Linux内核同步机制之信号量与锁
作者:bullbat
Linux内核同步控制方法有很多,信号量、锁、原子量、RCU等等,不同的实现方法应用于不同的环境来提高操作系统效率。首先,看看我们最熟悉的两种机制——信号量、锁。
一、信号量
首先还是看看内核中是怎么实现的,内核中用struct semaphore数据结构表示信号量(<linux/semphone.h>中):
struct semaphore {
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
其中lock为自旋锁,放到这里是为了保护count的原子增减,无符号数count为我们竞争的信号量(PV操作的核心),wait_list为等待此信号量的进程链表。
初始化:
对于这一类工具类使用较多的机制,包括用于同步互斥的信号量、锁、completion,用于进程等待的等待队列、用于Per-CPU的变量等等,内核都提供了两种初始化方法,静态与动态方式。
1) 静态初始化,实现代码如下:
#define __SEMAPHORE_INITIALIZER(name, n) \
{ \
.lock = __SPIN_LOCK_UNLOCKED((name).lock), \
.count = n, \
.wait_list = LIST_HEAD_INIT((name).wait_list), \
}
#define DECLARE_MUTEX(name) \
struct semaphore name = __SEMAPHORE_INITIALIZER(name, 1)
可以看到,这种初始化使我们在编程的时候直接用一条语句DECLARE_MUTEX(name);就可以完成申明与初始化,另一种下面要说的动态初始化方式申请与初始化分离。
2) 我们看到,静态初始化时信号量的count值初始化为1,当我们需要初始化为0时需要用动态初始化方法。
#define init_MUTEX(sem) sema_init(sem, 1)
#define init_MUTEX_LOCKED(sem) sema_init(sem, 0)
static inline void sema_init(struct semaphore *sem, int val)
{
static struct lock_class_key __key;
*sem = (struct semaphore) __SEMAPHORE_INITIALIZER(*sem, val);
lockdep_init_map(&sem->lock.dep_map, "semaphore->lock", &__key, 0);
}
操作:
获取信号量
/*获取信号量*/
void down(struct semaphore *sem)
{
unsigned long flags;
spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
__down(sem);
spin_unlock_irqrestore(&sem->lock, flags);
}
__down(sem)最终由下面函数实现
static inline int __sched __down_common(struct semaphore *sem, long state,
long timeout)
{
struct task_struct *task = current;
struct semaphore_waiter waiter;
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = task;
waiter.up = 0;
for (;;) {
if (signal_pending_state(state, task))
goto interrupted;
if (timeout <= 0)
goto timed_out;
__set_task_state(task, state);
spin_unlock_irq(&sem->lock);
timeout = schedule_timeout(timeout);
spin_lock_irq(&sem->lock);
if (waiter.up)
return 0;
}
timed_out:
list_del(&waiter.list);
return -ETIME;
interrupted:
list_del(&waiter.list);
return -EINTR;
}
释放信号量
void up(struct semaphore *sem)
{
unsigned long flags;
spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;
else
__up(sem);
spin_unlock_irqrestore(&sem->lock, flags);
}
static noinline void __sched __up(struct semaphore *sem)
{
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
struct semaphore_waiter, list);
list_del(&waiter->list);
waiter->up = 1;
wake_up_process(waiter->task);
}
从上面代码可以看出,信号量的获取和释放很简单,不外乎修改count值、加入或移除等待队列元素,其中count值的修改需要自旋锁的支持。还有几个down和up类函数,实现类似,使用时可以看看源码不同之处。
运用:
用信号量我们实现两个线程的同步,我们用kernel_thread创建两个线程,对变量num的值进行同步访问,代码如下,文件为semaphore.c
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/sched.h>
#include <linux/semaphore.h>
#define N 15
MODULE_LICENSE("GPL");
static unsigned count=0,num=0;
struct semaphore sem_2;
DECLARE_MUTEX(sem_1);/*init 1*/
int ThreadFunc1(void *context)
{
char *tmp=(char*)context;
while(num<N){
down(&sem_1);
printk("<2>" "%s\tcount:%d\n",tmp,count++);
num++;
up(&sem_2);
}
return 0;
}
int ThreadFunc2(void *context)
{
char *tmp=(char*)context;
while(num<N){
down(&sem_2);
printk("<2>" "%s\tcount:%d\n",tmp,count--);
num++;
up(&sem_1);
}
return 0;
}
static __init int semaphore_init(void)
{
char *ch1="this is first thread!";
char *ch2="this is second thread!";
init_MUTEX_LOCKED(&sem_2);/*init 0*/
kernel_thread(ThreadFunc1,ch1,CLONE_KERNEL);
kernel_thread(ThreadFunc2,ch2,CLONE_KERNEL);
return 0;
}
static void semaphore_exit(void)
{
}
module_init(semaphore_init);
module_exit(semaphore_exit);
MODULE_AUTHOR("Mike Feng");
实现结果如下。
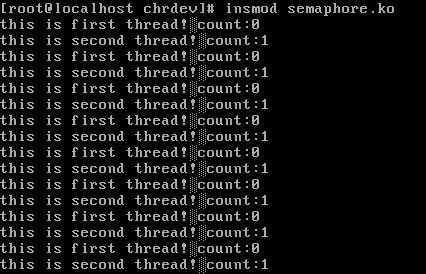
可以看到线程1和线程2交替运行,实现了同步。
读、写信号量:
类似操作系统中学习的读者、写者问题,内核中,许多任务可以划分为两种不同的工作类型:一些任务只需要读取受保护的数据结构,而其他的则必须做出修改。循序多个并发的读者是可能的,只要他们之中没有哪个要做出修改。Linux内核为这种情形提供了一种特殊的信号量类型——读、写信号量。struct rw_semaphore作为其数据结构,初始化和信号量类似,down_read、up_read等类函数实现信号量控制,这些函数实现比较复杂,用到了读写锁(将在后面分析),有兴趣可以看看,。我们运用读、写信号实现哪个古老的读者、写者同步问题:
文件down_read.c
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/sched.h>
#include <linux/rwsem.h>
#include <linux/semaphore.h>
MODULE_LICENSE("GPL");
static int count=0,num=0,readcount=0,writer=0;
struct rw_semaphore rw_write;
struct rw_semaphore rw_read;
struct semaphore sm_1;
int ThreadRead(void *context)
{
down_read(&rw_write);
down(&sm_1);
count++;
readcount++;
up(&sm_1);
printk("<2>" "Read Thread %d\tcount:%d\n",readcount,count);
msleep(10);
printk("<2>" "Read Thread Over!\n",readcount);
up_read(&rw_write);
return 0;
}
int ThreadWrite(void *context)
{
down_write(&rw_write);
writer++;
printk("<2>" "Write Thread %d\tcount:%d\n",writer,--count);
msleep(10);
printk("<2>" "Write Thread %d Over!\n",writer);
up_write(&rw_write);
return count;
}
static __init int rwsem_init(void)
{
static int i,iread=0,iwrite=0;
init_rwsem(&rw_read);
init_rwsem(&rw_write);
init_MUTEX(&sm_1);
for(i=0;i<2;i++){
kernel_thread(ThreadWrite,&i,CLONE_KERNEL);
iwrite++;
}
for(i=0;i<2;i++){
kernel_thread(ThreadRead,&i,CLONE_KERNEL);
iread++;
}
for(i=2;i<5;i++){
kernel_thread(ThreadRead,&i,CLONE_KERNEL);
iread++;
}
for(i=2;i<5;i++){
kernel_thread(ThreadWrite,&i,CLONE_KERNEL);
iwrite++;
}
return 0;
}
static void rwsem_exit(void)
{
}
module_init(rwsem_init);
module_exit(rwsem_exit);
MODULE_AUTHOR("Mike Feng");
实验结果:

从代码上看,实现起来很简单。
二、自旋锁
读写信号量基于自旋锁实现。内核中为如下结构:
typedef struct {
raw_spinlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAK
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} spinlock_t;
其中raw_lock为实现的原子量控制。下面我们就信号量和自旋锁实现我们上面用读写信号量实现的读者、写者问题:spinlock.c文件
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/sched.h>
#include <linux/semaphore.h>
#include <linux/spinlock.h>
MODULE_LICENSE("GPL");
static int count=0,num=0,readcount=0,writer=0,writecount=0;
struct semaphore sem_w,sem_r;
spinlock_t lock1=SPIN_LOCK_UNLOCKED;
int ThreadRead(void *context)
{
down(&sem_r);
spin_lock(&lock1);
readcount++;
if(readcount==1)
down(&sem_w);
spin_unlock(&lock1);
up(&sem_r);
printk("<2>" "Reader %d is reading!\n",readcount);
msleep(10);
printk("<2>" "Reader is over!\n");
spin_lock(&lock1);
readcount--;
if(readcount==0)
up(&sem_w);
spin_unlock(&lock1);
return count;
}
int ThreadWrite(void *context)
{
spin_lock(&lock1);
writecount++;
if(writecount==1)
down(&sem_r);
spin_unlock(&lock1);
down(&sem_w);
writer++;
printk("<2>" "Writer %d is writting!\n",writer);
msleep(10);
printk("<2>" "Writer %d is over!\n",writer);
up(&sem_w);
spin_lock(&lock1);
writecount--;
if(writecount==0)
up(&sem_r);
spin_unlock(&lock1);
return count;
}
static __init int rwsem_init(void)
{
static int i;
init_MUTEX(&sem_r);
init_MUTEX(&sem_w);
for(i=0;i<2;i++){
kernel_thread(ThreadWrite,&i,CLONE_VM);
}
for(i=0;i<2;i++){
kernel_thread(ThreadRead,&i,CLONE_KERNEL);
}
for(i=2;i<5;i++){
kernel_thread(ThreadRead,&i,CLONE_KERNEL);
}
for(i=2;i<5;i++){
kernel_thread(ThreadWrite,&i,CLONE_KERNEL);
}
return 0;
}
static void rwsem_exit(void)
{
}
module_init(rwsem_init);
module_exit(rwsem_exit);
MODULE_AUTHOR("Mike Feng");
运行结果:

从结果上看,和我们上面的结果略有差别,因为我们这里实现的是写者优先算法。
读写锁:
读写信号量的实现是基于读写锁的。可以想到他们的应用都差不多。自旋锁、读写锁中不能有睡眠,我们就不做实验验证了,当你在锁之间添加msleep函数时,会造成系统崩溃。
顺序锁:
顺序锁和读写锁非常相似,只是他为写者赋予了较高的优先级:事实上,即使在读者正在读的时候也允许写者继续运行。这种策略的好处是写者永远不会等待(除非另外一个写者正在写),缺点是有些时候读者不得不反复读相同数据直到他获得有效的副本。
最后,为完整起见,附上代码的Makefile文件:
obj-m+=semaphore.o down_read.o spinlock.o CURRENT:=$(shell pwd) KERNEL_PATH:=/usr/src/kernels/$(shell uname -r) all: make -C $(KERNEL_PATH) M=$(CURRENT) modules clean: make -C $(KERNEL_PATH) M=$(CURRENT) clean