, 10.0, 11.0, 12.0},
{13.0, 14.0, 15.0, 16.0}
};
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rankID);
MPI_Comm_size(MPI_COMM_WORLD, &totalNumTasks);
float totalSum;
if(totalNumTasks == SIZE){
int source = 0;
int sendCount = SIZE;
int recvCount = SIZE;
float recvBuf[SIZE];
//scatter data from source process to all processes in MPI_COMM_WORLD
MPI_Scatter(sendBuf, sendCount, MPI_FLOAT,
recvBuf, recvCount, MPI_FLOAT, source, MPI_COMM_WORLD);
float sumPerProcess = recvBuf[0] + recvBuf[1] + recvBuf[2] + recvBuf[3];
printf("my rankID = %d, receive Results: %f %f %f %f, totalOnMe = %f\n",
rankID, recvBuf[0], recvBuf[1], recvBuf[2], recvBuf[3], sumPerProcess);
int count = 1;
int root = 0;
MPI_Reduce(&sumPerProcess, &totalSum, count, MPI_FLOAT, MPI_SUM, root, MPI_COMM_WORLD);
printf("Process %d is done.\n", rankID);
fflush(stdout);
}
else
printf("Please specify -n %d\n", SIZE);
MPI_Finalize();
if(rankID == 0) printf("totalSum = %f\n", totalSum);
return 0;
}
4. 编译执行
[amao@amao991 mpi-study]$ mpicc scatterReducer.c [amao@amao991 mpi-study]$ mpiexec -n 4 -f machinefile ./a.out my rankID = 0, receive Results: 1.000000 2.000000 3.000000 4.000000, totalOnMe = 10.000000 my rankID = 1, receive Results: 5.000000 6.000000 7.000000 8.000000, totalOnMe = 26.000000 Process 1 is done. my rankID = 3, receive Results: 13.000000 14.000000 15.000000 16.000000, totalOnMe = 58.000000 Process 3 is done. Process 0 is done. my rankID = 2, receive Results: 9.000000 10.000000 11.000000 12.000000, totalOnMe = 42.000000 Process 2 is done. totalSum = 136.000000
5. 总结
(1)本例先通过MPI_Scatter函数把数组分发给4个进程(每个进程收到4个float值),每个进程对自己收到的4个数据求和
(2)然后通过MPI_Reduce函数汇总4个进程的数据,得到总和totalSum值。
(3)本例典型地说明了数据分发个多个进程/每个进程单独求解/然后汇总。
----------------------------------------------------------------
1. MPI_Gather函数
MPI_Gather (&sendbuf,sendcnt,sendtype,&recvbuf, recvcount,recvtype,root,comm)
Gathers distinct messages from each task in the group to a single destination task. This routine is the reverse operation of MPI_Scatter.
2. 图示
3. 举例
#include<stdio.h>
#include<stdlib.h>
#include"mpi.h"
int main(int argc, char *argv[]){
int rankID, totalNumTasks;
MPI_Init(&argc, &argv);
MPI_Barrier(MPI_COMM_WORLD);
double elapsed_time = -MPI_Wtime();
MPI_Comm_rank(MPI_COMM_WORLD, &rankID);
MPI_Comm_size(MPI_COMM_WORLD, &totalNumTasks);
int* gatherBuf = (int *)malloc(sizeof(int) * totalNumTasks);
if(gatherBuf == NULL){
printf("malloc error!");
exit(-1);
MPI_Finalize();
}
int sendBuf = rankID; //for each process, its rankID will be sent out
int sendCount = 1;
int recvCount = 1;
int root = 0;
MPI_Gather(&sendBuf, sendCount, MPI_INT, gatherBuf, recvCount, MPI_INT, root, MPI_COMM_WORLD);
elapsed_time += MPI_Wtime();
if(!rankID){
int i;
for(i = 0; i < totalNumTasks; i++){
printf("gatherBuf[%d] = %d, ", i, gatherBuf[i]);
}
putchar('\n');
printf("total elapsed time = %10.6f\n", elapsed_time);
}
MPI_Finalize();
return 0;
}
4. 编译执行
[amao@amao991 mpi-study]$ mpicc gather.c [amao@amao991 mpi-study]$ mpiexec -f machinefile -n 5 ./a.out gatherBuf[0] = 0, gatherBuf[1] = 1, gatherBuf[2] = 2, gatherBuf[3] = 3, gatherBuf[4] = 4, total elapsed time = 0.009653
5. 总结
(1) 本例用了malloc在heap中开辟连续空间(数组)
int* gatherBuf = (int *)malloc(sizeof(int) * totalNumTasks); 而后用gatherBuf[i]的形式来逐个显示每个空间的值。