正式使用opencv里的训练和检测 - opencv_createsamples、opencv_traincascade
一、基础知识准备
首先,opencv目前仅支持三种特征的训练检测, HAAR、LBP、HOG,选择哪个特征就去补充哪个吧。opencv的这个训练算法是基于adaboost而来的,所以需要先对adaboost进行基础知识补充啊,网上一大堆资料,同志们速度去查阅。我的资源里也有,大家去下载吧,这些我想都不是大家能直接拿来用的,我下面将直接手把手告诉大家训练怎么操作,以及要注意哪些细节。
二、关于正样本的准备
1、采集正样本图片
因为正样本最后需要大小归一化,所以我在采集样本的时候就直接把它从原图里抠出来了,方便后面缩放嘛,而不是只保存它的框个数和框位置信息(框个数、框位置信息看下一步解释),在裁剪的过程中尽量保持样本的长宽比例一致。比如我最后要归一化成20 X 20,在裁剪样本的时候,我都是20X20或者21X21、22X22等等,最大我也没有超过30X30(不超过跟我的自身用途有关,对于人脸检测这种要保证缩放不变性的样本,肯定就可以超过啦),我资源里也给出可以直接用的裁剪样本程序。
2、获取正样本路径列表
在你的图片文件夹里,编写一个bat程序(get route.bat,bat是避免每次都需要去dos框输入,那里又不能复制又不能粘贴!),如下所示:

运行bat文件,就会生成如下dat文件:
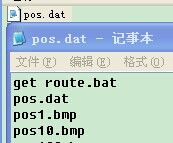
把这个dat文件中的所有非图片的路径都删掉,比如上图的头两行,再将bmp 替换成 bmp 1 0 0 20 20,如下:

(1代表个数,后四个分别对应 left top width height,如果我们之前不是把样本裁剪下来的,那么你的这个dat可能就长成这样1. bmp 3 1 3 24 24 26 28 25 25 60 80 26 26,1.bmp是完全的原图啊,你之前的样本就是从这张图上扣下来的)
3、获取供训练的vec文件
这里,我们得利用opencv里的一个程序叫opencv_createsamples.exe,可以把它拷贝出来。针对它的命令输入也是写成bat文件啦,因为cascade训练的时候用的是vec。如下:

运行bat,就在我们得pos文件夹里生成了如下vec文件:

就此有关正样本的东西准备结束。
三、关于负样本的准备
这个特别简单,直接拿原始图,不需要裁剪抠图(不裁剪还能保证样本的多样性),也不需要保存框(网上说只要保证比正样本大小大哈,大家就保证吧),只要把路径保存下来。同正样本类似,步骤图如下:


至此有关负样本的也准备完成。
四、开始训练吧
这里我们用opencv_traincascade.exe(opencv_haartraining.exe的用法跟这个很相似,具体需要输入哪些参数去看opencv的源码吧,网上资料也有很多,主要是opencv_traincascade.exe比opencv_haartraining.exe包含更多的特征,功能齐全些啊),直接上图:
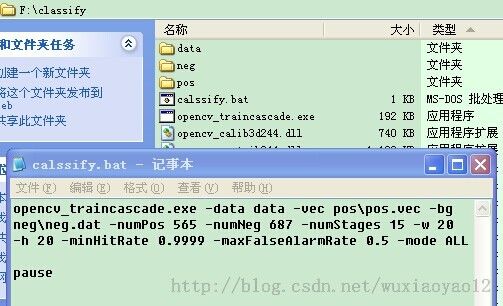
命令输入也直接用bat文件,请务必保证好大小写一致,不然不予识别参数。小白兔,跑起来~~~
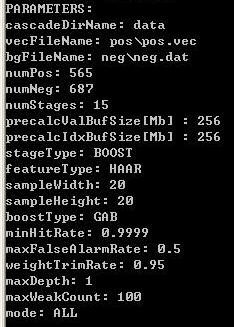
这是程序识别到的参数,没有错把,如果你哪个字母打错了,你就会发现这些参数会跟你预设的不一样啊,所以大家一定要看清楚了~~~~
跑啊跑啊跑啊跑,如下:

这一级的强训练器达到你预设的比例以后就跑去训练下一级了,同志们那个HR比例不要设置太高,不然会需要好多样本,然后stagenum不要设置太小啊,不然到时候拿去检测速度会很慢。
等这个bat跑结束,我的xml文件也生成了。如下:

其实这个训练可以中途停止的,因为下次开启时它会读取这些xml文件,接着进行上次未完成的训练。哈哈~~~~好人性化啊!
训练结束,我要到了我的cascade.xml文件,现在我要拿它去做检测了啊!呼呼~~~~
五、开始检测吧
opencv有个opencv_performance.exe程序用于检测,但是它只能用在用opencv_haartraining.exe来用的,所以我这里是针对一些列图片进行检测的,检测代码如下:
#include <windows.h>
#include <mmsystem.h>
#include <stdio.h>
#include <stdlib.h>
#include "wininet.h"
#include <direct.h>
#include <string.h>
#include <list>
#pragma comment(lib,"Wininet.lib")
#include "opencv2/objdetect/objdetect.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp"
#include <iostream>
#include <stdio.h>
using namespace std;
using namespace cv;
String cascadeName = "./cascade.xml";//训练数据
struct PathElem{
TCHAR SrcImgPath[MAX_PATH*2];
TCHAR RstImgPath[MAX_PATH*2];
};
int FindImgs(char * pSrcImgPath, char * pRstImgPath, std::list<PathElem> &ImgList);
int main( )
{
CascadeClassifier cascade;//创建级联分类器对象
std::list<PathElem> ImgList;
std::list<PathElem>::iterator pImgListTemp;
vector<Rect> rects;
vector<Rect>::const_iterator pRect;
double scale = 1.;
Mat image;
double t;
if( !cascade.load( cascadeName ) )//从指定的文件目录中加载级联分类器
{
cerr << "ERROR: Could not load classifier cascade" << endl;
return 0;
}
int nFlag = FindImgs("H:/SrcPic/","H:/RstPic/", ImgList);
if(nFlag != 0)
{
cout<<"Read Image error ! Input 0 to exit \n";
exit(0);
}
pImgListTemp = ImgList.begin();
for(int iik = 1; iik <= ImgList.size(); iik++,pImgListTemp++)
{
image = imread(pImgListTemp->SrcImgPath);
if( !image.empty() )//读取图片数据不能为空
{
Mat gray, smallImg( cvRound (image.rows/scale), cvRound(image.cols/scale), CV_8UC1 );//将图片缩小,加快检测速度
cvtColor( image, gray, CV_BGR2GRAY );//因为用的是类haar特征,所以都是基于灰度图像的,这里要转换成灰度图像
resize( gray, smallImg, smallImg.size(), 0, 0, INTER_LINEAR );//将尺寸缩小到1/scale,用线性插值
equalizeHist( smallImg, smallImg );//直方图均衡
//detectMultiScale函数中smallImg表示的是要检测的输入图像为smallImg,rects表示检测到的目标序列,1.1表示
//每次图像尺寸减小的比例为1.1,2表示每一个目标至少要被检测到3次才算是真的目标(因为周围的像素和不同的窗口大
//小都可以检测到目标),CV_HAAR_SCALE_IMAGE表示不是缩放分类器来检测,而是缩放图像,Size(30, 30)为目标的
//最小最大尺寸
rects.clear();
printf( "begin...\n");
t = (double)cvGetTickCount();//用来计算算法执行时间
cascade.detectMultiScale(smallImg,rects,1.1,2,0,Size(20,20),Size(30,30));
//|CV_HAAR_FIND_BIGGEST_OBJECT//|CV_HAAR_DO_ROUGH_SEARCH|CV_HAAR_SCALE_IMAGE,
t = (double)cvGetTickCount() - t;
printf( "detection time = %g ms\n\n", t/((double)cvGetTickFrequency()*1000.) );
for(pRect = rects.begin(); pRect != rects.end(); pRect++)
{
rectangle(image,cvPoint(pRect->x,pRect->y),cvPoint(pRect->x+pRect->width,pRect->y+pRect->height),cvScalar(0,255,0));
}
imwrite(pImgListTemp->RstImgPath,image);
}
}
return 0;
}
int FindImgs(char * pSrcImgPath, char * pRstImgPath, std::list<PathElem> &ImgList)
{
//源图片存在的目录
TCHAR szFileT1[MAX_PATH*2];
lstrcpy(szFileT1,TEXT(pSrcImgPath));
lstrcat(szFileT1, TEXT("*.*"));
//结果图片存放的目录
TCHAR RstAddr[MAX_PATH*2];
lstrcpy(RstAddr,TEXT(pRstImgPath));
_mkdir(RstAddr); //创建文件夹
WIN32_FIND_DATA wfd;
HANDLE hFind = FindFirstFile(szFileT1, &wfd);
PathElem stPathElemTemp;
if(hFind != INVALID_HANDLE_VALUE)
{
do
{
if(wfd.cFileName[0] == TEXT('.'))
continue;
if(wfd.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY || strcmp("Thumbs.db", TEXT(wfd.cFileName)) == 0)
{
;
}
else
{
TCHAR SrcImgPath[MAX_PATH*2];
lstrcpy(SrcImgPath, pSrcImgPath);
lstrcat(SrcImgPath, TEXT(wfd.cFileName));
lstrcpy(stPathElemTemp.SrcImgPath, SrcImgPath);
TCHAR AdressTemp[MAX_PATH*2];
lstrcpy(AdressTemp,pRstImgPath);
//lstrcat(AdressTemp, TEXT("/"));
lstrcat(AdressTemp, TEXT(wfd.cFileName));
lstrcpy(stPathElemTemp.RstImgPath, AdressTemp);
ImgList.push_back(stPathElemTemp);
}
}while(FindNextFile(hFind, &wfd));
}
else
{
return -1;
}
return 0;
}
附:
1、opencv_traincascade.exe参数说明
通用参数:
-data<cascade_dir_name>
目录名,如不存在训练程序会创建它,用于存放训练好的分类器
-vec<vec_file_name>
包含正样本的vec文件名(由 opencv_createsamples 程序生成)
-bg<background_file_name>
背景描述文件,也就是包含负样本文件名的那个描述文件
-numPos<number_of_positive_samples>
每级分类器训练时所用的正样本数目
-numNeg<number_of_negative_samples>
每级分类器训练时所用的负样本数目,可以大于 -bg 指定的图片数目
-numStages<number_of_stages>
训练的分类器的级数。
-precalcValBufSize<precalculated_vals_buffer_size_in_Mb>
缓存大小,用于存储预先计算的特征值(feature values),单位为MB
-precalcIdxBufSize<precalculated_idxs_buffer_size_in_Mb>
缓存大小,用于存储预先计算的特征索引(feature indices),单位为MB。内存越大,训练时间越短
-baseFormatSave
这个参数仅在使用Haar特征时有效。如果指定这个参数,那么级联分类器将以老的格式存储
级联参数:
-stageType<BOOST(default)>
级别(stage)参数。目前只支持将BOOST分类器作为级别的类型
-featureType<{HAAR(default),LBP}>
特征的类型: HAAR - 类Haar特征;LBP - 局部纹理模式特征
-w<sampleWidth>
-h<sampleHeight>
训练样本的尺寸(单位为像素)。必须跟训练样本创建(使用 opencv_createsamples 程序创建)时的尺寸保持一致
Boosted分类器参数:
-bt<{DAB,RAB,LB,GAB(default)}>
Boosted分类器的类型: DAB - Discrete AdaBoost,RAB - Real AdaBoost,LB - LogitBoost, GAB - Gentle AdaBoost
-minHitRate<min_hit_rate>
分类器的每一级希望得到的最小检测率。总的检测率大约为 min_hit_rate^number_of_stages
-maxFalseAlarmRate<max_false_alarm_rate>
分类器的每一级希望得到的最大误检率。总的误检率大约为 max_false_alarm_rate^number_of_stages
-weightTrimRate<weight_trim_rate>
Specifies whether trimming should be used and its weight. 一个还不错的数值是0.95
-maxDepth<max_depth_of_weak_tree>
弱分类器树最大的深度。一个还不错的数值是1,是二叉树(stumps)
-maxWeakCount<max_weak_tree_count>
每一级中的弱分类器的最大数目。The boosted classifier (stage) will have so many weak trees (<=maxWeakCount), as needed to achieve the given-maxFalseAlarmRate
类Haar特征参数:
-mode<BASIC(default)| CORE|ALL>
选择训练过程中使用的Haar特征的类型。 BASIC 只使用右上特征, ALL 使用所有右上特征和45度旋转特征
2、detectMultiScale函数参数说明
该函数会在输入图像的不同尺度中检测目标:
image -输入的灰度图像,
objects -被检测到的目标矩形框向量组,
scaleFactor -为每一个图像尺度中的尺度参数,默认值为1.1
minNeighbors -为每一个级联矩形应该保留的邻近个数,默认为3,表示至少有3次检测到目标,才认为是目标
flags -CV_HAAR_DO_CANNY_PRUNING,利用Canny边缘检测器来排除一些边缘很少或者很多的图像区域;
CV_HAAR_SCALE_IMAGE,按比例正常检测;
CV_HAAR_FIND_BIGGEST_OBJECT,只检测最大的物体;
CV_HAAR_DO_ROUGH_SEARCH,只做粗略检测。默认值是0
minSize和maxSize -用来限制得到的目标区域的范围(先找maxsize,再用1.1参数缩小,直到小于minSize终止检测)