利用Haffman 算法实现对ascii字符文件的压缩
利用Haffman 算法实现对ascii字符文件的压缩
EmilMatthew([email protected])
摘要:
本文是对Haffman算法进行的一次实践。根据ascii码文件中各ascii字符出现的频率情况创建Haffman树,再将各字符对应的哈夫曼编码写入文件中。同时,亦可根据对应的哈夫曼树,将哈夫曼编码文件解压成字符文件.
关键词: Haffman算法,压缩,解压缩
Implement Haffman algorithm to the zipping of ascii file
EmilMatthew([email protected])
Abstract:
This article is a practice of haffman algorithm. First, I create the haffman tree based on the appearance frequency of each ascii character in the files ,then I output each ascii character’s corresponding haffman code to the zipped file. And I also make the program could unzip the haffman zipped files into the ascii files.
Key Words: Haffman Algorithm,Zip,UnZip
1前言:
Haffman算法是个简单而高效的贪心算法,主要用来创建最优二叉树.可以在通讯时,对于出现频率较高的字符,用较少的比特数便可以进行通讯.从而节省通讯线路的资源消耗。
该算法在各类数据结构, 算法,组合数学,离散数学,图论等主题的书籍中都有所涉及。故本文不再赘述,本文致力于用Haffman算法实现压缩与解压缩,采用的语言为C语言,编译环境VC++6.0.
下面给出[1]中实现的Haffman树的结构及创建算法,有两点说明:
a) 这里的Haffman树采用的是基于数组的带左右儿子结点及父结点下标作为存储结点
的二叉树形式,这种空间上的消耗带来了算法实现上的便捷。
b) 由于对于最后生成的Haffman树,其所有叶子结点均为从一个内部树扩充出去的,所以,当外部叶子结点数为m个时,内部结点数为m-1.整个Haffman树的需要的结点数为2m-1.
/*Code1: Haffman Algorithm*/
#define MAXCHAR 30000
#define MAXNODE 300
#define MAXNUM 150
#define InfoType char
struct HtNode
{
EBTreeType ww;
char info;
int parentIndex;
int llinkIndex;
int rlinkIndex;
};
struct HtTree
{
struct HtNode ht[MAXNODE];
int rootIndex;
};
typedef struct HtTree* PHtTree;
PHtTree haffmanAlgorithm(int m,EBTreeType* w)
{
PHtTree pht;
int i,j;
int firstMinIndex,secondMinIndex;
int firstMinW,secondMinW;
pht=(PHtTree)malloc(sizeof(struct HtTree));
assertF(pht!=NULL,"in haffman algorithm,mem apply failure/n");
/*Initialize the tree array*/
for(i=0;i<2*m-1;i++)
{
pht->ht[i].llinkIndex=-1;
pht->ht[i].rlinkIndex=-1;
pht->ht[i].parentIndex=-1;
if(i<m)
{
pht->ht[i].ww=w[i];
pht->ht[i].info=(char)i;
}
else
pht->ht[i].ww=-1;
}
for(i=0;i<m-1;i++)//new Inner Node Num:m-1
{
firstMinW=MAXCHAR;
firstMinIndex=-1;
secondMinW=MAXCHAR;
secondMinIndex=-1;
for(j=0;j<m+i;j++)
{
if(pht->ht[j].ww<firstMinW&&pht->ht[j].parentIndex==-1)
{
//trans minFirst info to minSecond info
secondMinIndex=firstMinIndex;
secondMinW=firstMinW;
//set new first min node.
firstMinIndex=j;
firstMinW=pht->ht[j].ww;
}
else if(pht->ht[j].ww<secondMinW&&pht->ht[j].parentIndex==-1)
/*update second node info*/
{
secondMinW=pht->ht[j].ww;
secondMinIndex=j;
}
}
//Construct a new node. m+i is current new node's index
pht->ht[firstMinIndex].parentIndex=m+i;
pht->ht[secondMinIndex].parentIndex=m+i;
pht->ht[m+i].ww=firstMinW+secondMinW;
pht->ht[m+i].llinkIndex=firstMinIndex;
pht->ht[m+i].rlinkIndex=secondMinIndex;
pht->rootIndex=m+i;
}
return pht;
}
2压缩过程的实现:
压缩过程的流程是清晰而简单的:
1创建Haffman树à2打开需压缩文件à3将需压缩文件中的每个ascii码对应的haffman编码按bit单位输出à4文件压缩结束。
其中,步骤1和步骤3是压缩过程的关键。
a) 步骤1:这里所要做工作是得到Haffman数中各叶子结点字符出现的频率并进行创
建.
统计字符出现的频率可以有很多方法:如每次创建前扫描被创建的文件,“实时”的生成
各字符的出现频率;或者是创建前即做好统计.本文采用后一种的方案,统计了十篇不同的文章中字符出现的频率。当前,也可以根据被压缩文件的特性有针对性的进行统计,如要压缩C语言的源文件,则可事先对多篇C语言源文件中出现的字符进行统计,这样,会创建出高度相对较“矮”的Haffman树,从而提高压缩效果。
创建Haffman树的算法前文已有陈述,这里就不再重复了。
b) 步骤3: 将需压缩文件中的每个ascii码对应的haffman编码按bit单位输出.
这是本压缩程序中最关键的部分:
这里涉及“转换”和“输出”两个关键步骤:
“转换”部分大可不必去通过遍历Haffman树来找到每个字符对应的哈夫曼编码,可以将每个Haffman码值及其对应的ascii码存放于如下所示的结构体中:
typedef struct
{
char asciiCode;
unsigned long haffCode;
int haffCodeLen;
}HaffCode;
创建由该结构体结点所组成的,长度为128的一维数组codeList[128]
且codeList中的下标和asciiCode满足下面的顺序存放关系:
codeList[i].asciiCode=i;
这样的话,查找某个字符inChar的haffman编码的工作便变得相当轻松了,如下:
sHaffCode=codeList[inChar].haffCode;
数组codeList[128]的创建可以采用某种遍历方式下的按找到的字符进行置数的方式,十分的方便:
/*Code2:
codeList的创建算法,采用前序遍历的方式进行创建.
*/
void preHaffListMake(PHtTree inTree,int rootIndex,unsigned long youBiao,int sDepth,
HaffCode* inList)
{
if(inTree->ht[rootIndex].llinkIndex==-1&&inTree->ht[rootIndex].rlinkIndex==-1)
{
inList[inTree->ht[rootIndex].info].haffCode=youBiao;
inList[inTree->ht[rootIndex].info].haffCodeLen=sDepth;
}
else
{
preHaffListMake(inTree,inTree->ht[rootIndex].llinkIndex,youBiao<<1,sDepth+1,inList);
preHaffListMake(inTree,inTree->ht[rootIndex].rlinkIndex,(youBiao<<1)|0x01,sDepth+1,inList);
}
}
“输出”部分是最重要的部分,也是最易出错的部分。
这里,涉及到C语言的位操作,要求这个算法能处理好以下几个问题:
1)每个字符所对应的haffCode的比特位长度由5~23位不等长,不可少输,多输,
输错任何一位,后一个字符的haffCode要紧跟在前一个字符的haffCode后面.
2)最后一个字符要能合理的结束。这主要是为解压缩考虑的,比如,在最后一个要输出
的haffCode的最后一位,它恰好是位于最后一个有效字符的第一位,剩下的七个比特位是要用无效的haffCode加以填充的.否则,如果填充的haffCode亦为某个ascii字符的haffCode时,那么在解压缩时,则该在原被压缩文件中不存在的字符便会无中生有的在解压后的文件中出现,这显然是不正确的,应在程序中加以处理。
编码部分的流程如图1:
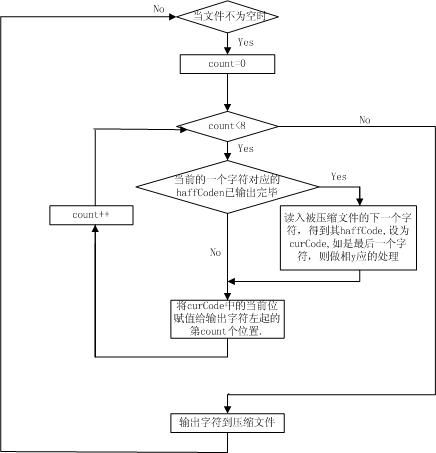
图1
/*Code3:
压缩部分的核心代码
*/
#define REARPOS 80
curIndex=curLen=0;
rearCode=haffList[REARPOS].haffCode;
rearCodeLen=haffList[REARPOS].haffCodeLen;
while(!feof(inputFile))
{
count=0;
outputData=0x01;
while(count<8)
{
/*----------------------------*/
if(curIndex==curLen)
{
//1.get data.
if(feof(inputFile))
break;
inData=fgetc(inputFile);
printf("%c",inData);
if(inData==-1&&feof(inputFile))
{
if(count==0)
outputData=-1;
else/*the rear output adjust*/
{
for(i=0;i<8-count;i++)
{
outputData<<=1;
outputData|=((rearCode>>(rearCodeLen-1-i))&0x01);
}
}
break;
}
//2.search table ->Should be a ascii file.
curCode=haffList[inData].haffCode;
curLen=haffList[inData].haffCodeLen;
realLen=getBinLen(curCode);
i=curLen-realLen;
curIndex=0;
}
if(i>0)
{
outputData<<=1;
//no need to fill bit data.
i--;
}
else
{
tmpBinData=(curCode>>(curLen-curIndex-1))&0x01;
outputData<<=1;
outputData|=(char)tmpBinData;
}
/*-----------------------------------*/
curIndex++;
count++;
}
fputc(outputData,outputFile);
}
3解压缩过程的实现:
如果说,压缩的过程可以通过查找codeList来加速实现的话,而解压缩则必须通过查找haffman树才能加以实现.查找的过程是简单的,可以根据haffman树的性质来做,当haffCode的当前bit位为0时,则向左枝展开搜索;当前bit位为1时,则向右枝展开搜索,当遇到叶子结点时,则输出haffCode对应的asciiCode。
解压缩流程如图2:
图2
/*Code4:
解压缩代码核心部分.
*/
count=8;
nodeIndex=myHtTree->rootIndex;
while(!feof(inputFile))
{
/*----------------------------*/
if(count==8)
{
//1.get data.
inData=fgetc(inputFile);//get 8 len bin haff code.
if(inData==-1&&feof(inputFile))
break;
count=0;
} if(myHtTree->ht[nodeIndex].llinkIndex==-1&&myHtTree->ht[nodeIndex].rlinkIndex==-1)
{
//send out data.
fputc(myHtTree->ht[nodeIndex].info,outputFile);
nodeIndex=myHtTree->rootIndex;
}
else
{
tmpBinData=(inData>>(7-count))&0x01;
if(tmpBinData==0x00)
nodeIndex=myHtTree->ht[nodeIndex].llinkIndex;
else if(tmpBinData==0x01)
nodeIndex=myHtTree->ht[nodeIndex].rlinkIndex;
else
printf("error happen in read bin!/n");
count++;
}
}
4拓展成一个简易的加密软件:
由于haffman树的算法是公开的,而对于不同的字符频率序列,压缩和解压缩的结果将截然不同。
因而,可以将字符频率序列从程序中剥离出来,形成一个密钥文件,这样,压缩和解压缩的过程都必需依赖于统一的密钥才能得以进行。具体程序请参考附录。
5程序压缩效果测试:
经测试,本程序对文本的压缩效果与被压缩文件的大小成正比,即被压缩文件越大,则压缩效果越好。在测试中,可将8.14KB的源代码压缩为6.40KB,压缩效率为21.4%。(参附录)
如果采集的字符出现频率为针对源程序的代码,则压缩效率必将有所增加。当然,与比较好的压缩算法,如winrar所采用的算法,还是有不少的差距的,这是受haffman本身的算法特点所限.haffman压缩算法本身的优点在于原文件及译文都是字符与字符逐字符相对应的线性流的关系,这在实时应用中有比较好的适用性。
6实验结论:
通过该程序,使得我再次得到了从理论到实践的体验,同时,通过C语言”武装到bit位”级的编程,也让我体会到保证一个程序的严谨与精准所需要付出的细致思考及努力的重要性。
参考文献:
[1]张乃孝,算法与数据结构----C语言描述,高等教育出版社,2002.
[2]何炎祥,李飞,李宁,计算机操作系统,清华大学出版社,2002.
完成日: 06/01/24
附录:
源程序打包下载
http://www.newdreamworks.com/emilmatthew/temp_files/06_07HaffZip.rar
若直接点击无法下载(或浏览),请将下载(或浏览)的超链接粘接至浏览器地址(推荐MYIE或GreenBorwser)栏后按回车.若不出意外,此时应能下载.