Memcached、Redis、RDD(Spark)的数据处理性能对比(Efficient in-memory data management: an analysis论文翻译)
摘要:
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
本论文分析了三个内存数据管理系统的性能:
Memcached(分布式缓存)、Redis(
一个开源的使用ANSI C语言
编写、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库
)以及Spark中使用的弹性分布式数据集RDD。通过分析操作以及细粒度的实体操作比如get/set,来进行较为彻底的性能分析,我们最终发现上述这些系统无法同时高效地满足多种工作负荷(即系统无法使得所有类型的工作任务都能高效地实现)。对
Memcached和
Redis来说,在一个单独的server节点提供基于内存的服务的时候,CPU和TCP栈的I/O性能会产生瓶颈。对于RDD来说,由于get所带来的较大的启动开销,RDD对于随机数据对象的get操作并不
高效
。最后,我们给出
系统才可以实现高效的内存数据管理
所必须支持的一系列功能。
Objective(客观的、目标的) And Experimental(实验性质的) Methodology(方法)
内存数据管理需要
支持
两种重要类型的操作:
- 支持分析操作
- 支持任意对象的存储和检索操作
- Workloads setup
通过pagerank算法处理map/reduce过程来检测系统的分析性能:
- 在map阶段,计算每一个web page邻居节点的对该page的贡献排名并将该信息传递出去,换句话说就是计算一个节点对其他节点的排名贡献。
- 在reduce阶段,每个节点基于贡献排名(其他节点对自己的排名贡献)计算出自己的排名。
环境:
(1)
Spark:本身就支持mapreduce,且自带pagerank算法的实现示例。环境:Spark 0.8.0/scala 2.9.3(java1.7.0)
(2)
Memcached:是一种key/value存储,且仅仅支持set/get操作。为了在
Memcached之上完成pagerank算法的测试,我们需要驱动程序进行支持(驱动程序被
Memcached的服务器节点进行控制
)。环境:
Sypmemcached Client 2.10.3(driver program)、
Memcached 1.4.15、 gcc 4.6.3
如下图所示,就相当于
Memcached
通过构建Master来控制外部的driver program,创建很多的driver procress进而来管理自己的server node上面的数据以及对数据进行相应的计算。
(3)
Redis:也是
一种key/value存储,可以进行基本的get/set操作,还有一些高级操作,比如流水线操作、服务器端脚本以及事务等。跟
Memcached类似,
Redis也需要驱动程序;跟
Memcached不同的是Redis支持
服务器端脚本,因此pagerank的算法过程可以在服务器端通过lua脚本实现(无需依赖驱动程序)
。环境:
Aredis Client 1.0、
Redis 2.6.16、 gcc 4.6.3
其他环境配置说明:
- Memcached 和Redis 服务器节点以及RDD worker节点配置的cache大小为5GB。
- 每个服务器采用默认的线程数;Memcached 和Redis 的drivers是蔡总多线程异步连接的方式与server节点进行通信的,为了实验的协调一致性,选择的线程配置营保证系统达到最好的分析性能:Memcached采用5线程,Redis采用6线程。
数据形式:
Memcached和
Redis需要用一个key/value对象来保存图中每个节点的邻居节点信息;另一个
key/value对象来保存每个节点的pagerank(page排名)信息。
RDD使用两个RDD,第一个RDD存储图中的每一条边,第二个RDD用来存储计算之后的pagerank(page排名)。
- Datasets(数据集)
两个数据集:
- Google Web Graph Dataset,875,713节点和5,105,039边。数据集大小是72MB。将上述数据加载到单节点内存的时候,Redis占用85MB,Memcached占用135MB,RDD占用3.9GB。
- Pokec Social Network 1,632,803节点和30,622,564条边。数据集大小是405MB。将上述数据加载到单节点内存的时候,RDD超过了最小cache的大小5GB,第二个数据集仅仅是为了证明RDD的伸缩性,因为第一个数据集对RDD而言太小了。
在M
emcached和
Redis中,数据在集群中的分布采用hash方式,数据分布
较为均匀。RDD中,数据分布采用的是Spark默认的机制(策略较多hash、range等等),也是相对均匀的。
- 测试系统
采用两种类型的系统进行性能的测试:
(1)
集群
16 Intel Xeon X3430 nodes, each with 4 cores/4 hardware threads,
8 GB DDR3 RAM, 256 KB L1 Cache, 1 MB L2 Cache, 8 MB
L3 Cache, inter-connected using 1Gbps Ethernet, and running
64-bit Linux kernel 2.6.18.
(2)
单节点
为了分析的高效,我们事先移除了网络I/O的瓶颈。
The node has two Intel Xeon X5650 pro-
cessors, each with 6 cores/12 hardware threads, and 24 GB of
DDR3 RAM. The memory architecture is Non Uniform Mem
ory Access, where each processor directly connects to 12 GB of
RAM, and the two processors are interconnected by a fast In
tel QuickPath bus that can support transfers at 25.6 GB/s.
系统: 64-bit Linux kernel 3.2.0。
测试
工具:
pref tool:获取体系结构需要的硬件事件计数器;
time command:获取用户态和内核态的时间;
trace tool:跟踪系统调用;
测试的时候
需要尽可能关闭后台的其他应用程序,每种测试进行三次取结果的平均值(三次结果不应该有较大的差异)。
PERFORMANCE(性能) OF IN-MEMORY ANALYTICS
- 集群系统性能分析
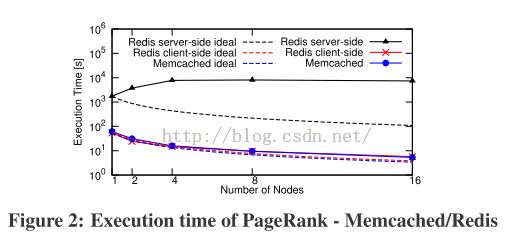
该部分主要分析各个系统在不同数量node节点下pagerank算法的执行时间。
Memcached;Redis client-side;Redis server-side(1~16nodes)
RDD(1~16nodes)
- 可以看出在数据集一的情况下,RDD和Memcached/Redis的差距最为明显。 RDD 完成一次交互比Memcached快1.3-14X,比Redis client-side快1.4-12X,比Redis server-side快400X。其中,Redis server-side效率最低,因为该模式下每个server节点使用lua脚本进行单线程执行的方式(不依赖driver),线程要花费较长的时间处理脚本任务,所以其他的server来的requests就会一直等待,并且,增加server node数量之后,图像呈上升趋势,原因就是更多的server在等待。
- Memcached和Redis client-side的测量时间接近理想的的测量时间。RDD虽然完成的很快,但是拟合的很糟糕。
- 可以看出,随着node数量的增加,node之间的通信导致RDD的总的计算时间产生了相应的呈现出比例的变化。当node数量较少的时候,图的规模超过了cache的大小,因此,在pagerank的计算过程中,RDD必须将磁盘中的数据加载到内存之后进行计算,也因为node数量比较少,node之间的交流时间也很少。因此,当node数量较少的时候,pagerank的计算时间(数据获取以及计算)相对执行时间(执行时间包含communication)而言占据更大比重。当node数量较多的时候,数据集可以全部保存在内存之中,内存和磁盘之间的数据交换几乎不会占用计算过程的时间,也因此,当node数量较多的时候,node之间的通信将会占用更多的时间,因为节点之间的通信开销与node的数量是线性相关的。此时,增加更多的node节点,pagerank的执行时间也不会减少,此现象会随着数据集的增加得到改善,因为更大的数据集会把瓶颈传递给计算阶段。
- 单节点系统性能分析
该部分主要比较RDD和Memcached/Redis之间的性能差异。
参数:CPU的使用(程序使用的平均core的数量);
花费在内核态的CPU时间的百分比;每秒钟的系统调用次数
其中,RDD,Memcached以及Redis client-side在CPU的使用方面表现地很好。然而,内核态的CPU使用时间方面,RDD花费的时间很少,
Memcached和Redis却花费很多的时间,上述现象恰恰被各个系统环境下每秒钟系统调用的次数多少的差异所影响。通过进一步的研究,可以发现,90%~99%的调用都是用于driver线程同步的系统调用,然而这些调用很快,并不会花费过多的时间,其实,最花费时间的调用是网络的读写调用(TCP)。每一次的数据请求,driver会执行两次
系统调用
,同时,
Memcached的server会执行3次系统调用,
Redis会执行6次
。下一节
我们应该将对TCP端的key/value数据传输进行更加深入的研究
。
RDD优良性能(
内核态的CPU使用时间很少
)的主要原因是所有的分析操作在同一过程被执行并生成相应的数据,且RDD获取数据的过程不会执行任何的系统调用,因为获取数据直接依赖上述过程的
堆存储
。
PERFORMANCE OF OBJECT OPERA
TIONS
这部分是针对随机数据对象的set/get操作吞吐率的分析。因为RDD不支持set操作,因此再次只考虑RDD的get操作。且为了使得RDD的get操作更加高效,我们人为创建一种索引机制:将所有的关键字keys与RDD的partition的偏移量建立hash关系。实验采用单节点和多节点的配置。因为get和set操作类似,这里只分析在不同方案下的两种操作之一的测试情况。
- Concurrency(并发性) Tuning
首先,将服务器的性能调整到最优。之后,进行如下配置:
多节点:
(i) four threads for Mem-
cached servers, three client nodes per server node, each client node
holding 10 clients, each client using a single TCP connection per
server;
(ii) same settings for Redis expect for the thread configura
tion;
(iii) 64 threads for RDD driver and default settings for Spark.
单节点:
(i) one Memcached server
using 12 threads, four clients, each using 50 concurrent connec
tions;
(ii) one Redis server, three clients each with 50 concurrent connections;
(iii) same settings for RDD as in the multi-node.
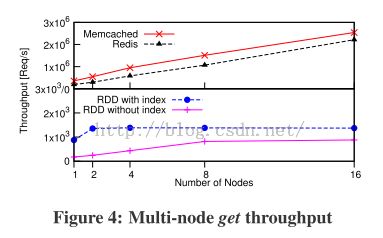
- Multi-node Throughput(吞吐率)
这部分是来分析节点数量对吞吐率的影响。
测试:1~16个节点变化过程,在2秒之内对吞吐率进行10次采样。get操作的对比图:
从图中可以看出,
Memcached和Redis的吞吐量的变化跟node的数量的关系几乎是线性的,数量级达到百万级。相反,RDD的get操作的吞吐量不仅要低3个数量级,并且,当node节点的数量大于8的时候,吞吐率不再发生变化,且即使是RDD加上hash索引之后的吞吐率也仅仅只增加了1.6-5X。
导致
上述性能差异的因素有两个:
第一,Spark的job隔离机制(job之间是并行的,互相不影响),只有一个driver来服务RDDs的请求,这种机制会给driver带来更大的负担,当节点过多的时候就会带来瓶颈。相反
Memcached和Redis可以允许随机数量的clients同时查询数据(driver负担较小)。在测试的过程中,driver即使采用多线程,加上索引的RDD在大于2nodes之后性能不再改善
,没有加索引的RDD在8nodes之后性能不再改善。
第二,两种RDD运行机制下,
job的启动的
get操作每次执行会耗费0.8ms,这么长的响应时间也影响了第一种情况下的性能。
Memcached和Redis与node数量呈线性关系,但是每个节点的吞吐率仍旧低于125MB/s中占据6-17MB/s的网络吞吐率。
- Single-node Throughput
这部分用来分析
在Memcached and Redis系统下数据量的大小对吞吐率的影响。
(1)
Memcached and Redis
该部分针对Memcached和Redis系统,改变key size以及value size下进行set或get操作的吞吐率的分析。
可以看出每秒钟的requests的吞吐率在value size为10 bytes~1 kB之间时基本上是常数,1kB~10kB之间有略微的下降。但是,超过10kB之后,下降的较为明显,是因为对可用带宽更好的使用。
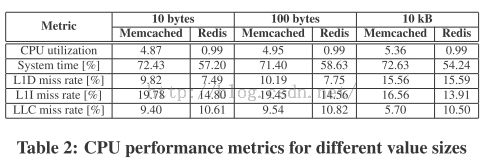
下表是对不同大小的数据量进行测试的结果:
该表是不同大小数据集在
Memcached和Redis上通过get/set操作的性能测试数据。
从表中的数据可以看出两个现象:
1)指令cache缺失率(未命中)在数据对象较小的时候很高,当value size变大的时候又会降低。
2)数据cache缺失率是相反的变化趋势。
需要注意的一个现象是
Memcached和Redis提供服务的时间基本上都花费在epoll机制下的通信处理了。
较高的
指令cache缺失率对于CPU的执行效率影响较大,目前市面上的CPU内核的操作使用的是乱序执行的方式(与流水线相对),该方式下允许出现较多的数据cache的不命中现象,未命中的数据可以通过二级、三级cache缓存或者是主存进行获取,但是该方式仅仅允许一次指令cache缺失(个人认为是不能出现连续的指令cache缺失,指令cache缺失的开销较大)。因此,当同时有较多的数据请求时,数据cache缺失带来的数据fetch开销就无关紧要了,但是指令cache缺失引起的延迟却无法忽略。因此,较多的指令cache的缺失会导致70%的CPU时间被用于将指令从内存fetch到cache。
如果我们使用工具进行跟踪,会发现在 Memcached/Redis计算过程中,内核在TCP执行过程以及epoll机制的执行过程中会花费大量的时间。同时,发现大部分的一级指令cache的缺失来自于TCP阶段的操作过程。
可以得出这样的结论,TCP在处理小的数据对象的过程中效率低下。所以为了高效的转换key/value数据对象,所有的数据对象的大小在理想情况下应高超过100KB。
最近的一篇论文,分析了使用
Memcached进行
web cache部署的性能问题,提到了当处理的数据对象的大小为1KB~4KB的时候出现了严重的性能问题。他们也发现network stack(TCP过程)是主要的影响因素,但是他们的分析没有并没有联系到系统级别的特性。在web部署中,key/value数据数据对象无法被合并成为更大的元数据,他们提出的解决方法是使用传统的硬件在没有CPU干预的情况下进行网络连接的处理。
(2)RDD
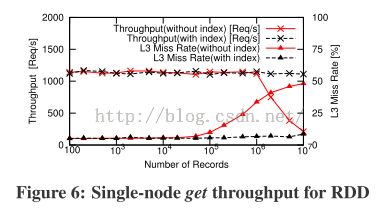
该部分针对RDD,分析数据记录的数量对每秒钟requests的吞吐率的影响。
记录很少的时候,RDD的get任务启动的消耗是瓶颈。当数据量达到106时,在没有索引的情况下的RDD的连续的扫描过程中,内存访问成为瓶颈。
数据量小于10
6
时
带索引的RDD的吞吐率基本没有什么变化,此时get任务的启动消耗是瓶颈。
当数据量超过10
6
时,吞吐率并没有提升,也没有下降,因为
get任务的启动消耗抵消了应有的吞吐率的提升
。所以我们可以得到以下结论:索引不能给get操作的吞吐率带来优势,因为get任务的启动消耗直接影响了响应时间。
- CONCLUSIONS(总结) AND SYSTEM DESIGN(提倡的系统实现) IMPLICATIONS
- 没有系统可以高效地处理各种各样的任务: Memcached和Redis下的应用通过TCP+EPOLL的方式获取内存数据,被证明性能低下。而RDD由于get操作的启动消耗也无法支持高效的get操作。
- 如何设计支持高效的分析和细粒度操作的系统:
首先,系统必须在同一个节点能够支持快速的IPC(进程间通信)并且高效地进行小规模数据对象的转换;
第二,节点之间的进程间通信业应该使用TCP,然而应该尽可能地避免小规模数据对象的转换,而是应该将小规模的数据对象合并成为大规模的数对象;
第三,快速获取随机数据对象需要建立索引;
第四,对于set/get请求而言,需要一个轻量级的框架;
并且,数据对象的相关操作(get等)消耗会抵消应有的吞吐率的提升。
otherwise the startup cost of
an object operation will compromise the achievable throughput.