不同字面量硬解析次数剧增的解决方案
最常用的解决方案是:预备语句、客户端缓存、共享游标和服务端缓存
快速解析
使用预备语句
当一条SQL 语句因为不停变换字面量而引起解析问题时,首先要做的事倩就是用绑定变量替换掉字面量。为此,必须使用预备语句。使用它的目的是让所有SQL 语句共享单个游标.从而避免不必要的硬解析。图8 一2 展示的这个处理过程目的是改进测试用例1 的性能。
注意下图所示的处理过程将在随后被测试用例2 采用.
由于这项改进,在下图中可以看到,与测试用例1相比响应时间大约下降了41%。这是使用新代码所期待的结果。借助于预备语句,只进行了一次硬解析。因此,得以避免测试用例1 中数据库引擎进行的大部分处理过程。不过要注意,仍然进行了10000 次软解析。

重用预备语句
在上一节中建议使用预备语句,这样做很有益。要能够重用它们就更是锦卜添花了,因为这样不仅可以消除硬解析,而且也可以消除软解析。既然在测试用例2中花在解析上的时间己经很少了,你或许会问为什么还要重用预备语句。在给出答案之前,我将给出与重用单个预备语句有关的性能数据。具体地,下图展示了这个诣在改进测试用例2 性能的处理流程。
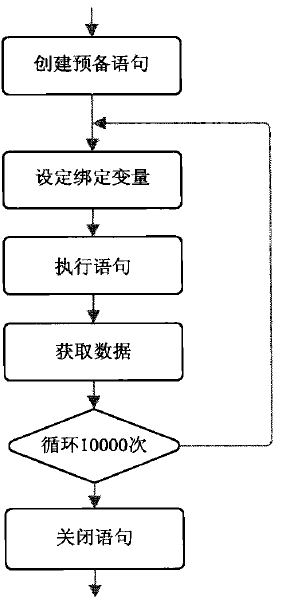
由于这项改进,在下图中可以看到,新的响应时间比测试用例l 和测试用例2 分别下降了61%和33%。值得注意的是,真正的差距并不是由解析消耗的CPU 时间减少所致(此时间在测试用例2 中己经很少了),而是因为等待SQL *Net message from Client的时间缩短了。这意味你在网络传输或客户端处理上节省了资源,亦或两者皆有。
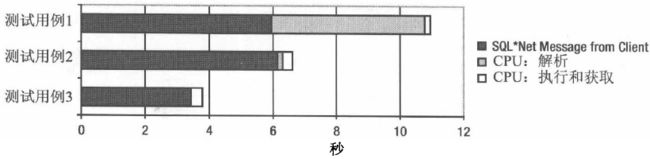
在测试用例2 中,数据库层的软解析处理持续了约1/10 秒。问题是,这种改进来自于何处呢?可以确定它们不是来自于数据库层资源使用的减少。或许你直觉上认为它得益于客户端和数据库端交互次数的减少。然而,通过观察等待SQL*Net message from Client 和SQL *Net message to client 的数目可以发现并非如此,三个测试用例中的数目都是相同的,每个都是10000 次往返。这并不是偶然的,因为正好有10000 次执行(execution )操作,这意味着在这个特定的例子中,解析(parse)、执行(execut)和获取(fetch)调用被客户端驱动打包成了一个单独的SQL*Net信息。然而因为在客户端和数据库端发送信息的大小不同,造成在网络层还是有一些区别。
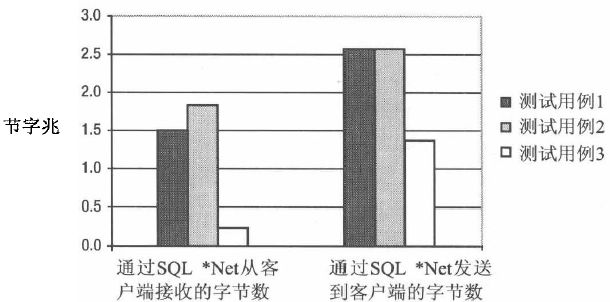
下图展示了三个测试用例的数据传输量。注意到预备语句略微增加了数据库引擎接收的信息量这很重要。而最重要的不同则是测试用例3 和其他两个比起来,无论是数据库引擎接收还是发送的信息量都显著地减小了。这是由于打开和关闭一个新游标会造成通过网络传输的数据量不同(比如,在测试用例3 中,SQL 语句的内容仅需要通过网络传输一次)。
客户端语句缓存
这个特性被设计用来解决应用程序造成的一些性能问题,具体是应用程序由子不必要地打开和关闭游标而带来大量的软解析。在本章的前面,这个问题在测试用例2中揭示过。
客户端语句缓存(Client_Side Statement Caching)的概念很简单。撼当应用程序关闭一个游标时,不去真正关闭它,而是由客户端的数据库层(由它负责与数据库引擎进行通讯)保持它的开启并将它添加到缓存中。然后,如果再有一个基于相同SQL 语句的游标需要被打开和解析,就不需要真正得打开和解析它,而是重用先前缓存了的游标。因此,软解析就不会发生了。基本上,要达到的目的是,即使像测试用例2 那样写语句,也要达到测试用例3 的性能。
为了利用这个特性,通常只需要启用它并定义每个会话可缓存的最大游标数即可。注意,当缓存的游标数达到上限,最近最少使用的游标将被新游标替换掉。可以在应用程序中添加一些初始化代码或在环境中设置一个变量来激活此类特性。
长解析
游标共享
这个特性被设计用来应对那些不恰当地使用了字面量而没有使用绑定变量的应用程序造成的问题,这样会导致大量的硬解析,因为是字面量而不是绑定变量在发挥作用。
游标共享(cursor_sharing )的概念很简单。如果一个应用程序执行包含字面量的SQL 语句,数据库引擎将自动使用绑定变量替换掉字面量。不过要注意,那些已经含有至少一个绑定变量的SQL 语句将不被替换。游标共享由动态初始化参数cursor_sharing来控制。如果它设置为exact ,这个特性就会被禁用。换句话说,这时只有那些文本完全相同的SQL 语句共享它们的父游标。如果cursor_sharing 设置为force 或similar,这个特性将被启用。它的默认值为exact 。你可以在系统级或会话级修改它,也可以通过指定提示cursor_sharing_exact在SQL 语句级直接禁用游标共享特性。
既然游标共享可以通过设置为两个值来启用,即force 和similar ,那我们就来看看这两个参数值之间有什么不同。为此,我们将初始化参数cursor_sharing 分别设置为它的三个值,在每种情况下执行测试用例1 一次。
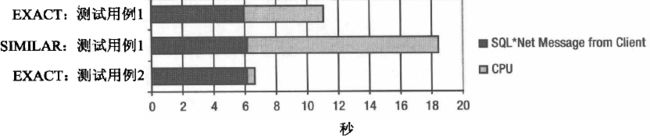
让我们来看看设为force 时得到的结果。如下图 所示,此时,测试用例1 在数据库端的资源使用概要情况(参数设为force 时)和参数设为exact 的测试用例2 的情况相差无几。实际上,它们都执行了1 次硬解析和1 0000 次软解析。因此,多亏了游标共享,解析时间被大大削减了。通过使用参数force , 测试用例1 只比测试用例2 在CPU 开销上稍微多一点。既然数据库引擎必须为了把字面量替换为绑定变量而多执行一些操作,稍多出一点开销也是意料之中的。
与参数设置为force 相关的问题是单个子游标将用于所有替换掉字面量后文本相同的SQL 语句。所以,字面量(它对直方图的使用至关重要)只在首个提交的SQL 语句产生执行计划时窥测一次。自然地,这可能导致随后执行的SQL 语句产生非最优的执行计划,因为后续的SQL 语句使用的字面量会导致生成不同的执行计划?。为了避免这个问题,可以将参数设置为引similar 。事实上,数据库引擎在重用一个己有的游标之前,将检查被替换的字面量是否有相关的直方图存在。如果直方图存在,就根据它创建一个新的子游标。如果不存在,就使用己有的子游标。
下面是参数设置为similar 时得到的结果。注意,所有的测试都是在直方图存在的条件下完成的。如下图 所示,在值为similar 的情况下,测试用例1 中数据库端资源使用概要的情祝比它在exact 的情况下更差。产生这个问题是因为在这种情况下设置游标共享,不仅要进行10000 次硬解析,而且每次解析的CPU 开销也更大了。还要注意,在替换字面量之后,这里所有的SQL 语句都拥有相同的文本。因此,在库缓存中有一个父游标,它有很多,在本例中是几千个子游标。
概括起来,如果应用程序使用字面量,并且游标共享参数设置为similar,那么它的行为将取决于是否有相关的直方图存在。如果存在,使用Similar时的行为将和exact的情况类似。如果不存在,similar的行为将和force的情况类似。这意味着如果你在这种情况下遇到解析问题,通常是因为漫无目的地使用similar造成。最后有实例来证明。
服务器端语句缓存
这个特性和客户端语句缓存技术类似,因为它是设计用来在有太多软解析发生时降低开销的。从概念的角度来看,这两种类型的语句缓存也是类似的,除了本特性是在服务器端实现。从性能的角度来看,它们的区别就相当大了。事实上,服务器端的实现远没有客户端的实现那么强大。这是因为服务器端的实现只能减少服务器端软解析的开销。在大多数环境下,客户端的软解析开销都比服务器端的大很多。服务器端实现的仅有的真正优点是它可以缓存在PL/SQL 中执行的SQL 语句,或者缓存部署在数据库引擎中的Java 代码。
如果一个应用程序执行了大量的软解析,同时库缓存门锁(library cache latche )和互斥量(mutexes ) 上的高压力也会导致数据库引擎发生显著的争用。以下的数据库端资源使用概要展示了这样的情况。注意,为了产生它,测试用例2在数据库引擎侮秒处理20000 次相同SQL语句解析的情况下启动。虽然这肯定不是一个常见的工作负载,但可以帮助演示服务器端游标缓存的影响。
服务器端语句缓存是通过初始化参数Session_cached_cursors 配置的。它指定每个会话可缓存游标数的最大值。如果参数设置为O ,此特性就被禁用,随之如果它被设置为一个大于O 的值,此特性便被启用。直到oraclel 10gR1,它的默认值都为0;在Oracle 10gR2 中,它的默认值为20 ;而在oracle 11g 中,它的默认值为50 。在系统级,要修改它必须重启实例。在会话级,此参数可以被动态修改。就和客户端语句缓存一样,为了决定缓存游标的最大值是多少,需要了解正在使用的具体应用程序。如果不了解,就需要分析TKPROF 或 TVD$XTAT的输出文件以得知有多少SQL 语句正在遭遇大量的软解析。接着,基于第一步的评估,还必须做一些测试以检验这个值是否合适。在做测试期间,可以查询得到一些统计数据,通过观察这些数据验证缓存的有效性。注意,在系统级也可以使用同样的统计信息。无论如何,需要注意那个在出问题的负载下工作的会话,以寻求有意义的线索。
首先,比较实际缓存游标的数目(session cursor cache count )和初始化参数sesslon_cached_cursors 设定的值。如果前者小于后者,意味着增加初始化参数的设定值对实际缓存游标的数量不会产生什么影响。否则;如果前者等于后者,增加初始化参数的设定值有可能使更多的游标被缓存。但无论如何,把参数设为超过初始化参数open_cursors 的值都是没有意义的。举个例子,根据前面的统计,在当前缓存中有9 个游标。既然测试期间初始化参数sesslon_cached_cursors 被设定为20 ,再增加也是没什么效果的。
其次.使用其他数据,可以检测相对于总解析次数(parse count(total))有多少次解析(sesslon cursor cache hits)因为缓存游标被优化。如果这两个值很接近,也许就没有必要增加缓存的数目。在前面例子的统计中,超过99 % ( 9997 / 10008 )的解析因为缓存而避免,所以再增加缓存是没有价值的。
注意到在前例中“只有”9997 次缓存命中,这一点也很重要。既然测试用例2 执行了10000 次相同的SQL 语句,为什么不是命中9999 次呢?答案是因为只有当个游标执行了3 次以后,它才会被放进游标缓存中。这样做是为了避免缓存那些只执行了1 次的游标。只有在语句第次解析前己经有共享游标缓存在库缓存时,才可能命中9999 次。
概括起来,服务器端语句缓存是个重要的特性。事实上,如果大小设置得当,它确实可以帮助节省一些服务器端的资源开销。然而,即使有这样的特性可用,在一开始时应用程序还是要适当地管理游标,特别是因为,如你已经见到的那样,客户端的解析开销可能比服务器端的更大。
下面举例来说明:如果应用程序使用字面量,并且游标共享参数设置为similar,那么它的行为将取决于是否有相关的直方图存在。如果存在,使用Similar时的行为将和exact的情况类似。如果不存在,similar的行为将和force的情况类似。
SQL> alter session set cursor_sharing = similar;
Session altered.
SQL> select name,value from v$sysstat where name like '%parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4948
parse time elapsed 4468
parse count (total) 170148
parse count (hard) 1619 (硬分析次数)
parse count (failures) 80
SQL> select count(*) from t where object_id = 1000;
COUNT(*)
----------
0
SQL> select name,value from v$sysstat where name like '%parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4948
parse time elapsed 4468
parse count (total) 170172
parse count (hard) 1620
parse count (failures) 80
SQL> /
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4948
parse time elapsed 4468
parse count (total) 170176
parse count (hard) 1620
parse count (failures) 80
SQL> select count(*) from t where object_id = 1000;
COUNT(*)
----------
0
SQL> select name,value from v$sysstat where name like '%parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4948
parse time elapsed 4468
parse count (total) 170178
parse count (hard) 1620
parse count (failures) 80
SQL> select count(*) from t where object_id = 1001;
COUNT(*)
----------
0
SQL> select name,value from v$sysstat where name like '%parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4948
parse time elapsed 4468
parse count (total) 170180
parse count (hard) 1620(即使object_id发生变化依然没有硬解析)
parse count (failures) 80
我们再来看分析表和字段信息后的表现
SQL> analyze table t1 compute statistics for table for columns object_id;
Table analyzed.
SQL> select name,value from v$sysstat where name like '%parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4973
parse time elapsed 4495
parse count (total) 170982
parse count (hard) 1640
parse count (failures) 80
SQL> select count(*) from t1 where object_id = 5000;
COUNT(*)
----------
0
SQL> select name,value from v$sysstat where name like '%parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4973
parse time elapsed 4495
parse count (total) 170984
parse count (hard) 1641
parse count (failures) 80
SQL> select count(*) from t1 where object_id = 5000;
COUNT(*)
----------
0
SQL> select name,value from v$sysstat where name like '%parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4973
parse time elapsed 4495
parse count (total) 171008
parse count (hard) 1641 (重复执行没发生变化)
parse count (failures) 80
SQL> select count(*) from t1 where object_id = 5001;
COUNT(*)
----------
0
SQL> select name,value from v$sysstat where name like '%parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 4973
parse time elapsed 4495
parse count (total) 171010
parse count (hard) 1642 (当object_id变化的时候产生硬分析)
parse count (failures) 80
SQL> select sql_text,child_number from v$sql where sql_text like 'select count(*) from t1 where%';
SQL_TEXT CHILD_NUMBER
------------------------------------------------------------------------ -------------------------------
select count(*) from t1 where object_id = :"SYS_B_0" 0
select count(*) from t1 where object_id = :"SYS_B_0" 1