3 队列
顺序队列
生产者消费者模型
链式队列
队列(queue)跟上一章中介绍的栈数据结构一样,也是一种操作受限的线性表。栈的操作受限表现在插入和删除只能对栈顶元素进行,删除的元素永远是最新插入的,即操作遵循后入先出(LIFO)原则。这一章将讨论的队列中的操作原则与栈的相反。删除的元素是最早插入到队列中的,就像排队一样,排在最前面的人将最先从队伍中出列。这样的操作原则常常称作先入先出(FIFO,First In First Out)。由于队列结构和栈结构具有相反的操作原则,我们在的设计队列是将在栈的设计结构的基础上做一定的“反向”调整。本章同样首先介绍队列的ADT,然后介绍两种队列的实现方式:顺序队列和链表队列。
首先根据队列的操作原则,其接口设计如下:
import Element.ElemItem;
/**
* 队列接口设计,Queue.java
*/
public interface Queue {
public void enqueue(ElemItem elem); // 向队列列尾插入新元素
public ElemItem dequeue(); // 将队列列首处的元素项删除并返回
public ElemItem frontVal(); // 返回列首的元素项
public int currSize(); // 返回当前队列中有效元素项的个数
public void printQueue(); // 从队列头开始打印的队列中所有元素项
}
顺序队列
在设计顺序栈时我们将对应元素项数组的最后一个元素作为栈顶,元素是从数组的第一个位置开始存放的。在插入元素和弹出元素都在数组的最后一个位置进行。这样的操作不需要对数组中元素做移向操作,复杂度为O(1)。在顺序队列中,元素也是从数组的第一个位置开始存放,插入元素依旧是在数组的最后一个位置进行,操作复杂度为O(1)。不同的是,删除元素项的操作需要在数组的第一个位置进行。如果考虑数组的连续性,在删除元素项之后需要将其中第二个元素至最后一个元素依次向前平移,如图,这样的操作复杂度与线性表中删除元素的复杂度相同,为O(n)。从前面几章内容的分析可以看出这样的复杂度是比较高的。如果在删除数组首部的元素之后不将其后的元素依次前移,能将复杂度将为O(1),但是此时的队列列首如何表示?
我们可以用一个位置标识来保存列首位置,而不将数组的第一个位置作为队列的列首。但是这样会使得数组中部分元素浪费,如图。如果删除多次,则队列资源将很快耗尽。在一些存储策略中,有一种称为“循环存储”,即存储内容占满整个存储空间时将继续从存储器起始位置开始重新存储。
这里我们借用类似的思路,当队列列为到数组的尾部时,将列为前置到数组数组的首位,并继续向后存放内容,直至队列列首的前一位置,如图。
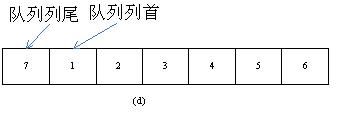
这样就可以充分占满整个队列,并且避免了数组中元素的移动。在遍历队列中元素时则从列首位置开始依次向后访问数组中元素,当到达数组尾部时再从数组首位开始向后访问,直至到达队列列首所指示的位置,即上图中1~6之后,从头开始访问7。这样的结构可以在逻辑上想象成环状的队列。
具体来说,用head表示队列列首的指示,tail表示队列列首的指示,则在遍历队列中所有元素时可以通过一个从head开始的指示i,并依次执行i←(i+1)%N,来依次访问数组中每个元素,N表示的是数组的长度。可以用一个变量currSize来记录当前队列中的有效元素项的个数,当currSize等于N时则表示此时队列已满,否则可以继续向其中插入元素,并将列为位置循环后移,tail←(tail+1)%N。在删除列首位置的元素项时,只要currSize大于0,则将列首位置循环后移,head←(head+1)%N。注意到,这里的head和tai在数值上没有明确的大小关系。
一个细节的问题是,在队列为空时head和tail的值应如何初始化。如果tail初始化为0,则在插入第一个元素后tail←(0+1)%N=1,但是事实上tail应该为0。所以在队列初始化时,tail的值应该设置成-1。在队列中只有一个元素项时,tail和head相等,例如为tail=head=1,删除元素,head←(head+1)%N=2,即列表为空,但是tail和head不同,所以对这种情况也要特使考虑,可以直接将head←0,tail←-1,让一切从头再来。
基于上面的考虑,设计顺序列表类:
import Element.ElemItem;
/**
* 顺序队列类 SequentialQueue.java
*/
public class SequentialQueue implements Queue{
private int head; // 队列列首
private int tail; // 队列列尾
private int totalSize; // 队列的最大长度
private int currSize; // 当前队列有效元素项的个数
private ElemItem sqlQueueData[]; // 用数组组织队列的元素项
public SequentialQueue( int _totalsize){ // 构造函数
head = 0; // 初始化列首为位置0
tail = -1; // 初始化列尾为位置0
// 初始化列表元素个数
totalSize = (_totalsize > 0)?(_totalsize):0;
sqlQueueData = new ElemItem[totalSize];
currSize = 0;
}
public SequentialQueue(){ // 构造函数
head = 0; // 初始化列首为位置0
tail = -1; // 初始化列尾为位置0
totalSize = 0; // 初始化列表元素个数
currSize = 0;
}
public void enqueue(ElemItem elem) {
if(currSize >= totalSize) System.out.println("队列已满!");
else{
tail = (tail + 1) % totalSize; // 队列列尾循环后移
sqlQueueData[tail] = elem; // 在队列尾添加新元素
currSize++; // 有效元素项个数增加1
}
}
public ElemItem dequeue() {
if(currSize <= 0){ // 当前队列中元素为空
System.out.println("队列为空!");
return null;
}
else if(currSize == 1){ // 队列中只剩一个元素项时
// 暂存待返回的元素项
ElemItem forReturn = sqlQueueData[head];
head = 0; // 将队列还原为初始状态
tail = -1;
currSize--;
return forReturn;
}
else{
// 暂存待返回的元素项
ElemItem forReturn = sqlQueueData[head];
head = (head + 1) % totalSize; // 列头循环后移
currSize--; // 当前有效元素个数递减1
return forReturn; // 返回出列的元素项
}
}
public ElemItem frontVal() {
if(currSize <= 0){ // 当前队列为空
System.out.println("队列为空,无法返回列首元素项");
return null;
}
else{
return sqlQueueData[head];
}
}
public int currSize() {
return currSize;
}
public void printQueue() {
int cnt = 0;
if(currSize == 0)System.out.println("队列为空!");
else{
for( int i = head; cnt < currSize - 1;
i = (i + 1) % totalSize){
System.out.print(sqlQueueData[i].getElem()
+ ", ");
cnt++;
}
System.out.println(sqlQueueData[tail].getElem()
+ ".");
}
}
}
在顺序列表类中,引入了五个私有成员变量,head和tail分别表示队列的列首和列尾,totalSize和currSize分别表示队列的最大长度和当前有效元素的长度,sqlQueueData数组表用于存储队列中的元素项。
队列的概念在计算机操作系统中有着很重要的地位。在支持多线程和多进程操作系统中临界区的操作是一个关键问题。最典型的讨论模型是“生产者—消费者”模型。
生产者-消费者模型是多线程编程中的基本模型也是运用最多的模型,而它的原理就是一个线程向缓冲池中扔东西,另一个线程从缓冲池中把东西拿走,如图。所以在这个模型中缓冲池是生产-消费者之间的桥梁。但是生产者和消费者彼此独立,且运行速度不确定,所以很可能出现生产者生产了过多的信息而消费者却没来得及消费导致缓冲池溢出,如图(a),或者消费者消费过快导致缓冲区为空,如图(b)。这就需要一种同步机制在生产者和消费者之间进行同步。这里的关键就是缓冲池必须是固定大小不能随意扩充,因为程序一瞬间就能把堆耗尽。池满了则生产者必须等待,池空了则消费者必须等待。就是好比我们去蛋糕店买蛋糕,柜台和货架就是缓冲池糕点师是不能无限制的做蛋糕.所以缓冲池的最大,最小值(不一定为0)就是临界条件。我们可以用用队列来做缓冲池的载体,因为通常在操作系统中会要求进程的执行顺序为FIFO(当然实际操作系统中存在进程之间的抢占)。
图 进程1向缓冲池中写数据进程2从缓冲池中读数据
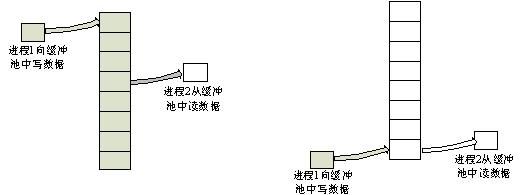
图 (a)缓冲池慢了写进程需要等待 (b)缓冲池空了读进程需要等待
这里我们通过顺序队列来模拟这一过程。假设进程池大小为5,生产者和消费者一共竞争100次。过程中动态改变生产者和消费者的速度,这里用消费发生概率描述,消费概率越大则生产者较消费者速度越快,让这个概率在0.01到0.99之间以0.01为步长变动时,仿真过程流程度如图所示。
生产者消费者模型仿真流程图
生产者—消费者模型示例程序如下:
import Element.ElemItem;
/**
* 顺序链表测试示例程序,仿真生产者-消费者模型
* ExampleSequentialQueue.java
*/
public class ExampleSequentialQueue {
public static void main(String args[]){
SequentialQueue sqlQueue = new SequentialQueue(5);
// 标识消费者和生产者的标识位:0——消费者;1——生产者
int idxCP = 0;
int numWait[] = new int[98];
int numOverFlow[] = new int[98];
for( int k = 1; k < 99; k++){ // 调整消费者消费速度(由小到大)
for( int i = 0; i < 100; i++){ // 共竞争100次
// 用于表征当前是消费还是生产
idxCP = ( int)(Math.random() + ( double)k / 100d);
if(0 == idxCP){ // 消费者
if( null == sqlQueue.dequeue()) // 队列为空
numWait[k-1] += 1; // 消费者等待
}
else if (1 == idxCP){ // 生产者
if(sqlQueue.currSize() == 5) // 队列满了
{
numOverFlow[k-1] += 1; // 生产者等待
continue;
}
// 生产进行
else
sqlQueue.enqueue( new ElemItem<Integer>(1));
}
}
}
// 返回生产者和消费者在不同消费速度下的等待次数
for( int i = 0; i < 98; i++)
System.out.print(numWait[i] + "\t");
System.out.println();
for( int i = 0; i < 98; i++)
System.out.print(numOverFlow[i] + "\t");
}
}
在本示例程序中,利用Java的Math类的random()函数生成随机数,生成的随机数为0~1之间的双精度类型记为R。调节消费者消费速度的方法是将0~1之间的随机数做调整,R’=R+k/100,这里的k的变化范围是1~98。对R’取整[R'],其中[x]表示不大于x的整数,则取整后的结果是0或1,但是取0和取1的概率不一定是不等的。例如k=30时,R’=R+0.3,所以R’的取值范围是0.3~1.3,取整后idxCP取0的概率是0.7,而取1的概率为0.3;同样当k=60时,idxCP取1的概率是0.6,而取0的概率为0.4。只有在k=50的时候idxCP取0和取1的概率是相等的。所以k逐渐变大的过程中消费者消费速度逐渐表小,而生产者的生产速度逐渐变大。
生产者和消费者的等待次数如图所示。可以发现在消费概率在0.4到0.5之间时两者的等待时间比较接近。消费速度过快则会频繁导致队列处于空状态,而生产速度过快则会导致队列频繁处于填满状态。
链表队列
上一章中我们讨论的链表栈的结构比较简洁,插入和弹出操作都是在链表的尾部进行。考虑到删除元素项时栈顶指针的前移更新复杂度,链表栈的各节点包含的next指针的指向为链表尾的前一个节点,并依次向前,直到链表的头部,即对栈的栈底。
在用链表设计队列时,我们同样需要重点考虑元素项的删除操作复杂度,即队列列首元素的删除。如果每个节点中包含的next指针的指向与链表栈中相同,在删除队列列首元素后更新列首位置是,则需要从列尾,及图中栈顶位置开始逐个寻找新的列首位置,复杂度为O(n)。很明显这样的结构时不合理的。在上一节中我们提到,队列和栈结构有某种对应的反向关系,我们可以将栈中各个节点的next指针反向,如图所示,将队列尾的next指针指向空。

读者很容易发现上图中的链表队列结构下可以通过原列首的next指针定位到新的列首位置,复杂度为O(1)。
顺序队列的设计如下:
import Element.ElemItem;
import List.SingleNode;
/**
* 链表队列类,LinkQueue.java
*/
public class LinkQueue implements Queue{
private SingleNode head; // 队列头
private SingleNode tail; // 队列尾
private int currSize; // 当前队列的元素项的个数
public LinkQueue(){ // 构造函数
head = null;
tail = null;
currSize = 0;
}
public void enqueue(ElemItem elem) {
// 以创建新的节点
if(tail == null){ // 当前队列为空
// 创建新节点作为tail和head
tail = new SingleNode(elem, null);
head = tail;
currSize++;
return;
}
// 当前队列不是空的,则新节点添加到队列尾部
tail.setNext( new SingleNode(elem, null));
tail = tail.getNext();
currSize++;
}
public ElemItem dequeue() {
ElemItem forReturn;
// 当前元素大于一个,正常处理
if(currSize > 1){
forReturn = head.getElem();
head = head.getNext();
currSize--;
}
// 当前只有一个元素项,直接将head和tail重置为空
else if(currSize == 1){
forReturn = head.getElem();
head = null;
tail = null;
currSize--;
}
// 队列为空,返回null
else forReturn = null;
return forReturn;
}
public ElemItem frontVal() {
if(currSize == 0) return null; // 当前队列为空
else return head.getElem();
}
public int currSize() {
return currSize;
}
public void printQueue() {
if(currSize <= 0) System.out.println("队列为空");
else{
System.out.println("队列的元素项cong列首到列尾为:");
for(SingleNode node = head; node != tail;
node = node.getNext()){
System.out.print(node.getElem().getElem() + ", ");
}
System.out.println(tail.getElem().getElem() + ".");
}
}
}
虽然链表队列具有很好的动态性,而且对其操作的复杂度比较低,但是只在实例如际的操作系统组织结构中链表队列的应用没有顺序表广。在操作系统中队列对应于内存中堆存储部分,这部分的空间都比较小,类似于长度受限的顺序队列,我们在程序设计中定义的数组等就是存放在堆中。正因为顺序队列能很好地与实际的问题建立联系,它有着更高的研究价值,正如我们在上一节中介绍的示例。当然,链表队列可以在一些实际程序设计中常常有着不可替代的地位,如在本书树数据结构的讨论中链表队列将能很有效地利用于树的层序打印。