traffic server cache源码分析四 初始化与元数据同步
http://blog.chinaunix.net/uid-23242010-id-2953692.html
之前我们讨论过,cache的索引在trafficserver启动时,会从磁盘加载到内存中。这里有两个问题。
问题1:内存中的索引被更新后,与磁盘中保存的部分已经不一致,我们称之为脏了,这时需要将索引写回至磁盘中去。
问题2:设想这样一种情况,trafficserver将索引写回磁盘后,开始将agg_buffer中信息写入磁盘,未等这个过程结束,trafficserver就因为某种原因stop了,导致磁盘上保存的索引信息与实际存储的内容两者之间信息不一致。
存储机制这篇文章中,我们分析过cache的DiskLayout设计。索引维护在磁盘的Directory中,其中header与footer保存的是索引元信息以及cache读写行为的信息,而位于它们之间的就是实际索引存储区。header与footer都是同一个数据结构类型VolHeaderFooter,这个结构中与本文相关的信息如下:
- struct VolHeaderFooter
- {
- off_t write_pos; //当前磁盘写位置
- off_t last_write_pos; //上次磁盘写位置
- uint32_t sync_serial; //索引写回磁盘时,++sync_serial
- uint32_t write_serial; //写agg_buffer至磁盘时,++write_serial
- };
问题1分析
cache的DiskLayout中可以看到有两个Directory,按照先后顺序称为A与B。trafficserver在启动后,会不定期将内存中索引写回磁盘中去。写回过程是这样的,首先会将header的值赋给footer,然后先写header,再写索引区,最后写footer。
问:为什么保存两份Directory?
答:比如trafficserver启动后,加载A至内存构建索引。如果只有一份Directory,那么在写回时,在将内存中索引写回磁盘时,trafficserver由于某种原因异常退出,这时磁盘上索引就被损坏了,严重时导致无法修复而丢失所有数据。如果有两份Directory,那么在写回时,可以将索引写回至B,这时即使出错,那么下次启动时,至少还有A是可用的,虽然不可避免也会丢失一些数据。
问:为什么需要header,footer两次来保存索引元信息?
答:同上,如果写完header,索引部分还没写完,trafficserver就异常退出。下次启动时,发现header与footer信息不一致,就可以证明这次写回操作失败,从而选择另一个Directory使用。
问:每次将内存中索引写回至磁盘的哪一个部分?
答:通过header的sync_serial来区分。每次写到磁盘上之前,都会++sync_serial,如果是偶数,写至A,否则,写至B。
代码分析:
- //当trafficserver正常退出时,会将索引写回磁盘
- sync_cache_dir_on_shutdown()
- //CacheSync这个Continuation会不定期被调用将索引写回磁盘
- CacheSync::main_event()
问题2分析
trafficserver在启动时,会将磁盘中索引加载至内存。当将索引读至内存后,这时cache还是不能提供服务的,需要解决上次退出时可能的异常行为导致索引与存储内容的元信息不一致问题。
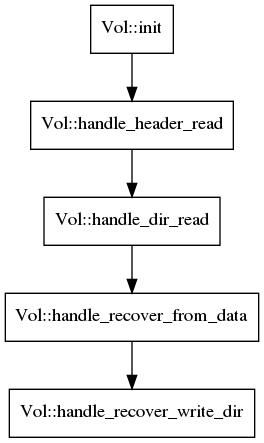
上图是cache启动后,索引从磁盘加载到内存的过程。
(1) trafficserver启动后,首先会将A与B的header与footer读取出来。
(2) 比较A与B的header与footer,选择A还是B构建索引。
(3) 将索引读入内存后,判断是否读取正确,设置元信息等。
(4) 这是整个过程的核心。将磁盘中保存的与索引信息不一致的object读取出来,根据header提供的元信息,与每个object的元信息进行比较。如果这个object是可用的,则更新header元信息。最后将无效的objects的索引清空,也就是执行删除object操作。
(5) 当recover完成后,就代表内存加载成功了。Vol::handle_recover_write_dir更新scan信息,执行periodic_scan,函数流程进入Vol::dir_init_done,至此磁盘读取索引至内存完成。