多线程原理分析面试题理解
系列前言
本系列是本人参加微软亚洲研究院,腾讯研究院,迅雷面试时整理的,另外也加入一些其它IT公司如百度,阿里巴巴的笔试面试题目,因此具有很强的针对性。系列中不但会详细讲解多线程同步互斥的各种“招式”,而且会进一步的讲解多线程同步互斥的“内功心法”。有了“招式”和“内功心法”,相信你也能对多线程挥洒自如,在笔试面试中顺利的秒杀多线程试题。
-------------------------------------华丽的分割线---------------------------------------
第一篇 多线程笔试面试题汇总
多线程在笔试面试中经常出现,下面列出一些公司的多线程笔试面试题。首先是一些概念性的问答题,这些是多线程的基础知识,经常出现在面试中的第一轮面试(我参加2011年腾讯研究院实习生招聘时就被问到了几个概念性题目)。然后是一些选择题,这些一般在笔试时出现,虽然不是太难,但如果在选择题上花费大多时间无疑会对后面的编程题造成影响,因此必须迅速的解决掉。最后是综合题即难一些的问答题或是编程题。这种题目当然是最难解决了,要么会引来面试官的追问,要么就很容易考虑不周全,因此解决这类题目时一定要考虑全面和细致。
下面就来看看这三类题目吧。
一.概念性问答题
第一题:线程的基本概念、线程的基本状态及状态之间的关系?
第二题:线程与进程的区别?
这个题目问到的概率相当大,计算机专业考研中也常常考到。要想全部答出比较难。
第三题:多线程有几种实现方法,都是什么?
第四题:多线程同步和互斥有几种实现方法,都是什么?
我在参加2011年迅雷校园招聘时的一面和二面都被问到这个题目,回答的好将会给面试成绩加不少分。
第五题:多线程同步和互斥有何异同,在什么情况下分别使用他们?举例说明。
二.选择题
第一题(百度笔试题):
以下多线程对int型变量x的操作,哪几个不需要进行同步:
A. x=y; B. x++; C. ++x; D. x=1;
第二题(阿里巴巴笔试题)
多线程中栈与堆是公有的还是私有的
A:栈公有, 堆私有
B:栈公有,堆公有
C:栈私有, 堆公有
D:栈私有,堆私有
三.综合题
第一题(台湾某杀毒软件公司面试题):
在Windows编程中互斥量与临界区比较类似,请分析一下二者的主要区别。
第二题:
一个全局变量tally,两个线程并发执行(代码段都是ThreadProc),问两个线程都结束后,tally取值范围。
inttally = 0;//glable
voidThreadProc()
{
for(inti = 1; i <= 50; i++)
tally += 1;
}
第三题(某培训机构的练习题):
子线程循环 10 次,接着主线程循环 100 次,接着又回到子线程循环 10 次,接着再回到主线程又循环 100 次,如此循环50次,试写出代码。
第四题(迅雷笔试题):
编写一个程序,开启3个线程,这3个线程的ID分别为A、B、C,每个线程将自己的ID在屏幕上打印10遍,要求输出结果必须按ABC的顺序显示;如:ABCABC….依次递推。
第五题(Google面试题)
有四个线程1、2、3、4。线程1的功能就是输出1,线程2的功能就是输出2,以此类推.........现在有四个文件ABCD。初始都为空。现要让四个文件呈如下格式:
A:1 2 3 4 1 2....
B:2 3 4 1 2 3....
C:3 4 1 2 3 4....
D:4 1 2 3 4 1....
请设计程序。
下面的第六题与第七题也是在考研中或是程序员和软件设计师认证考试中的热门试题。
第六题
生产者消费者问题
这是一个非常经典的多线程题目,题目大意如下:有一个生产者在生产产品,这些产品将提供给若干个消费者去消费,为了使生产者和消费者能并发执行,在两者之间设置一个有多个缓冲区的缓冲池,生产者将它生产的产品放入一个缓冲区中,消费者可以从缓冲区中取走产品进行消费,所有生产者和消费者都是异步方式运行的,但它们必须保持同步,即不允许消费者到一个空的缓冲区中取产品,也不允许生产者向一个已经装满产品且尚未被取走的缓冲区中投放产品。
第七题
读者写者问题
这也是一个非常经典的多线程题目,题目大意如下:有一个写者很多读者,多个读者可以同时读文件,但写者在写文件时不允许有读者在读文件,同样有读者读时写者也不能写。
多线程相关题目就列举到此,如果各位有多线程方面的笔试面试题,欢迎提供给我,我将及时补上。谢谢大家。
下一篇《多线程第一次亲密接触 CreateThread与_beginthreadex本质区别》将从源代码的层次上讲解创建多线程的二个函数CreateThread与_beginthreadex到底有什么区别,让你明明白白的完成与多线程第一次亲密接触。
转载请标明出处,原文地址:http://blog.csdn.net/morewindows/article/details/7392749
本系列后面还有十多篇文章将发布,建议收藏本系列以便及时获知。
秒杀多线程第二篇 多线程第一次亲密接触 CreateThread与_beginthreadex本质区别
本文将带领你与多线程作第一次亲密接触,并深入分析CreateThread与_beginthreadex的本质区别,相信阅读本文后你能轻松的使用多线程并能流畅准确的回答CreateThread与_beginthreadex到底有什么区别,在实际的编程中到底应该使用CreateThread还是_beginthreadex?
使用多线程其实是非常容易的,下面这个程序的主线程会创建了一个子线程并等待其运行完毕,子线程就输出它的线程ID号然后输出一句经典名言——Hello World。整个程序的代码非常简短,只有区区几行。
- //最简单的创建多线程实例
- #include <stdio.h>
- #include <windows.h>
- //子线程函数
- DWORD WINAPI ThreadFun(LPVOID pM)
- {
- printf("子线程的线程ID号为:%d\n子线程输出Hello World\n", GetCurrentThreadId());
- return 0;
- }
- //主函数,所谓主函数其实就是主线程执行的函数。
- int main()
- {
- printf(" 最简单的创建多线程实例\n");
- printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
- HANDLE handle = CreateThread(NULL, 0, ThreadFun, NULL, 0, NULL);
- WaitForSingleObject(handle, INFINITE);
- return 0;
- }
运行结果如下所示:

下面来细讲下代码中的一些函数
第一个 CreateThread
函数功能:创建线程
函数原型:
HANDLEWINAPICreateThread(
LPSECURITY_ATTRIBUTESlpThreadAttributes,
SIZE_TdwStackSize,
LPTHREAD_START_ROUTINElpStartAddress,
LPVOIDlpParameter,
DWORDdwCreationFlags,
LPDWORDlpThreadId
);
函数说明:
第一个参数表示线程内核对象的安全属性,一般传入NULL表示使用默认设置。
第二个参数表示线程栈空间大小。传入0表示使用默认大小(1MB)。
第三个参数表示新线程所执行的线程函数地址,多个线程可以使用同一个函数地址。
第四个参数是传给线程函数的参数。
第五个参数指定额外的标志来控制线程的创建,为0表示线程创建之后立即就可以进行调度,如果为CREATE_SUSPENDED则表示线程创建后暂停运行,这样它就无法调度,直到调用ResumeThread()。
第六个参数将返回线程的ID号,传入NULL表示不需要返回该线程ID号。
函数返回值:
成功返回新线程的句柄,失败返回NULL。
第二个 WaitForSingleObject
函数功能:等待函数 – 使线程进入等待状态,直到指定的内核对象被触发。
函数原形:
DWORDWINAPIWaitForSingleObject(
HANDLEhHandle,
DWORDdwMilliseconds
);
函数说明:
第一个参数为要等待的内核对象。
第二个参数为最长等待的时间,以毫秒为单位,如传入5000就表示5秒,传入0就立即返回,传入INFINITE表示无限等待。
因为线程的句柄在线程运行时是未触发的,线程结束运行,句柄处于触发状态。所以可以用WaitForSingleObject()来等待一个线程结束运行。
函数返回值:
在指定的时间内对象被触发,函数返回WAIT_OBJECT_0。超过最长等待时间对象仍未被触发返回WAIT_TIMEOUT。传入参数有错误将返回WAIT_FAILED
CreateThread()函数是Windows提供的API接口,在C/C++语言另有一个创建线程的函数_beginthreadex(),在很多书上(包括《Windows核心编程》)提到过尽量使用_beginthreadex()来代替使用CreateThread(),这是为什么了?下面就来探索与发现它们的区别吧。
首先要从标准C运行库与多线程的矛盾说起,标准C运行库在1970年被实现了,由于当时没任何一个操作系统提供对多线程的支持。因此编写标准C运行库的程序员根本没考虑多线程程序使用标准C运行库的情况。比如标准C运行库的全局变量errno。很多运行库中的函数在出错时会将错误代号赋值给这个全局变量,这样可以方便调试。但如果有这样的一个代码片段:
- if (system("notepad.exe readme.txt") == -1)
- {
- switch(errno)
- {
- ...//错误处理代码
- }
- }
假设某个线程A在执行上面的代码,该线程在调用system()之后且尚未调用switch()语句时另外一个线程B启动了,这个线程B也调用了标准C运行库的函数,不幸的是这个函数执行出错了并将错误代号写入全局变量errno中。这样线程A一旦开始执行switch()语句时,它将访问一个被B线程改动了的errno。这种情况必须要加以避免!因为不单单是这一个变量会出问题,其它像strerror()、strtok()、tmpnam()、gmtime()、asctime()等函数也会遇到这种由多个线程访问修改导致的数据覆盖问题。
为了解决这个问题,Windows操作系统提供了这样的一种解决方案——每个线程都将拥有自己专用的一块内存区域来供标准C运行库中所有有需要的函数使用。而且这块内存区域的创建就是由C/C++运行库函数_beginthreadex()来负责的。下面列出_beginthreadex()函数的源代码(我在这份代码中增加了一些注释)以便读者更好的理解_beginthreadex()函数与CreateThread()函数的区别。
- //_beginthreadex源码整理By MoreWindows( http://blog.csdn.net/MoreWindows )
- _MCRTIMP uintptr_t __cdecl _beginthreadex(
- void *security,
- unsigned stacksize,
- unsigned (__CLR_OR_STD_CALL * initialcode) (void *),
- void * argument,
- unsigned createflag,
- unsigned *thrdaddr
- )
- {
- _ptiddata ptd; //pointer to per-thread data 见注1
- uintptr_t thdl; //thread handle 线程句柄
- unsigned long err = 0L; //Return from GetLastError()
- unsigned dummyid; //dummy returned thread ID 线程ID号
- // validation section 检查initialcode是否为NULL
- _VALIDATE_RETURN(initialcode != NULL, EINVAL, 0);
- //Initialize FlsGetValue function pointer
- __set_flsgetvalue();
- //Allocate and initialize a per-thread data structure for the to-be-created thread.
- //相当于new一个_tiddata结构,并赋给_ptiddata指针。
- if ( (ptd = (_ptiddata)_calloc_crt(1, sizeof(struct _tiddata))) == NULL )
- goto error_return;
- // Initialize the per-thread data
- //初始化线程的_tiddata块即CRT数据区域 见注2
- _initptd(ptd, _getptd()->ptlocinfo);
- //设置_tiddata结构中的其它数据,这样这块_tiddata块就与线程联系在一起了。
- ptd->_initaddr = (void *) initialcode; //线程函数地址
- ptd->_initarg = argument; //传入的线程参数
- ptd->_thandle = (uintptr_t)(-1);
- #if defined (_M_CEE) || defined (MRTDLL)
- if(!_getdomain(&(ptd->__initDomain))) //见注3
- {
- goto error_return;
- }
- #endif // defined (_M_CEE) || defined (MRTDLL)
- // Make sure non-NULL thrdaddr is passed to CreateThread
- if ( thrdaddr == NULL )//判断是否需要返回线程ID号
- thrdaddr = &dummyid;
- // Create the new thread using the parameters supplied by the caller.
- //_beginthreadex()最终还是会调用CreateThread()来向系统申请创建线程
- if ( (thdl = (uintptr_t)CreateThread(
- (LPSECURITY_ATTRIBUTES)security,
- stacksize,
- _threadstartex,
- (LPVOID)ptd,
- createflag,
- (LPDWORD)thrdaddr))
- == (uintptr_t)0 )
- {
- err = GetLastError();
- goto error_return;
- }
- //Good return
- return(thdl); //线程创建成功,返回新线程的句柄.
- //Error return
- error_return:
- //Either ptd is NULL, or it points to the no-longer-necessary block
- //calloc-ed for the _tiddata struct which should now be freed up.
- //回收由_calloc_crt()申请的_tiddata块
- _free_crt(ptd);
- // Map the error, if necessary.
- // Note: this routine returns 0 for failure, just like the Win32
- // API CreateThread, but _beginthread() returns -1 for failure.
- //校正错误代号(可以调用GetLastError()得到错误代号)
- if ( err != 0L )
- _dosmaperr(err);
- return( (uintptr_t)0 ); //返回值为NULL的效句柄
- }
讲解下部分代码:
注1._ptiddataptd;中的_ptiddata是个结构体指针。在mtdll.h文件被定义:
typedefstruct_tiddata * _ptiddata
微软对它的注释为Structure for each thread's data。这是一个非常大的结构体,有很多成员。本文由于篇幅所限就不列出来了。
注2._initptd(ptd, _getptd()->ptlocinfo);微软对这一句代码中的getptd()的说明为:
/* return address of per-thread CRT data */
_ptiddata __cdecl_getptd(void);
对_initptd()说明如下:
/* initialize a per-thread CRT data block */
void__cdecl_initptd(_Inout_ _ptiddata _Ptd,_In_opt_ pthreadlocinfo _Locale);
注释中的CRT (C Runtime Library)即标准C运行库。
注3.if(!_getdomain(&(ptd->__initDomain)))中的_getdomain()函数代码可以在thread.c文件中找到,其主要功能是初始化COM环境。
由上面的源代码可知,_beginthreadex()函数在创建新线程时会分配并初始化一个_tiddata块。这个_tiddata块自然是用来存放一些需要线程独享的数据。事实上新线程运行时会首先将_tiddata块与自己进一步关联起来。然后新线程调用标准C运行库函数如strtok()时就会先取得_tiddata块的地址再将需要保护的数据存入_tiddata块中。这样每个线程就只会访问和修改自己的数据而不会去篡改其它线程的数据了。因此,如果在代码中有使用标准C运行库中的函数时,尽量使用_beginthreadex()来代替CreateThread()。相信阅读到这里时,你会对这句简短的话有个非常深刻的印象,如果有面试官问起,你也可以流畅准确的回答了^_^。
接下来,类似于上面的程序用CreateThread()创建输出“Hello World”的子线程,下面使用_beginthreadex()来创建多个子线程:
- //创建多子个线程实例
- #include <stdio.h>
- #include <process.h>
- #include <windows.h>
- //子线程函数
- unsigned int __stdcall ThreadFun(PVOID pM)
- {
- printf("线程ID号为%4d的子线程说:Hello World\n", GetCurrentThreadId());
- return 0;
- }
- //主函数,所谓主函数其实就是主线程执行的函数。
- int main()
- {
- printf(" 创建多个子线程实例 \n");
- printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
- const int THREAD_NUM = 5;
- HANDLE handle[THREAD_NUM];
- for (int i = 0; i < THREAD_NUM; i++)
- handle[i] = (HANDLE)_beginthreadex(NULL, 0, ThreadFun, NULL, 0, NULL);
- WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
- return 0;
- }
运行结果如下:

图中每个子线程说的都是同一句话,不太好看。能不能来一个线程报数功能,即第一个子线程输出1,第二个子线程输出2,第三个子线程输出3,……。要实现这个功能似乎非常简单——每个子线程对一个全局变量进行递增并输出就可以了。代码如下:
- //子线程报数
- #include <stdio.h>
- #include <process.h>
- #include <windows.h>
- int g_nCount;
- //子线程函数
- unsigned int __stdcall ThreadFun(PVOID pM)
- {
- g_nCount++;
- printf("线程ID号为%4d的子线程报数%d\n", GetCurrentThreadId(), g_nCount);
- return 0;
- }
- //主函数,所谓主函数其实就是主线程执行的函数。
- int main()
- {
- printf(" 子线程报数 \n");
- printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
- const int THREAD_NUM = 10;
- HANDLE handle[THREAD_NUM];
- g_nCount = 0;
- for (int i = 0; i < THREAD_NUM; i++)
- handle[i] = (HANDLE)_beginthreadex(NULL, 0, ThreadFun, NULL, 0, NULL);
- WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
- return 0;
- }
对一次运行结果截图如下:

显示结果从1数到10,看起来好象没有问题。
答案是不对的,虽然这种做法在逻辑上是正确的,但在多线程环境下这样做是会产生严重的问题,下一篇《秒杀多线程第三篇 原子操作 Interlocked系列函数》将为你演示错误的结果(可能非常出人意料)并解释产生这个结果的详细原因。
秒杀多线程第三篇 原子操作 Interlocked系列函数
上一篇《多线程第一次亲密接触 CreateThread与_beginthreadex本质区别》中讲到一个多线程报数功能。为了描述方便和代码简洁起见,我们可以只输出最后的报数结果来观察程序是否运行出错。这也非常类似于统计一个网站每天有多少用户登录,每个用户登录用一个线程模拟,线程运行时会将一个表示计数的变量递增。程序在最后输出计数的值表示有今天多少个用户登录,如果这个值不等于我们启动的线程个数,那显然说明这个程序是有问题的。整个程序代码如下:
- #include <stdio.h>
- #include <process.h>
- #include <windows.h>
- volatile long g_nLoginCount; //登录次数
- unsigned int __stdcall Fun(void *pPM); //线程函数
- const int THREAD_NUM = 10; //启动线程数
- unsigned int __stdcall ThreadFun(void *pPM)
- {
- Sleep(100); //some work should to do
- g_nLoginCount++;
- Sleep(50);
- return 0;
- }
- int main()
- {
- g_nLoginCount = 0;
- HANDLE handle[THREAD_NUM];
- for (int i = 0; i < THREAD_NUM; i++)
- handle[i] = (HANDLE)_beginthreadex(NULL, 0, ThreadFun, NULL, 0, NULL);
- WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
- printf("有%d个用户登录后记录结果是%d\n", THREAD_NUM, g_nLoginCount);
- return 0;
- }
程序中模拟的是10个用户登录,程序将输出结果:

和上一篇的线程报数程序一样,程序输出的结果好象并没什么问题。下面我们增加点用户来试试,现在模拟50个用户登录,为了便于观察结果,在程序中将50个用户登录过程重复20次,代码如下:
- #include <stdio.h>
- #include <windows.h>
- volatile long g_nLoginCount; //登录次数
- unsigned int __stdcall Fun(void *pPM); //线程函数
- const DWORD THREAD_NUM = 50;//启动线程数
- DWORD WINAPI ThreadFun(void *pPM)
- {
- Sleep(100); //some work should to do
- g_nLoginCount++;
- Sleep(50);
- return 0;
- }
- int main()
- {
- printf(" 原子操作 Interlocked系列函数的使用\n");
- printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
- //重复20次以便观察多线程访问同一资源时导致的冲突
- int num= 20;
- while (num--)
- {
- g_nLoginCount = 0;
- int i;
- HANDLE handle[THREAD_NUM];
- for (i = 0; i < THREAD_NUM; i++)
- handle[i] = CreateThread(NULL, 0, ThreadFun, NULL, 0, NULL);
- WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
- printf("有%d个用户登录后记录结果是%d\n", THREAD_NUM, g_nLoginCount);
- }
- return 0;
- }
运行结果如下图:

现在结果水落石出,明明有50个线程执行了g_nLoginCount++;操作,但结果输出是不确定的,有可能为50,但也有可能小于50。
要解决这个问题,我们就分析下g_nLoginCount++;操作。在VC6.0编译器对g_nLoginCount++;这一语句打个断点,再按F5进入调试状态,然后按下Debug工具栏的Disassembly按钮,这样就出现了汇编代码窗口。可以发现在C/C++语言中一条简单的自增语句其实是由三条汇编代码组成的,如下图所示。

讲解下这三条汇编意思:
第一条汇编将g_nLoginCount的值从内存中读取到寄存器eax中。
第二条汇编将寄存器eax中的值与1相加,计算结果仍存入寄存器eax中。
第三条汇编将寄存器eax中的值写回内存中。
这样由于线程执行的并发性,很可能线程A执行到第二句时,线程B开始执行,线程B将原来的值又写入寄存器eax中,这样线程A所主要计算的值就被线程B修改了。这样执行下来,结果是不可预知的——可能会出现50,可能小于50。
因此在多线程环境中对一个变量进行读写时,我们需要有一种方法能够保证对一个值的递增操作是原子操作——即不可打断性,一个线程在执行原子操作时,其它线程必须等待它完成之后才能开始执行该原子操作。这种涉及到硬件的操作会不会很复杂了,幸运的是,Windows系统为我们提供了一些以Interlocked开头的函数来完成这一任务(下文将这些函数称为Interlocked系列函数)。
下面列出一些常用的Interlocked系列函数:
1.增减操作
LONG__cdeclInterlockedIncrement(LONG volatile* Addend);
LONG__cdeclInterlockedDecrement(LONG volatile* Addend);
返回变量值运算后与0比较的值,等于0返回0,大于0返回正数,小于0返回负数。
LONG__cdeclInterlockedAdd(LONG volatile* Addend, LONGValue);
返回运算后的值,注意!加个负数就是减。
2.赋值操作
LONG__cdeclInterlockedExchange(LONG volatile* Target, LONGValue);
Value就是新值,函数会返回原先的值。
在本例中只要使用InterlockedIncrement()函数就可以了。将线程函数代码改成:
- DWORD WINAPI ThreadFun(void *pPM)
- {
- Sleep(100);//some work should to do
- //g_nLoginCount++;
- InterlockedIncrement((LPLONG)&g_nLoginCount);
- Sleep(50);
- return 0;
- }
再次运行,可以发现结果会是唯一的。

因此,在多线程环境下,我们对变量的自增自减这些简单的语句也要慎重思考,防止多个线程导致的数据访问出错。更多介绍,请访问MSDN上Synchronization Functions这一章节,地址为 http://msdn.microsoft.com/zh-cn/library/aa909196.aspx
看到这里,相信本系列首篇《秒杀多线程第一篇 多线程笔试面试题汇总》中选择题第一题(百度笔试题)应该可以秒杀掉了吧(知其然也知其所以然),正确答案是D。另外给个附加问题,程序中是用50个线程模拟用户登录,有兴趣的同学可以试下用100个线程来模拟一下(上机试试绝对会有意外发现^_^)。
下一篇《秒杀多线程第四篇 一个经典多线程同步问题》将提出一个稍为复杂点但却非常经典的多线程同步互斥问题,这个问题会采用不同的方法来解答,从而让你充分熟练多线程同步互斥的“招式”。更多精彩,欢迎继续参阅。
秒杀多线程第四篇 一个经典的多线程同步问题
上一篇《秒杀多线程第三篇原子操作 Interlocked系列函数》中介绍了原子操作在多进程中的作用,现在来个复杂点的。这个问题涉及到线程的同步和互斥,是一道非常有代表性的多线程同步问题,如果能将这个问题搞清楚,那么对多线程同步也就打下了良好的基础。
程序描述:
主线程启动10个子线程并将表示子线程序号的变量地址作为参数传递给子线程。子线程接收参数 -> sleep(50) -> 全局变量++ -> sleep(0) -> 输出参数和全局变量。
要求:
1.子线程输出的线程序号不能重复。
2.全局变量的输出必须递增。
下面画了个简单的示意图:

分析下这个问题的考察点,主要考察点有二个:
1.主线程创建子线程并传入一个指向变量地址的指针作参数,由于线程启动须要花费一定的时间,所以在子线程根据这个指针访问并保存数据前,主线程应等待子线程保存完毕后才能改动该参数并启动下一个线程。这涉及到主线程与子线程之间的同步。
2.子线程之间会互斥的改动和输出全局变量。要求全局变量的输出必须递增。这涉及到各子线程间的互斥。
下面列出这个程序的基本框架,可以在此代码基础上进行修改和验证。
- //经典线程同步互斥问题
- #include <stdio.h>
- #include <process.h>
- #include <windows.h>
- long g_nNum; //全局资源
- unsigned int __stdcall Fun(void *pPM); //线程函数
- const int THREAD_NUM = 10; //子线程个数
- int main()
- {
- g_nNum = 0;
- HANDLE handle[THREAD_NUM];
- int i = 0;
- while (i < THREAD_NUM)
- {
- handle[i] = (HANDLE)_beginthreadex(NULL, 0, Fun, &i, 0, NULL);
- i++;//等子线程接收到参数时主线程可能改变了这个i的值
- }
- //保证子线程已全部运行结束
- WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
- return 0;
- }
- unsigned int __stdcall Fun(void *pPM)
- {
- //由于创建线程是要一定的开销的,所以新线程并不能第一时间执行到这来
- int nThreadNum = *(int *)pPM; //子线程获取参数
- Sleep(50);//some work should to do
- g_nNum++; //处理全局资源
- Sleep(0);//some work should to do
- printf("线程编号为%d 全局资源值为%d\n", nThreadNum, g_nNum);
- return 0;
- }
运行结果可以参考下列图示,强烈建议读者亲自试一试。
图1
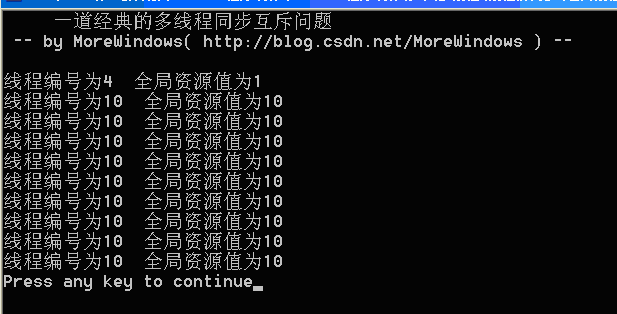
图2
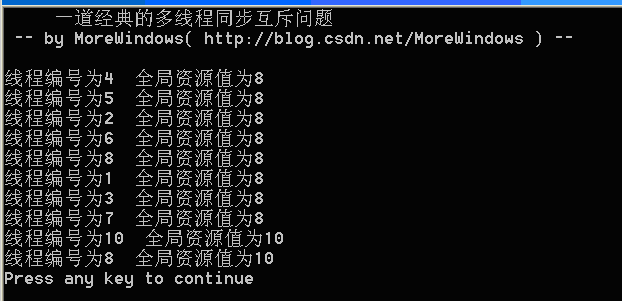
图3

可以看出,运行结果完全是混乱和不可预知的。本系列将会运用Windows平台下各种手段包括关键段,事件,互斥量,信号量等等来解决这个问题并作一份全面的总结,敬请关注。
秒杀多线程第五篇 经典线程同步 关键段CS
上一篇《秒杀多线程第四篇 一个经典的多线程同步问题》提出了一个经典的多线程同步互斥问题,本篇将用关键段CRITICAL_SECTION来尝试解决这个问题。
本文首先介绍下如何使用关键段,然后再深层次的分析下关键段的实现机制与原理。
关键段CRITICAL_SECTION一共就四个函数,使用很是方便。下面是这四个函数的原型和使用说明。
函数功能:初始化
函数原型:
void InitializeCriticalSection(LPCRITICAL_SECTIONlpCriticalSection);
函数说明:定义关键段变量后必须先初始化。
函数功能:销毁
函数原型:
void DeleteCriticalSection(LPCRITICAL_SECTIONlpCriticalSection);
函数说明:用完之后记得销毁。
函数功能:进入关键区域
函数原型:
void EnterCriticalSection(LPCRITICAL_SECTIONlpCriticalSection);
函数说明:系统保证各线程互斥的进入关键区域。
函数功能:离开关关键区域
函数原型:
void LeaveCriticalSection(LPCRITICAL_SECTIONlpCriticalSection);
然后在经典多线程问题中设置二个关键区域。一个是主线程在递增子线程序号时,另一个是各子线程互斥的访问输出全局资源时。详见代码:
- #include <stdio.h>
- #include <process.h>
- #include <windows.h>
- long g_nNum;
- unsigned int __stdcall Fun(void *pPM);
- const int THREAD_NUM = 10;
- //关键段变量声明
- CRITICAL_SECTION g_csThreadParameter, g_csThreadCode;
- int main()
- {
- printf(" 经典线程同步 关键段\n");
- printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
- //关键段初始化
- InitializeCriticalSection(&g_csThreadParameter);
- InitializeCriticalSection(&g_csThreadCode);
- HANDLE handle[THREAD_NUM];
- g_nNum = 0;
- int i = 0;
- while (i < THREAD_NUM)
- {
- EnterCriticalSection(&g_csThreadParameter);//进入子线程序号关键区域
- handle[i] = (HANDLE)_beginthreadex(NULL, 0, Fun, &i, 0, NULL);
- ++i;
- }
- WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
- DeleteCriticalSection(&g_csThreadCode);
- DeleteCriticalSection(&g_csThreadParameter);
- return 0;
- }
- unsigned int __stdcall Fun(void *pPM)
- {
- int nThreadNum = *(int *)pPM;
- LeaveCriticalSection(&g_csThreadParameter);//离开子线程序号关键区域
- Sleep(50);//some work should to do
- EnterCriticalSection(&g_csThreadCode);//进入各子线程互斥区域
- g_nNum++;
- Sleep(0);//some work should to do
- printf("线程编号为%d 全局资源值为%d\n", nThreadNum, g_nNum);
- LeaveCriticalSection(&g_csThreadCode);//离开各子线程互斥区域
- return 0;
- }
运行结果如下图:
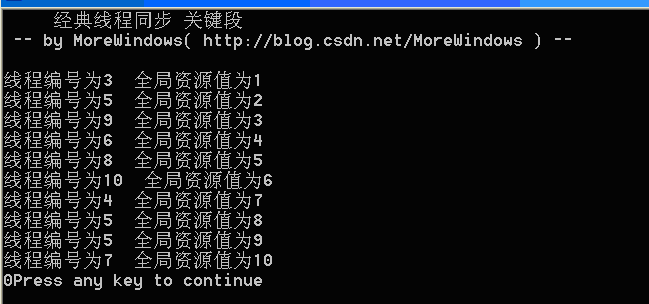
可以看出来,各子线程已经可以互斥的访问与输出全局资源了,但主线程与子线程之间的同步还是有点问题。
这是为什么了?
要解开这个迷,最直接的方法就是先在程序中加上断点来查看程序的运行流程。断点处置示意如下:
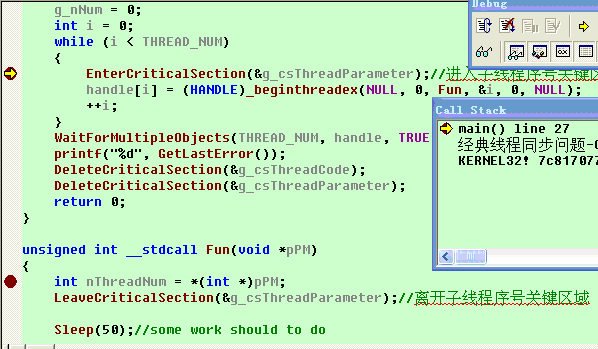
然后按F5进行调试,正常来说这两个断点应该是依次轮流执行,但实际调试时却发现不是如此,主线程可以多次通过第一个断点即
EnterCriticalSection(&g_csThreadParameter);//进入子线程序号关键区域
这一语句。这说明主线程能多次进入这个关键区域!找到主线程和子线程没能同步的原因后,下面就来分析下原因的原因吧^_^
先找到关键段CRITICAL_SECTION的定义吧,它在WinBase.h中被定义成RTL_CRITICAL_SECTION。而RTL_CRITICAL_SECTION在WinNT.h中声明,它其实是个结构体:
typedef struct _RTL_CRITICAL_SECTION {
PRTL_CRITICAL_SECTION_DEBUGDebugInfo;
LONGLockCount;
LONGRecursionCount;
HANDLEOwningThread; // from the thread's ClientId->UniqueThread
HANDLELockSemaphore;
DWORDSpinCount;
} RTL_CRITICAL_SECTION, *PRTL_CRITICAL_SECTION;
各个参数的解释如下:
第一个参数:PRTL_CRITICAL_SECTION_DEBUGDebugInfo;
调试用的。
第二个参数:LONGLockCount;
初始化为-1,n表示有n个线程在等待。
第三个参数:LONGRecursionCount;
表示该关键段的拥有线程对此资源获得关键段次数,初为0。
第四个参数:HANDLEOwningThread;
即拥有该关键段的线程句柄,微软对其注释为——from the thread's ClientId->UniqueThread
第五个参数:HANDLELockSemaphore;
实际上是一个自复位事件。
第六个参数:DWORDSpinCount;
旋转锁的设置,单CPU下忽略
由这个结构可以知道关键段会记录拥有该关键段的线程句柄即关键段是有“线程所有权”概念的。事实上它会用第四个参数OwningThread来记录获准进入关键区域的线程句柄,如果这个线程再次进入,EnterCriticalSection()会更新第三个参数RecursionCount以记录该线程进入的次数并立即返回让该线程进入。其它线程调用EnterCriticalSection()则会被切换到等待状态,一旦拥有线程所有权的线程调用LeaveCriticalSection()使其进入的次数为0时,系统会自动更新关键段并将等待中的线程换回可调度状态。
因此可以将关键段比作旅馆的房卡,调用EnterCriticalSection()即申请房卡,得到房卡后自己当然是可以多次进出房间的,在你调用LeaveCriticalSection()交出房卡之前,别人自然是无法进入该房间。
回到这个经典线程同步问题上,主线程正是由于拥有“线程所有权”即房卡,所以它可以重复进入关键代码区域从而导致子线程在接收参数之前主线程就已经修改了这个参数。所以关键段可以用于线程间的互斥,但不可以用于同步。
另外,由于将线程切换到等待状态的开销较大,因此为了提高关键段的性能,Microsoft将旋转锁合并到关键段中,这样EnterCriticalSection()会先用一个旋转锁不断循环,尝试一段时间才会将线程切换到等待状态。下面是配合了旋转锁的关键段初始化函数
函数功能:初始化关键段并设置旋转次数
函数原型:
BOOLInitializeCriticalSectionAndSpinCount(
LPCRITICAL_SECTIONlpCriticalSection,
DWORDdwSpinCount);
函数说明:旋转次数一般设置为4000。
函数功能:修改关键段的旋转次数
函数原型:
DWORDSetCriticalSectionSpinCount(
LPCRITICAL_SECTIONlpCriticalSection,
DWORDdwSpinCount);
《Windows核心编程》第五版的第八章推荐在使用关键段的时候同时使用旋转锁,这样有助于提高性能。值得注意的是如果主机只有一个处理器,那么设置旋转锁是无效的。无法进入关键区域的线程总会被系统将其切换到等待状态。
最后总结下关键段:
1.关键段共初始化化、销毁、进入和离开关键区域四个函数。
2.关键段可以解决线程的互斥问题,但因为具有“线程所有权”,所以无法解决同步问题。
3.推荐关键段与旋转锁配合使用。
秒杀多线程第六篇 经典线程同步 事件Event
上一篇中使用关键段来解决经典的多线程同步互斥问题,由于关键段的“线程所有权”特性所以关键段只能用于线程的互斥而不能用于同步。本篇介绍用事件Event来尝试解决这个线程同步问题。
首先介绍下如何使用事件。事件Event实际上是个内核对象,它的使用非常方便。下面列出一些常用的函数。
第一个 CreateEvent
函数功能:创建事件
函数原型:
HANDLECreateEvent(
LPSECURITY_ATTRIBUTESlpEventAttributes,
BOOLbManualReset,
BOOLbInitialState,
LPCTSTRlpName
);
函数说明:
第一个参数表示安全控制,一般直接传入NULL。
第二个参数确定事件是手动置位还是自动置位,传入TRUE表示手动置位,传入FALSE表示自动置位。如果为自动置位,则对该事件调用WaitForSingleObject()后会自动调用ResetEvent()使事件变成未触发状态。打个小小比方,手动置位事件相当于教室门,教室门一旦打开(被触发),所以有人都可以进入直到老师去关上教室门(事件变成未触发)。自动置位事件就相当于医院里拍X光的房间门,门打开后只能进入一个人,这个人进去后会将门关上,其它人不能进入除非门重新被打开(事件重新被触发)。
第三个参数表示事件的初始状态,传入TRUR表示已触发。
第四个参数表示事件的名称,传入NULL表示匿名事件。
第二个 OpenEvent
函数功能:根据名称获得一个事件句柄。
函数原型:
HANDLEOpenEvent(
DWORDdwDesiredAccess,
BOOLbInheritHandle,
LPCTSTRlpName //名称
);
函数说明:
第一个参数表示访问权限,对事件一般传入EVENT_ALL_ACCESS。详细解释可以查看MSDN文档。
第二个参数表示事件句柄继承性,一般传入TRUE即可。
第三个参数表示名称,不同进程中的各线程可以通过名称来确保它们访问同一个事件。
第三个SetEvent
函数功能:触发事件
函数原型:BOOLSetEvent(HANDLEhEvent);
函数说明:每次触发后,必有一个或多个处于等待状态下的线程变成可调度状态。
第四个ResetEvent
函数功能:将事件设为末触发
函数原型:BOOLResetEvent(HANDLEhEvent);
最后一个事件的清理与销毁
由于事件是内核对象,因此使用CloseHandle()就可以完成清理与销毁了。
在经典多线程问题中设置一个事件和一个关键段。用事件处理主线程与子线程的同步,用关键段来处理各子线程间的互斥。详见代码:
- #include <stdio.h>
- #include <process.h>
- #include <windows.h>
- long g_nNum;
- unsigned int __stdcall Fun(void *pPM);
- const int THREAD_NUM = 10;
- //事件与关键段
- HANDLE g_hThreadEvent;
- CRITICAL_SECTION g_csThreadCode;
- int main()
- {
- printf(" 经典线程同步 事件Event\n");
- printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
- //初始化事件和关键段 自动置位,初始无触发的匿名事件
- g_hThreadEvent = CreateEvent(NULL, FALSE, FALSE, NULL);
- InitializeCriticalSection(&g_csThreadCode);
- HANDLE handle[THREAD_NUM];
- g_nNum = 0;
- int i = 0;
- while (i < THREAD_NUM)
- {
- handle[i] = (HANDLE)_beginthreadex(NULL, 0, Fun, &i, 0, NULL);
- WaitForSingleObject(g_hThreadEvent, INFINITE); //等待事件被触发
- i++;
- }
- WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
- //销毁事件和关键段
- CloseHandle(g_hThreadEvent);
- DeleteCriticalSection(&g_csThreadCode);
- return 0;
- }
- unsigned int __stdcall Fun(void *pPM)
- {
- int nThreadNum = *(int *)pPM;
- SetEvent(g_hThreadEvent); //触发事件
- Sleep(50);//some work should to do
- EnterCriticalSection(&g_csThreadCode);
- g_nNum++;
- Sleep(0);//some work should to do
- printf("线程编号为%d 全局资源值为%d\n", nThreadNum, g_nNum);
- LeaveCriticalSection(&g_csThreadCode);
- return 0;
- }
运行结果如下图:
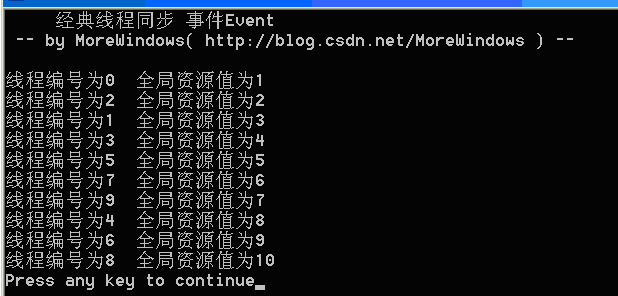
可以看出来,经典线线程同步问题已经圆满的解决了——线程编号的输出没有重复,说明主线程与子线程达到了同步。全局资源的输出是递增的,说明各子线程已经互斥的访问和输出该全局资源。
现在我们知道了如何使用事件,但学习就应该要深入的学习,何况微软给事件还提供了PulseEvent()函数,所以接下来再继续深挖下事件Event,看看它还有什么秘密没。
先来看看这个函数的原形:
第五个PulseEvent
函数功能:将事件触发后立即将事件设置为未触发,相当于触发一个事件脉冲。
函数原型:BOOLPulseEvent(HANDLEhEvent);
函数说明:这是一个不常用的事件函数,此函数相当于SetEvent()后立即调用ResetEvent();此时情况可以分为两种:
1.对于手动置位事件,所有正处于等待状态下线程都变成可调度状态。
2.对于自动置位事件,所有正处于等待状态下线程只有一个变成可调度状态。
此后事件是末触发的。该函数不稳定,因为无法预知在调用PulseEvent ()时哪些线程正处于等待状态。
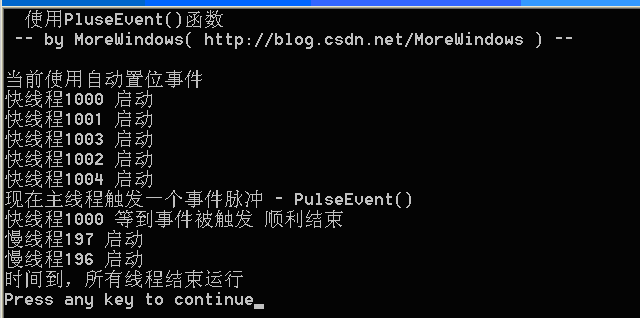
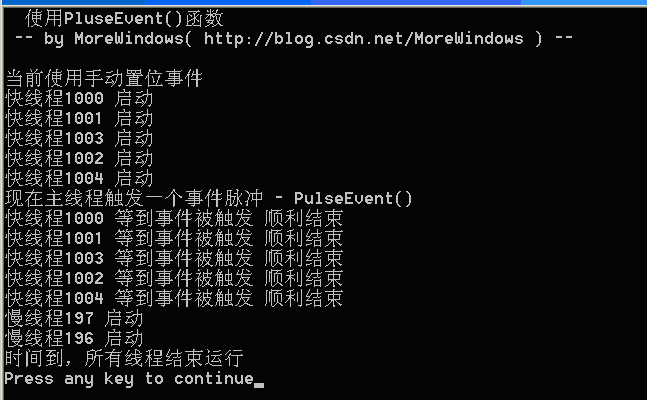
下面对这个触发一个事件脉冲PulseEvent ()写一个例子,主线程启动7个子线程,其中有5个线程Sleep(10)后对一事件调用等待函数(称为快线程),另有2个线程Sleep(100)后也对该事件调用等待函数(称为慢线程)。主线程启动所有子线程后再Sleep(50)保证有5个快线程都正处于等待状态中。此时若主线程触发一个事件脉冲,那么对于手动置位事件,这5个线程都将顺利执行下去。对于自动置位事件,这5个线程中会有中一个顺利执行下去。而不论手动置位事件还是自动置位事件,那2个慢线程由于Sleep(100)所以会错过事件脉冲,因此慢线程都会进入等待状态而无法顺利执行下去。
代码如下:
- //使用PluseEvent()函数
- #include <stdio.h>
- #include <conio.h>
- #include <process.h>
- #include <windows.h>
- HANDLE g_hThreadEvent;
- //快线程
- unsigned int __stdcall FastThreadFun(void *pPM)
- {
- Sleep(10); //用这个来保证各线程调用等待函数的次序有一定的随机性
- printf("%s 启动\n", (PSTR)pPM);
- WaitForSingleObject(g_hThreadEvent, INFINITE);
- printf("%s 等到事件被触发 顺利结束\n", (PSTR)pPM);
- return 0;
- }
- //慢线程
- unsigned int __stdcall SlowThreadFun(void *pPM)
- {
- Sleep(100);
- printf("%s 启动\n", (PSTR)pPM);
- WaitForSingleObject(g_hThreadEvent, INFINITE);
- printf("%s 等到事件被触发 顺利结束\n", (PSTR)pPM);
- return 0;
- }
- int main()
- {
- printf(" 使用PluseEvent()函数\n");
- printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
- BOOL bManualReset = FALSE;
- //创建事件 第二个参数手动置位TRUE,自动置位FALSE
- g_hThreadEvent = CreateEvent(NULL, bManualReset, FALSE, NULL);
- if (bManualReset == TRUE)
- printf("当前使用手动置位事件\n");
- else
- printf("当前使用自动置位事件\n");
- char szFastThreadName[5][30] = {"快线程1000", "快线程1001", "快线程1002", "快线程1003", "快线程1004"};
- char szSlowThreadName[2][30] = {"慢线程196", "慢线程197"};
- int i;
- for (i = 0; i < 5; i++)
- _beginthreadex(NULL, 0, FastThreadFun, szFastThreadName[i], 0, NULL);
- for (i = 0; i < 2; i++)
- _beginthreadex(NULL, 0, SlowThreadFun, szSlowThreadName[i], 0, NULL);
- Sleep(50); //保证快线程已经全部启动
- printf("现在主线程触发一个事件脉冲 - PulseEvent()\n");
- PulseEvent(g_hThreadEvent);//调用PulseEvent()就相当于同时调用下面二句
- //SetEvent(g_hThreadEvent);
- //ResetEvent(g_hThreadEvent);
- Sleep(3000);
- printf("时间到,主线程结束运行\n");
- CloseHandle(g_hThreadEvent);
- return 0;
- }
对自动置位事件,运行结果如下:
对手动置位事件,运行结果如下:
最后总结下事件Event
1.事件是内核对象,事件分为手动置位事件和自动置位事件。事件Event内部它包含一个使用计数(所有内核对象都有),一个布尔值表示是手动置位事件还是自动置位事件,另一个布尔值用来表示事件有无触发。
2.事件可以由SetEvent()来触发,由ResetEvent()来设成未触发。还可以由PulseEvent()来发出一个事件脉冲。
3.事件可以解决线程间同步问题,因此也能解决互斥问题。
后面二篇《秒杀多线程第七篇 经典线程同步 互斥量Mutex》和《秒杀多线程第八篇 经典线程同步 信号量Semaphore》将介绍如何使用互斥量和信号量来解决这个经典线程同步问题。欢迎大家继续秒杀多线程之旅。
秒杀多线程第七篇 经典线程同步 互斥量Mutex
前面介绍了关键段CS、事件Event在经典线程同步问题中的使用。本篇介绍用互斥量Mutex来解决这个问题。
互斥量也是一个内核对象,它用来确保一个线程独占一个资源的访问。互斥量与关键段的行为非常相似,并且互斥量可以用于不同进程中的线程互斥访问资源。使用互斥量Mutex主要将用到四个函数。下面是这些函数的原型和使用说明。
第一个 CreateMutex
函数功能:创建互斥量(注意与事件Event的创建函数对比)
函数原型:
HANDLECreateMutex(
LPSECURITY_ATTRIBUTESlpMutexAttributes,
BOOLbInitialOwner,
LPCTSTRlpName
);
函数说明:
第一个参数表示安全控制,一般直接传入NULL。
第二个参数用来确定互斥量的初始拥有者。如果传入TRUE表示互斥量对象内部会记录创建它的线程的线程ID号并将递归计数设置为1,由于该线程ID非零,所以互斥量处于未触发状态。如果传入FALSE,那么互斥量对象内部的线程ID号将设置为NULL,递归计数设置为0,这意味互斥量不为任何线程占用,处于触发状态。
第三个参数用来设置互斥量的名称,在多个进程中的线程就是通过名称来确保它们访问的是同一个互斥量。
函数访问值:
成功返回一个表示互斥量的句柄,失败返回NULL。
第二个打开互斥量
函数原型:
HANDLEOpenMutex(
DWORDdwDesiredAccess,
BOOLbInheritHandle,
LPCTSTRlpName //名称
);
函数说明:
第一个参数表示访问权限,对互斥量一般传入MUTEX_ALL_ACCESS。详细解释可以查看MSDN文档。
第二个参数表示互斥量句柄继承性,一般传入TRUE即可。
第三个参数表示名称。某一个进程中的线程创建互斥量后,其它进程中的线程就可以通过这个函数来找到这个互斥量。
函数访问值:
成功返回一个表示互斥量的句柄,失败返回NULL。
第三个触发互斥量
函数原型:
BOOLReleaseMutex (HANDLEhMutex)
函数说明:
访问互斥资源前应该要调用等待函数,结束访问时就要调用ReleaseMutex()来表示自己已经结束访问,其它线程可以开始访问了。
最后一个清理互斥量
由于互斥量是内核对象,因此使用CloseHandle()就可以(这一点所有内核对象都一样)。
接下来我们就在经典多线程问题用互斥量来保证主线程与子线程之间的同步,由于互斥量的使用函数类似于事件Event,所以可以仿照上一篇的实现来写出代码:
- //经典线程同步问题 互斥量Mutex
- #include <stdio.h>
- #include <process.h>
- #include <windows.h>
- long g_nNum;
- unsigned int __stdcall Fun(void *pPM);
- const int THREAD_NUM = 10;
- //互斥量与关键段
- HANDLE g_hThreadParameter;
- CRITICAL_SECTION g_csThreadCode;
- int main()
- {
- printf(" 经典线程同步 互斥量Mutex\n");
- printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
- //初始化互斥量与关键段 第二个参数为TRUE表示互斥量为创建线程所有
- g_hThreadParameter = CreateMutex(NULL, FALSE, NULL);
- InitializeCriticalSection(&g_csThreadCode);
- HANDLE handle[THREAD_NUM];
- g_nNum = 0;
- int i = 0;
- while (i < THREAD_NUM)
- {
- handle[i] = (HANDLE)_beginthreadex(NULL, 0, Fun, &i, 0, NULL);
- WaitForSingleObject(g_hThreadParameter, INFINITE); //等待互斥量被触发
- i++;
- }
- WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
- //销毁互斥量和关键段
- CloseHandle(g_hThreadParameter);
- DeleteCriticalSection(&g_csThreadCode);
- for (i = 0; i < THREAD_NUM; i++)
- CloseHandle(handle[i]);
- return 0;
- }
- unsigned int __stdcall Fun(void *pPM)
- {
- int nThreadNum = *(int *)pPM;
- ReleaseMutex(g_hThreadParameter);//触发互斥量
- Sleep(50);//some work should to do
- EnterCriticalSection(&g_csThreadCode);
- g_nNum++;
- Sleep(0);//some work should to do
- printf("线程编号为%d 全局资源值为%d\n", nThreadNum, g_nNum);
- LeaveCriticalSection(&g_csThreadCode);
- return 0;
- }
运行结果如下图:
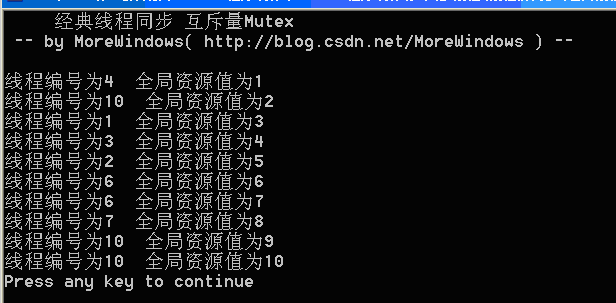
可以看出,与关键段类似,互斥量也是不能解决线程间的同步问题。
联想到关键段会记录线程ID即有“线程拥有权”的,而互斥量也记录线程ID,莫非它也有“线程拥有权”这一说法。
答案确实如此,互斥量也是有“线程拥有权”概念的。“线程拥有权”在关键段中有详细的说明,这里就不再赘述了。另外由于互斥量常用于多进程之间的线程互斥,所以它比关键段还多一个很有用的特性——“遗弃”情况的处理。比如有一个占用互斥量的线程在调用ReleaseMutex()触发互斥量前就意外终止了(相当于该互斥量被“遗弃”了),那么所有等待这个互斥量的线程是否会由于该互斥量无法被触发而陷入一个无穷的等待过程中了?这显然不合理。因为占用某个互斥量的线程既然终止了那足以证明它不再使用被该互斥量保护的资源,所以这些资源完全并且应当被其它线程来使用。因此在这种“遗弃”情况下,系统自动把该互斥量内部的线程ID设置为0,并将它的递归计数器复置为0,表示这个互斥量被触发了。然后系统将“公平地”选定一个等待线程来完成调度(被选中的线程的WaitForSingleObject()会返回WAIT_ABANDONED_0)。
下面写二个程序来验证下:
第一个程序创建互斥量并等待用户输入后就触发互斥量。第二个程序先打开互斥量,成功后就等待并根据等待结果作相应的输出。详见代码:
第一个程序:
- #include <stdio.h>
- #include <conio.h>
- #include <windows.h>
- const char MUTEX_NAME[] = "Mutex_MoreWindows";
- int main()
- {
- HANDLE hMutex = CreateMutex(NULL, TRUE, MUTEX_NAME); //创建互斥量
- printf("互斥量已经创建,现在按任意键触发互斥量\n");
- getch();
- //exit(0);
- ReleaseMutex(hMutex);
- printf("互斥量已经触发\n");
- CloseHandle(hMutex);
- return 0;
- }
第二个程序:
- #include <stdio.h>
- #include <windows.h>
- const char MUTEX_NAME[] = "Mutex_MoreWindows";
- int main()
- {
- HANDLE hMutex = OpenMutex(MUTEX_ALL_ACCESS, TRUE, MUTEX_NAME); //打开互斥量
- if (hMutex == NULL)
- {
- printf("打开互斥量失败\n");
- return 0;
- }
- printf("等待中....\n");
- DWORD dwResult = WaitForSingleObject(hMutex, 20 * 1000); //等待互斥量被触发
- switch (dwResult)
- {
- case WAIT_ABANDONED:
- printf("拥有互斥量的进程意外终止\n");
- break;
- case WAIT_OBJECT_0:
- printf("已经收到信号\n");
- break;
- case WAIT_TIMEOUT:
- printf("信号未在规定的时间内送到\n");
- break;
- }
- CloseHandle(hMutex);
- return 0;
- }
运用这二个程序时要先启动程序一再启动程序二。下面展示部分输出结果:
结果一.二个进程顺利执行完毕:

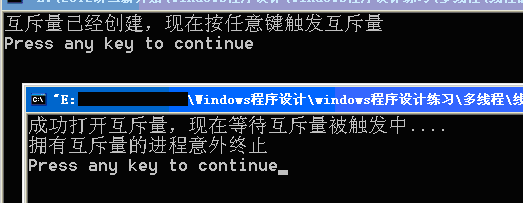
结果二.将程序一中//exit(0);前面的注释符号去掉,这样程序一在触发互斥量之前就会因为执行exit(0);语句而且退出,程序二会收到WAIT_ABANDONED消息并输出“拥有互斥量的进程意外终止”:
有这个对“遗弃”问题的处理,在多进程中的线程同步也可以放心的使用互斥量。
最后总结下互斥量Mutex:
1.互斥量是内核对象,它与关键段都有“线程所有权”所以不能用于线程的同步。
2.互斥量能够用于多个进程之间线程互斥问题,并且能完美的解决某进程意外终止所造成的“遗弃”问题。
秒杀多线程第八篇 经典线程同步 信号量Semaphore
前面介绍了关键段CS、事件Event、互斥量Mutex在经典线程同步问题中的使用。本篇介绍用信号量Semaphore来解决这个问题。
首先也来看看如何使用信号量,信号量Semaphore常用有三个函数,使用很方便。下面是这几个函数的原型和使用说明。
第一个 CreateSemaphore
函数功能:创建信号量
函数原型:
HANDLE CreateSemaphore(
LPSECURITY_ATTRIBUTES lpSemaphoreAttributes,
LONG lInitialCount,
LONG lMaximumCount,
LPCTSTR lpName
);
函数说明:
第一个参数表示安全控制,一般直接传入NULL。
第二个参数表示初始资源数量。
第三个参数表示最大并发数量。
第四个参数表示信号量的名称,传入NULL表示匿名信号量。
第二个 OpenSemaphore
函数功能:打开信号量
函数原型:
HANDLE OpenSemaphore(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
LPCTSTR lpName
);
函数说明:
第一个参数表示访问权限,对一般传入SEMAPHORE_ALL_ACCESS。详细解释可以查看MSDN文档。
第二个参数表示信号量句柄继承性,一般传入TRUE即可。
第三个参数表示名称,不同进程中的各线程可以通过名称来确保它们访问同一个信号量。
第三个 ReleaseSemaphore
函数功能:递增信号量的当前资源计数
函数原型:
BOOL ReleaseSemaphore(
HANDLE hSemaphore,
LONG lReleaseCount,
LPLONG lpPreviousCount
);
函数说明:
第一个参数是信号量的句柄。
第二个参数表示增加个数,必须大于0且不超过最大资源数量。
第三个参数可以用来传出先前的资源计数,设为NULL表示不需要传出。
注意:当前资源数量大于0,表示信号量处于触发,等于0表示资源已经耗尽故信号量处于末触发。在对信号量调用等待函数时,等待函数会检查信号量的当前资源计数,如果大于0(即信号量处于触发状态),减1后返回让调用线程继续执行。一个线程可以多次调用等待函数来减小信号量。
最后一个 信号量的清理与销毁
由于信号量是内核对象,因此使用CloseHandle()就可以完成清理与销毁了。
在经典多线程问题中设置一个信号量和一个关键段。用信号量处理主线程与子线程的同步,用关键段来处理各子线程间的互斥。详见代码:
- #include <stdio.h>
- #include <process.h>
- #include <windows.h>
- long g_nNum;
- unsigned int __stdcall Fun(void *pPM);
- const int THREAD_NUM = 10;
- //信号量与关键段
- HANDLE g_hThreadParameter;
- CRITICAL_SECTION g_csThreadCode;
- int main()
- {
- printf(" 经典线程同步 信号量Semaphore\n");
- printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
- //初始化信号量和关键段
- g_hThreadParameter = CreateSemaphore(NULL, 0, 1, NULL);//当前0个资源,最大允许1个同时访问
- InitializeCriticalSection(&g_csThreadCode);
- HANDLE handle[THREAD_NUM];
- g_nNum = 0;
- int