java学习之路——利用SAX解析XML实例
SAX是Simple API for XML的缩写,它并不是由W3C官方所提出的标准,虽然如此,使用SAX的还是不少,几乎所有的XML解析器都会支持它。
与DOM比较而言,SAX是一种轻量型的方法。我们知道,在处理DOM的时候,我们需要读入整个的XML文档,然后在内存中创建DOM树,生成DOM树上的每个Node对象。当文档比较小的时候,这不会造成什么问题,但是一旦文档大起来,处理DOM就会变得相当费时费力。特别是其对于内存的需求,也将是成倍的增长,以至于在某些应用中使用DOM是一件很不划算的事(比如在applet中)。这时候,一个较好的替代解决方法就是SAX。
SAX在概念上与DOM完全不同。它不同于DOM的文档驱动,它是事件驱动的,它并不需要读入整个文档,而文档的读入过程也就是SAX的解析过程。所谓事件驱动,是指一种基于回调(callback)机制的程序运行方法。
输入XML文件到XMLReader-->XMLReader(parse())解析-->ContentHandler(相当事件监听器,定义了好多方法,常用的startDocument(),endDocument(),startElement(),endElement(),characters())
在XMLReader parse()过程中生成相应事件,以触发ContentHandler中相应的方法。
与DOM比较而言,SAX是一种轻量型的方法。我们知道,在处理DOM的时候,我们需要读入整个的XML文档,然后在内存中创建DOM树,生成DOM树上的每个Node对象。当文档比较小的时候,这不会造成什么问题,但是一旦文档大起来,处理DOM就会变得相当费时费力。特别是其对于内存的需求,也将是成倍的增长,以至于在某些应用中使用DOM是一件很不划算的事(比如在applet中)。这时候,一个较好的替代解决方法就是SAX。
SAX在概念上与DOM完全不同。它不同于DOM的文档驱动,它是事件驱动的,它并不需要读入整个文档,而文档的读入过程也就是SAX的解析过程。所谓事件驱动,是指一种基于回调(callback)机制的程序运行方法。
输入XML文件到XMLReader-->XMLReader(parse())解析-->ContentHandler(相当事件监听器,定义了好多方法,常用的startDocument(),endDocument(),startElement(),endElement(),characters())
在XMLReader parse()过程中生成相应事件,以触发ContentHandler中相应的方法。
以下是我写的代码:
package com.lcq.java.Sax;
import java.io.File;
import java.util.Stack;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxTest2 {
/**
* @param args
* @throws Exception
* @throws ParserConfigurationException
*/
public static void main(String[] args) throws ParserConfigurationException, Exception {
//第一步:获得解析工厂的实例
SAXParserFactory spf = SAXParserFactory.newInstance();
//第二部:获得工厂解析器
SAXParser sp = spf.newSAXParser();
//第三部:对xml进行解析
sp.parse(new File("test.xml"), new MyHandler2());
}
}
class MyHandler2 extends DefaultHandler{
private Stack<String> stack = new Stack<String>();
private String id;
private String title;
private String keywords;
private String kind;
private String describe;
private String date;
private String url;
private String author;
private String publisher;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
//将当前元素的名字压到栈中
stack.push(qName);
//将元素的属性名字和值一一打印出来
for (int i = 0; i < attributes.getLength(); i++) {
String attrname = attributes.getQName(i);
String attrvalue = attributes.getValue(i);
System.out.println(attrname + "=" + attrvalue);
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
//将栈顶中的元素出栈
String tag = stack.peek();
//分别判断当前栈顶中的元素与哪个定义的元素名字字符串相同,若相同则把当前的元素的字符串的值赋值给该变量
if("id".equals(tag)){
id = new String(ch,start,length);
}
else if ("title".equals(tag)) {
title = new String(ch,start,length);
}
else if ("keywords".equals(tag)) {
keywords = new String(ch,start,length);
}
else if ("kind".equals(tag)) {
kind = new String(ch,start,length);
}
else if ("describe".equals(tag)) {
describe = new String(ch,start,length);
}
else if ("date".equals(tag)) {
date = new String(ch,start,length);
}
else if ("url".equals(tag)) {
url = new String(ch,start,length);
}
else if ("author".equals(tag)) {
author = new String(ch,start,length);
}
else if ("publisher".equals(tag)) {
publisher = new String(ch,start,length);
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
//将栈顶元素移除
stack.pop();
//分别将xml中的元素信息打印输出
if("resourceitem".equals(qName)){
System.out.println("id:" + id);
System.out.println("title:" + title);
System.out.println("keywords:" + keywords);
System.out.println("kind:" + kind);
System.out.println("describe:" + describe);
System.out.println("date:" + date);
System.out.println("url:" + url);
System.out.println("author:" + author);
System.out.println("publisher:" + publisher);
}
}
}
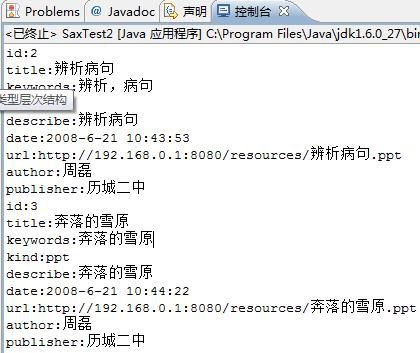
运行的结果见下图: