Cloudeep对象存储系统简介(1)
Cloudeep 对象存储系统简介 -1
---- Adam
Cloudeep 团队在过去的一段时间,致力于开发一个类似 Amazon S3 ( http://aws.amazon.com/ )和 Google Storage ( http://code.google.com/apis/storage/docs/overview.html )的系统,为用户提供基于 REST 的,面向 Object 的云存储系统; Cloudeep 早期叙述过基于 Hadoop 的对象存储系统实现方法( http://blog.csdn.net/Cloudeep/archive/2009/08/05/4412958.aspx );
而 Cloudeep 的对象存储系统采用的是一种新的架构
关键字: Object Storage System 、 Amazon S3 、 Google Storage 、 Hadoop
Cloudeep 对象存储系统功能介绍
- 为互联网用户和企业用户提供大规模存储空间服务( PB 级以上的规模)
- 支持对象的写入,读取和删除,不支持对象的修改(Update和Append)
- 支持Bucket
- 可存储任意小于 5G 的对象(文件)
- 支持用户定义的元数据属性存储
- 支持Bucket内对象 ID 的字典序操作
- 对象支持 ACL 访问控制
- 高扩展性,系统支持在线无缝扩容
- 高可用性,支持尽可能的在线服务能力,支持多副本控制和修复
- 数据的最终一致性
- 支持 REST 访问接口
- 支持历史版本恢复(新)
2 , Cloudeep 对象存储系统的架构简介
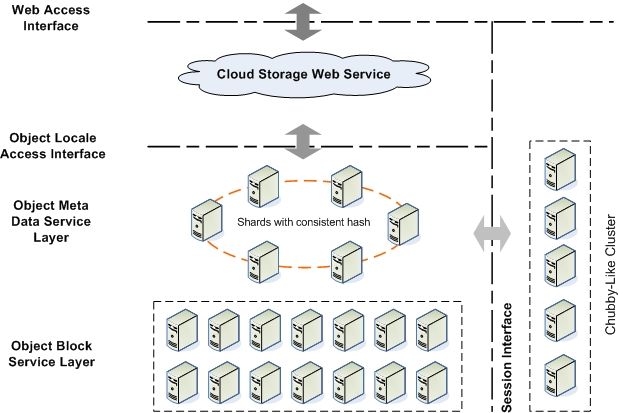
图 1 Cloudeep 简单对象存储系统架构
- Object Meta Data Service Layer :主要执行存储对象的元数据信息;对象切块后的数据存储位置信息;切块后数据存储位置调度;数据副本修复;数据健康状况监测;
- Object Block Service Layer :主要执行对象切块数据的存储和维护;数据副本拷贝迁移;
- Chubby-Like Cluster :为系统提供网络环境信息服务(拓扑服务,事件通知服务),底粒度锁服务;
- Cloud Storage Web Service :提供对象的 Internet 访问接口
3 ,基于 Hadoop 实现对象存储的补充说明
( http://blog.csdn.net/Cloudeep/archive/2009/08/05/4412958.aspx )
- 系统可用性不高:在 HDFS 层存在 NameNode 的单点问题; Bigtable 的元数据层容易出现局部 Range 不能服务的情况( Range 的 Takeover 需要时间);
- 系统复杂度过高:在该方案中,子系统太多,包还 HDFS , HBase , Mapreduce 等等,系统过于复杂,不利于部署和维护;
- 系统的消息开销太大:系统中 HDFS 是为大文件设计的,其消息流程不适合小对象存储,开销太大,效率低;
- 系统层次太多:访问一个对象,涉及 HBase 元数据访问、 HDFS 的文件系统 NameNode 的访问、 DataNode 访问,效率低下;
- . . .