spark内核揭秘-09-RDD的count操作 触发Job全生命周期-02
接着上一篇文章继续分析代码:
3.1.3.3.3.1、进入TaskSet 方法:
3.1.3.3.3.2、进入taskScheduler.submitTasks(new TaskSet(tasks.toArray, stage.id, stage.newAttemptId(), stage.jobId, properties)) 方法:
从源代码中可以看出DAGScheduler中向TaskScheduler以Stage为单位提交任务,Stage是以TaskSet为单位的,构建一个TaskSetManager,当isLocal=false(集群模式)& hasReceivedTask=false(没启动的),将会创建一个定时任务来监控worker集群是否启动,并且是15000毫秒后启动,并间隔15000毫秒继续循环运行
3.1.3.3.3.3、进入 backend.reviveOffers() 方法:
该方法是 CoarseGrainedSchedulerBackend的方法,此时会向driverActor发送ReviveOffers消息,driverActor的实现代码如下:
此时跟踪进DriverActor的实现中:

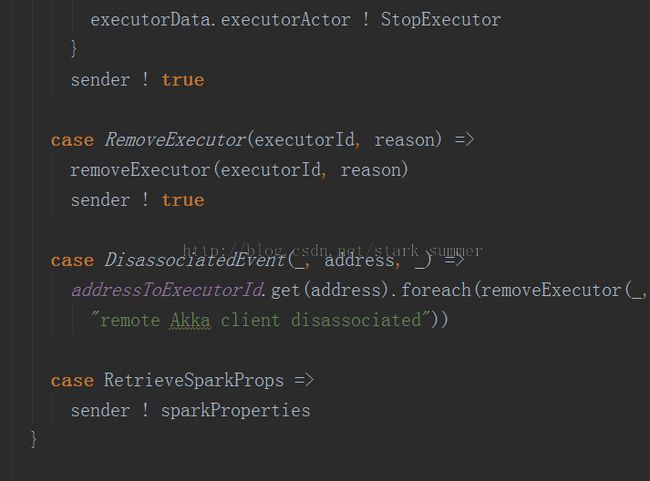
可以看到ReviveOffers消息的具体实现是makeOffers方法:
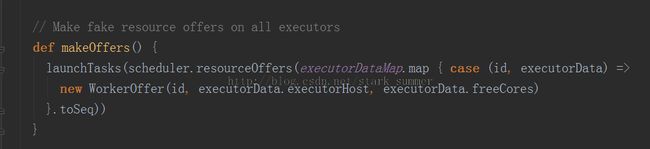
WorkerOffer对象代表是某个Executor上可用的资源,freeCores(id)是该executor上空余的CPU数目:
进入launchTasks:


executorActor发送启动Task的请求,其实是向CoarseGrainedExecutorBackend发送LaunchTask消息:


在LaunchTask消息中会导致executor.lauchTask(this, taskDesc.taskId, taskDesc.name, taskDesc.serializedTask)的调用:

其中的TaskRunner封装了任务本身:

任务执行的是交给了线程池去执行的。 其实这些代码已经分析过了,在之前的博客中
我们在回到SparkContext:

4、进入progressBar.foreach(_.finishAll())方法:
5、进入rdd.doCheckpoint()方法

进入checkpointData.get.doCheckpoint()方法:

