HTTP1.1中CHUNKED编码解析
HTTP1.1中CHUNKED编码解析
一般HTTP通信时,会使用Content-Length头信息性来通知用户代理(通常意义上是浏览器)服务器发送的文档内容长度,该头信息定义于HTTP1.0协议RFC 1945 10.4章节中。浏览器接收到此头信息后,接受完Content-Length中定义的长度字节后开始解析页面,但如果服务端有部分数据延迟发送吗,则会出现浏览器白屏,造成比较糟糕的用户体验。
解决方案是在HTTP1.1协议中,RFC 2616中14.41章节中定义的Transfer-Encoding: chunked的头信息,chunked编码定义在3.6.1中,所有HTTP1.1 应用都支持此使用trunked编码动态的提供body内容的长度的方式。进行Chunked编码传输的HTTP数据要在消息头部设置:Transfer-Encoding: chunked表示Content Body将用chunked编码传输内容。根据定义,浏览器不需要等到内容字节全部下载完成,只要接收到一个chunked块就可解析页面.并且可以下载html中定义的页面内容,包括js,css,image等。
采用chunked编码有两种选择,一种是设定Server的IO buffer长度让Server自动flush buffer中的内容,另一种是手动调用IO中的flush函数。不同的语言IO中都有flush功能:
l php: ob_flush(); flush();
l perl: STDOUT->autoflush(1);
l java: out.flush();
l python: sys.stdout.flush()
l ruby: stdout.flush
采用HTTP1.1的Transfer-Encoding:chunked,并且把IO的buffer flush下来,以便浏览器更早的下载页面配套资源。当不能预先确定报文体的长度时,不可能在头中包含Content-Length域来指明报文体长度,此时就需要通过Transfer-Encoding域来确定报文体长度。
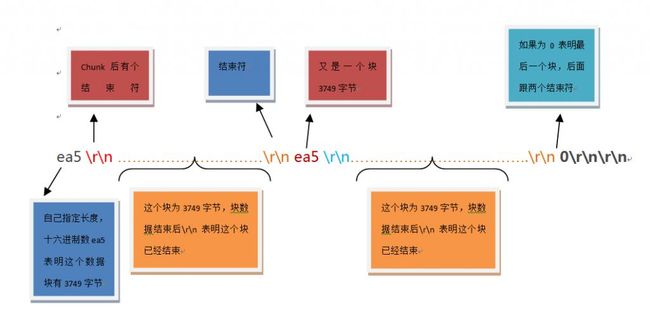
Chunked编码一般使用若干个chunk串连而成,最后由一个标明长度为0的chunk标示结束。每个chunk分为头部和正文两部分,头部内容指定下一段正文的字符总数(非零开头的十六进制的数字)和数量单位(一般不写,表示字节).正文部分就是指定长度的实际内容,两部分之间用回车换行(CRLF)隔开。在最后一个长度为0的chunk中的内容是称为footer的内容,是一些附加的Header信息(通常可以直接忽略)。
上述解释过于官方,简而言之,chunked编码的基本方法是将大块数据分解成多块小数据,每块都可以自指定长度,其具体格式如下(BNF文法):
Chunked-Body = *chunk //0至多个chunk
last-chunk //最后一个chunk
trailer //尾部
CRLF //结束标记符
chunk = chunk-size [ chunk-extension ] CRLF
chunk-data CRLF
chunk-size = 1*HEX
last-chunk = 1*("0") [ chunk-extension ] CRLF
chunk-extension= *( ";" chunk-ext-name [ "=" chunk-ext-val ] )
chunk-ext-name = token
chunk-ext-val = token | quoted-string
chunk-data = chunk-size(OCTET)
trailer = *(entity-header CRLF)
解释:
l Chunked-Body表示经过chunked编码后的报文体。报文体可以分为chunk, last-chunk,trailer和结束符四部分。chunk的数量在报文体中最少可以为0,无上限;
l 每个chunk的长度是自指定的,即,起始的数据必然是16进制数字的字符串,代表后面chunk-data的长度(字节数)。这个16进制的字符串第一个字符如果是“0”,则表示chunk-size为0,该chunk为last-chunk,无chunk-data部分。
l 可选的chunk-extension由通信双方自行确定,如果接收者不理解它的意义,可以忽略。
l trailer是附加的在尾部的额外头域,通常包含一些元数据(metadata, meta means "about information"),这些头域可以在解码后附加在现有头域之后
下面分析用ethereal抓包使用Firefox与某网站通信的结果(从头域结束符后开始):
Address 0.......................... f
000c0 31
000d0 66 66 63 0d 0a ............... // ASCII码:1ffc/r/n, chunk-data数据起始地址为000d5
显然,“1ffc”为第一个chunk的chunk-size,转换为int为8188。由于1ffc后,马上就是CRLF,因此没有chunk-extension。chunk-data的起始地址为000d5, 计算可知下一块chunk的起始
地址为000d5+1ffc + 2=020d3,如下:
020d0 .. 0d 0a 31 66 66 63 0d 0a .... // ASCII码:/r/n1ffc/r/n
前一个0d0a是上一个chunk的结束标记符,后一个0d0a则是chunk-size和chunk-data的分隔符。
此块chunk的长度同样为8188, 依次类推,直到最后一块
100e0 0d 0a 31
100f0 65 61 39 0d 0a...... //ASII码:/r/n/1ea9/r/n
此块长度为0x1ea9 = 7849, 下一块起始为100f5 + 1ea9 + 2 = 11fa0,如下:
11fa0 30 0d 0a 0d 0a //ASCII码:0/r/n/r/n
“0”说明当前chunk为last-chunk, 第一个0d 0a为chunk结束符。第二个0d0a说明没有trailer部分,整个Chunk-body结束。
解码流程:
对chunked编码进行解码的目的是将分块的chunk-data整合恢复成一块作为报文体,同时记录此块体的长度。
RFC2616中附带的解码流程如下:(伪代码)
length := 0 //长度计数器置0
read chunk-size, chunk-extension (if any) and CRLF //读取chunk-size, chunk-extension和CRLF
while(chunk-size > 0 )
{ //表明不是last-chunk
read chunk-data and CRLF //读chunk-size大小的chunk-data,skip CRLF
append chunk-data to entity-body //将此块chunk-data追加到entity-body后
length := length + chunk-size
read chunk-size and CRLF //读取新chunk的chunk-size 和 CRLF
}
read entity-header //entity-header的格式为name:valueCRLF,如果为空即只有CRLF
while (entity-header not empty) //即,不是只有CRLF的空行
{
append entity-header to existing header fields
read entity-header
}
Content-Length:=length //将整个解码流程结束后计算得到的新报文体length,作为Content-Length域的值写入报文中
Remove "chunked" from Transfer-Encoding //同时从Transfer-Encoding中域值去除chunked这个标记
length最后的值实际为所有chunk的chunk-size之和,在上面的抓包实例中,一共有八块chunk-size为0x1ffc(8188)的chunk,剩下一块为0x1ea9(7849),加起来一共73353字节。
注:对于上面例子中前几个chunk的大小都是8188,可能是因为:"1ffc" 4字节,""r"n"2字节,加上块尾一个""r"n"2字节一共8字节,因此一个chunk整体为8196,正好可能是发送端一次TCP发送的缓存大小。
最后提供一段PHP版本的chunked解码代码:
$chunk_size = (integer)hexdec(fgets( $socket_fd, 4096 ) );
while(!feof($socket_fd) && $chunk_size > 0)
{
$bodyContent .= fread( $socket_fd, $chunk_size );
fread( $socket_fd, 2 ); // skip /r/n
$chunk_size = (integer)hexdec(fgets( $socket_fd, 4096 ) );
}
其C语言的解码如下,java思路相同
int nBytes;
char* pStart = a; // a中存放待解码的数据
char* pTemp;
char strlength[10]; //一个chunk块的长度
chunk : pTemp =strstr(pStart,"/r/n");
if(NULL==pTemp)
{
free(a);
a=NULL;
fclose(fp);
return -1;
}
length=pTemp-pStart;
COPY_STRING(strlength,pStart,length);
pStart=pTemp+2;
nBytes=Hex2Int(strlength); //得到一个块的长度,并转化为十进制
if(nBytes==0)//如果长度为0表明为最后一个chunk
{
free(a);
fclose(fp);
return 0;
}
fwrite(pStart,sizeof(char),nBytes,fp);//将nBytes长度的数据写入文件中
pStart=pStart+nBytes+2; //跳过一个块的数据以及数据之后两个字节的结束符
fflush(fp);
goto chunk; //goto到chunk继续处理
如何将一个十进制数转化为十六进制
char *buf = (char *)malloc(100);
char *d = buf;
int shift = 0;
unsigned long copy = 123445677;
while (copy) {
copy >>= 4;
shift++;
}//首先计算转化为十六进制后的位数
if (shift == 0)
shift++;
shift <<= 2; //将位数乘于4,如果有两位的话 shift为8
while (shift > 0) {
shift -= 4;
*(buf) = hex_chars[(123445677 >> shift) & 0x0F];
buf++;
}
*buf = '/0';