Hadoop学习笔记之初始HBase
Hbase 是Apache Hadoop的数据库,具有开源、分布式、可扩展和面向列存储的特点,借鉴谷歌的Bigtable思想。
说到数据库,我们最开始使用的是关系型数据库,但是HBase不同于一般的关系型数据库,
她介于Nosql和RDBMS之间,常常将其归为Nosql。
HBase适合非结构化数据存储的数据库,而且是基于列的模式,一个数据行拥有一个可选择的键和任意数量的列,所以HBase是稀疏的。她的数据列可以根据需要动态添加。
HBase可以直接使用本地文件系统,也可以使用HDFS文件存储系统。
对应的是单机模式和集群模式。
HBase的单机模式环境搭建
HBase安装文件默认情况下支持单机模式。单机模式下,HBase不使用HDFS,而是使用本机的文件系统作为存储。修改hbase-site.xml配置文件:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///DIRECTORY/hbase</value>
</property>
</configuration>
其中DIRECTORY为本地文件系统的一个目录
默认 hbase.rootdir 是指向 /tmp/hbase-${user.name} ,也就说你会在重启后丢失数据(重启的时候操作系统会清理/tmp目录)
单机模式的HBase,所有的服务都运行在一个JVM上,包括HBase和Zookeeper。HBase的日志放在logs目录,当你启动出问题的时候,可以检查hbase-user-master-example.org.out
所以必须安装java,可以编辑hbase-env.sh:
将其中的JAVA_HOME指向到你Java的安装目录。
启动hbase shell
开始创建我们的第一个HBase表:
1>create ‘student’ , {NAME => 'info' ,VERSIONS => 1},{NAME =>'data' , VERSIONS => 3}
创建student表,列族info只有一个版本,data列族有三个版本
2>put ‘student’,’rk0001’,’info:name’,’zhangsan’
3>put ‘student’,’rk0001’,’info:age’,’18’
4>put ‘student’,’rk0001’,’info:sex’,’boy’
5>put ‘student’,’rk0002’,’info:name’,’lisi’
6>put ‘student’,’rk0001’,’Grade:chinese’,’100’
7>put ‘student’,’rk0001’,’Grade:math’,’59’
8>put ‘student’,’rk0001’,’Grade:math’,’58’
9>put ‘student’,’rk0001’,’Grade:math’,’99’
10>put ‘student’,’rk0002’,’Grade:math’,’99’
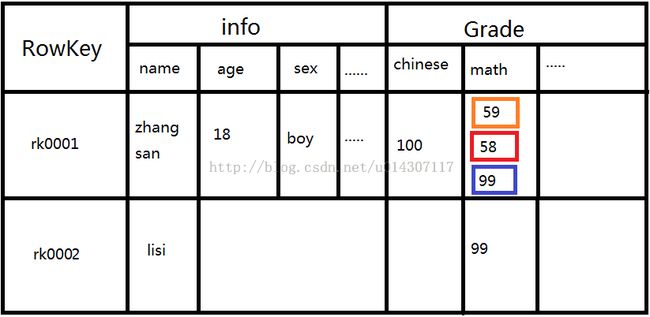
我们有一张学生信息表,记录了学生的信息和成绩。
表中共有两名学生
张三,18岁,男,语文100,数学第一次考了59,第二次58,但三次爆发考了99。
李四,数学考了99
这里强调几个概念:
Version:版本号,保存数据的n个版本。
例如第8条数据插入以后,并不会覆盖第7条插入的数据,而是追加一个新的版本。
我们可以通过下面语句查找出该数据的所有版本:
scan 'stu', {COLUMN => 'Grade:math', VERSIONS => '3'}
插入的所有数据没有数据类型,均是以二进制的形式存放在每个单元中。
HBase表的索引是行关键字,列关键字和时间戳。
来看看我们刚创建的表的逻辑视图:
接着我们介绍几个概念:
Row Key
row key是用来检索记录的主键。访问hbase table中的行,只有三种方式:
1、通过单个row key访问
2、通过row key的range
3、全表扫描
行键是不可分割的字节数组。行是按字典排序由低到高存储在表中的
列族
hbase表中的每个列,都归属与某个列族。列族是表的一部分(而列不是),必须在使用表之前定义。访问控制、磁盘和内存的使用统计都是在列族层面进行的。
在HBase是列族一些列的集合。一个列族所有列成员是有着相同的前缀。比如,列info:name和 info:age 都是 列族 info的成员.冒号(:)是列族的分隔符,用来区分前缀和列名。column 前缀必须是可打印的字符,剩下的部分(称为qualify),可以又任意字节数组组成。列族必须在表建立的时候声明。column就不需要了,随时可以新建。
在物理上,一个的列族成员在文件系统上都是存储在一起。因为存储优化都是针对列族级别的,这就意味着,一个column family的所有成员的是用相同的方式访问的。
Cell
由{row key, column( =<family> + <label>), version} 唯一确定的单元。
比如:{rk0001,info:name},通常版本号默认为最近一次更新的数据。
cell中的数据是没有类型的,全部是字节码形式存贮。Cell的内容是不可分割的字节数组
但是有可能会有很多的单元的行和列是相同的,例如上面表中的数学成绩,我们这时候可以使用版本来区分不同的单元.
rows和column key是用字节数组表示的,version则是用一个长整型表示。这个long的值使用 java.util.Date.getTime() 或者 System.currentTimeMillis()产生的。这就意味着他的含义是“当前时间和1970-01-01 UTC的时间差,单位毫秒。”
在HBase中,版本是按倒序排列的,因此当读取这个文件的时候,最先找到的是最近的版本。
时间戳
HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
了解的基本的HBase概念,我们开始搭建HBase集群。
搭建HBase集群(假设你的zookeeper集群已经搭建好)
1、我们需要修改hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_55
默认情况下HBase自身维护着一组默认的zookeeper实例,但是通常用户可以配置独立的zookeeper实例,这样是HBase系统更加健壮
在hbase-env.sh文件中
HBASE_MANAGES_ZK默认值为true,表示HBase使用自身所带的zookeeper实例,但是该实例只能为单机或伪分布模式下的HBase提供服务。若搭建的是集群模式,我们需要将该值设置为false,否则启动HBase的时候会将zookeeper作为自身的一部分运行,对应进程是HQuorumPeer。但是设置成false后,在启动HBase之前,我们必须首先启动zookeeper集群,出现的进程为QuorumPeerMain
export HBASE_MANAGES_ZK=false
2、修改hbase-site.xml
此时并没有结束
因为我们并没有明确的指出namenode的位置,我们只是抽象的给出了NameService的名称,
所以还需要将NameNode与其的对应关系,这个关系在hdfs-site.xml下给出了,所以我们只需要将这个文件拷贝到${HBASE_HOME}/conf/目录下即可。
3、修改regionservers文件
HBase集群分为HBase Master 和HBase Regionserver ,类似于搭建hadoop集群下的slaves文件,我们将regionserver机器的主机名写入该文件。
hadoop02
hadoop03
4、我们将配置好的HBase目录拷贝到其余节点
scp -r /hadoop/hbase-0.96.2-hadoop2/ hadoop02:/hadoop/
5、启动zookeeper集群
6、启动HDFS,因为HBase利用HDFS作为存储
7、启动HBase,在主节点(hadoop01)上运行
8、集群搭建完成,可以通过浏览器访问HBase的管理页面。
192.168.1.201:60010
9、为保证集群的可靠性,类似namenode,需要启动多个HMaster
在另外一台机器上启动HMaster,由于只有三台机器,我在第三台上运行
hbase-daemon.sh start master
至此,HBase集群就算搭建成功了。
接下来我们结合集群分析HBase的物理模型
HBase的服务器体系结构遵从简单的主从服务器架构,由HRegion Server和HBase Master Server构成。HMaster服务器负责管理所有的HRegion服务器,而HBase中所有的服务器都是通过zookeeper来进行协调并处理HBase服务器运行期间可能遇到的错误。
HBase逻辑上的表可能会被划分成多个HRegion,然后存储到HRegion服务器群中。
HMaster服务器上存储的是数据到HRegion服务器上的映射。
HBase体系结构如图所示:

HRegion是分布式存储和负载均衡的最小单元。最小单元表示不同的HRegion可以分布在不同的HRegion server上。但一个HRegion是不会拆分到多个server上的。
每个表最开始的时候只有一个HRegion,随着数据的不断插入,当超过设定的阈值时,HRegion服务器会调用HRegion.closeAndSplit(),将此HRegion拆分成两个,并且汇报给主服务器让其决定由哪台HRegion服务器存放新的HRegion。用表名+开始/结束主键( [startkey,endkey) )来区分每一个HRegion。一个HRegion会保存一个表里面的某段连续的数据,一张完整的表格是保存在多个HRegion上面的。
HRegion的切分是HRegionServer完成的,但是切分好之后的迁移是通过HMaster完成
数据库的数据保存在HDFS上,用户可以通过一系列的HRegion服务器获取这些数据。一台机器一般只运行一个HRegion服务器,而且每一个区段的HRegion也只会被一个HRegion服务器维护。
HRegion服务器包含HLOG部分和HRegion部分。
HLOG:
存储数据日志,采用先写日志的方式。HLOG主要用于故障恢复。当某一台HRegionserver发生故障时,它所维护的HRegion会被分配到其他机器上,这时HLOG会按照HRegion进行划分,新的机器在加载HRegion的时候可以通过HLOG对数据进行恢复。
HRegion:
由很多的HRegion组成,存储的是实际的数据。每一个HRegion又由很多的Store组成,每一个Store存储的实际上是一个列族下的数据。每一个HStore中包含一块MemStore。
MemStore驻留在内存中,数据到来时首先更新到MemStore中,当到达阈值之后再更新到对应的StoreFile(HFile)中,每一个Store包含了多个StoreFile,StoreFile负责的是实际数据存储,是HBase中最小的存储单元。当Store中StoreFile的数量超过设定的阈值时将触发合并操作-----将多个StoreFile文件合并成一个StoreFile。
HMaster服务器会和HRegion服务器进行通信,HMaster的主要任务就是告诉每个HRegion服务器它要维护哪些HRegion。
HMaster在功能上主要负责Table和HRegion的管理工作:
1>管理用户对Table的增删改查操作
2>管理HRegion服务器的负载均衡,调整HRegion的分布
3>在HRegion分裂后,负责新HRegion的分配
4>在HRegion服务器停机后,负责失效HRegion服务器上的HRegion迁移。
架构体系

各组件功能:
Client:
包含访问HBase的接口,client维护着一些缓存来加快对hbase的访问,例如region的位置信息
Zookeeper:
保证集群在任何时候,只有一个活跃的master
存储所有region的寻址入口
实时监控RegionServer,将RegionServer的上下线信息实时通知给master
(Master向zookeeper保持心跳,并且从zookeeper获取regionserver的信息,从而监控RegionServer)
存储HBase的schema。例如集群中有那些表,每个表有哪些列族
Master:
为RegionServer分配Region(Region分裂时)。
负责RegionServer上的负载均衡
发现失效的RegionServer并重新分配其上的Region
HDFS上的垃圾文件回收:
(删除一条记录,并不是真正删除,而是追加,若总数量超过version的数量,先插入的过一段时间内存flush的时候,删除)
处理schema的更新请求
(客户端从zookeeper获得master的信息,与master进行通信,进行ddl操作(创建表等))
RegionServer
维护master分配给它的Region,处理对这些Region的IO请求
负责切分在运行过程中变的过大的Region
可以看出,client访问HBase上的数据的过程并不需要master参与(寻址访问zookeeper和RegionServer,读写访问RegionServer),master仅仅维护着table和region的元数据信息,负载很低
两张特殊的表
Region的位置信息究竟是如何获取到的,这就依赖两张表,0.96之前是-root-,.meta.0.96之后hbase:meta、hbase:namespace
HBase中有两张表:-root-,.meta.,.meta.中存储的是所有表中的region位置信息,但是谁来存储.meta.的位置信息呢,毋庸置疑必须是-root-了,但是HBase的数据非常多,也就是说meta可能会被分割成多个HRegion。你可能会想到-root-也会随着数据的增长会分割成多个HRegion,但是错了。根数据表(-root-)是不能被分割的,永远只存在一个HRegion。
但是谁又来存储-root-的位置信息呢?答案是zookeeper。默认路径是/hbase/root-region-server
我们来理一下,当客户端连接到zookeeper,先去扫描根数据表(-root-),获取元数据表(-meta-)的位置,继而查找meta表,获取需要查找的region位置信息存储在哪个RegionServer上,查询到以后,客户端直连到RegionServer上,获取需要的信息。
网上搜到一个比较完善的大致流程:
假设你需要通过某个特定的RowKey查询一行记录,首先Client端会连接Zookeeper ,通过Zookeeper,Client能获知哪个Server管理-ROOT- Region。接着Client访问管理-ROOT-的Server,进而获知哪个Server管理.META.表。这两个信息Client只会获取一次并缓存起来。在后续的操作中Client会直接访问管理.META.表的Server,并获取Region分布的信息。一旦Client获取了这一行的位置信息,比如这一行属于哪个Region,Client将会缓存这个信息并直接访问HRegionServer。久而久之Client缓存的信息渐渐增多,即使不访问.META.表也能知道去访问哪个HRegionServer。
客户端访问数据的过程:
Client===》zookeeper===》-ROOT-====》.META.===>用户数据表
整个过程中,涉及到的有Zookeeper、RegionServer。如果有缓存Zookeeper也没有压力。没有缓存的话,需要由-root-表-->.META.表--->操作所在的RegionServer。即使.META.表也是与RegionServer的连接。
通过JAVA开发HBase应用程序
参考资料:
http://abloz.com/hbase/book.html
http://jiajun.iteye.com/blog/899632
http://blog.csdn.net/map_lixiupeng/article/details/40857825
HBase存储架构:
http://www.360doc.com/content/11/0714/22/28217_133622183.shtml
Hadoop实战
Hadoop权威指南