应用程序中使用 XML 文档的多数方法都把重点放在 XML 上:从 XML 的观点使用文档,按照 XML 元素、属性和字符数据内容编程。如果应用程序主要关心文档的 XML 结构,那么这种方法非常好。对于更关心文档中所含数据而非文档本身的许多应用程序而言, 数据绑定提供了一种更简单的使用 XML 的方法。
文档模型与数据绑定
本系列文章的上一篇(请参阅 参考资料)所讨论的文档模型,是与数据绑定最接近的替代方案。文档模型和数据绑定都在内存中建立文档的表示,都需要在内部表示和标准文本 XML 之间双向转换。两者的区别在于文档模型尽可能保持 XML 结构,而数据绑定只关心应用程序所使用的文档数据。
为了说明这一点,图 1 给出了一个简单 XML 文档的数据模型视图。文档成分——在这个例子中只有元素和文本节点——通过反映原始 XML 文档的结构连接在一起。形成的节点树很容易和原始文档联系,但要解释树中表示的实际数据就不那么容易了。
图 1. 文档的文档模型视图
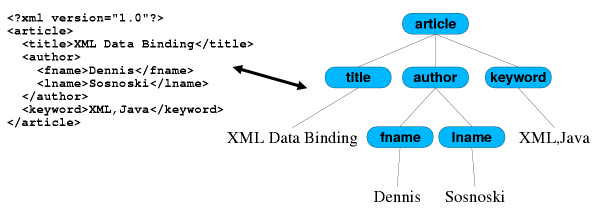
如果应用程序使用 XML 文档模型方法,您就需要处理这种类型的树。这种情况下,您将使用节点之间的父子关系在树的上下层之间导航,使用属于同一父节点的子女之间的兄弟关系在树的同一层中导航。您可以非常详尽地处理树结构,当把树序列化为文本时,生成的 XML 文档将反映您所做的修改(比如插入的注释)。
现在来看看与图 1 截然不同的图 2,它表示同一文档的数据绑定视图。在这里,转换过程几乎隐藏了原始 XML 文档的所有结构,但是因为只有通过两个对象,更容易看清楚真正的数据,也更很容易访问这些数据。
图 2. 文档的数据绑定视图
使用这种数据结构就像是一般的 Java 编程——甚至根本不需要知道 XML!(哦,还是不要走得 太远了——我们这些专家顾问还得活……)您的项目中至少要有人明白,这种数据结构和 XML 文档之间的映射是如何建立的,但这仍然是向简化迈出的一大步。
不 仅仅是编程的简化,数据绑定还带来其他的好处。与文档模型方法相比,因为抽掉了许多文档细节,数据绑定通常需要的内存更少。比如前面两个图中所示的数据结构:文档模型方法使用了 10 个单独的对象,与此相比数据绑定只使用了两个。要创建的东西少,构造文档的数据绑定表示可能就更快一些。最后,数据绑定与文档模型相比,应用程序可以更快地访问数据,因为您可以控制如何表示和存储数据。我后面还要讲到这一点。
既然数据绑定那么好,为何还要使用文档模型呢?以下两种情况需要使用文档模型:
- 应用程序真正关注文档结构的细节。比方说,如果您在编写一个 XML 文档编辑器,您就会坚持使用文档模型而非数据绑定。
- 您处理的文档没有固定的结构。比如实现一种通用的 XML 文档数据库,数据绑定就不是一种好办法。
许多应用程序使用 XML 传输数据,但并不关心文档表示的细节。这类应用程序非常适合使用数据绑定。如果您的应用程序符合这种模式,请继续读下去。
回页首
Castor 框架
目前有几种不同的框架支持 Java XML 数据绑定,但还没有标准的接口。这种情况最终会得到改变:Java Community Process (JCP) 的 JSR-031 正在努力定义这方面的标准(请参阅 参考资料)。现在让我们选择一个框架并学习使用它的接口。
本文选择了 Castor 数据绑定框架。Castor 项目采用 BSD 类型的证书,因此可在任何类型的应用程序(包括完整版权的项目)中使用。 Castor 实际上仅仅有 XML 数据绑定,它还支持 SQL 和 LDAP 绑定,尽管本文中不讨论这些其他的特性。该项目从 2000 年初开始发起,目前处于后 beta 状态(一般可以使用这个版本,但是如果需要问题修正,您可能需要升级到目前的 CVS 版本)。请参阅参考资料部分的 Castor 站点链接,以了解更多的细节并下载该软件。
回页首
默认绑定
Castor XML 数据绑定很容易上手,甚至不需要定义 XML 文档格式。只要您的数据用类 JavaBean 的对象表示,Castor 就能自动生成表示这些数据的文档格式,然后从文档重构原始数据。
那么“类 JavaBean”是什么意思呢?真正的 JavaBean 是可视化组件,可以在开发环境中配置以用于 GUI 布局。一些源于真正 JavaBean 的惯例已经被 Java 团体普遍接受,特别是对于数据类。如果一个类符合以下惯例,我就称之为是“类 JavaBean”的:
- 这个类是公共的
- 定义了公共的默认(没有参数)构造函数
- 定义了公共的
getX和setX方法访问属性(数据)值
关于技术定义已经扯得太远了,当提到这些类 JavaBean 类时,我将不再重复说明,只是称之为“bean”类。
在整篇文章中,我将使用航线班机时刻表作为示例代码。我们从一个简单的 bean 类开始说明它的工作原理,这个类表示一个特定的航班,包括四个信息项:
- 飞机编号(航空公司)
- 航班编号
- 起飞时间
- 抵达时间
下面的清单 1 给出了处理航班信息的代码。
清单 1. 航班信息 bean
public class FlightBean
{
private String m_carrier;
private int m_number;
private String m_departure;
private String m_arrival;
public FlightBean() {}
public void setCarrier(String carrier) {
m_carrier = carrier;
}
public String getCarrier() {
return m_carrier;
}
public void setNumber(int number) {
m_number = number;
}
public int getNumber() {
return m_number;
}
public void setDepartureTime(String time) {
m_departure = time;
}
public String getDepartureTime() {
return m_departure;
}
public void setArrivalTime(String time) {
m_arrival = time;
}
public String getArrivalTime() {
return m_arrival;
}
} |
您可以看到,这个 bean 本身没有什么意思,因此我想增加一个类并在默认的 XML 绑定中使用它,如清单 2 所示。
清单 2. 测试默认的数据绑定
import java.io.*;
import org.exolab.castor.xml.*;
public class Test
{
public static void main(String[] argv) {
// build a test bean
FlightBean bean = new FlightBean();
bean.setCarrier("AR");
bean.setNumber(426);
bean.setDepartureTime("6:23a");
bean.setArrivalTime("8:42a");
try {
// write it out as XML
File file = new File("test.xml");
Writer writer = new FileWriter(file);
Marshaller.marshal(bean, writer);
// now restore the value and list what we get
Reader reader = new FileReader(file);
FlightBean read = (FlightBean)
Unmarshaller.unmarshal(FlightBean.class, reader);
System.out.println("Flight " + read.getCarrier() +
read.getNumber() + " departing at " +
read.getDepartureTime() +
" and arriving at " + read.getArrivalTime());
} catch (IOException ex) {
ex.printStackTrace(System.err);
} catch (MarshalException ex) {
ex.printStackTrace(System.err);
} catch (ValidationException ex) {
ex.printStackTrace(System.err);
}
}
} |
这段代码首先构造了一个 FlightBean bean,并使用一些固定的数据初始化它。然后用该 bean 默认的 Castor XML 映射将其写入一个输出文件。最后又读回生成的 XML, 同样使用默认映射重构 bean,然后打印重构的 bean 中的信息。结果如下:
Flight AR426 departing at 6:23a and arriving at 8:42a
这个输出结果表明您已经成功地来回转换了航班信息(不算太糟,只有两次方法调用)。现在我还不满足于简单控制台输出,准备再往深处挖一挖。
幕后
为了更清楚地了解这个例子中发生了什么,看一看Marshaller.marshal() 调用生成的 XML。文档如下:
<?xml version="1.0"?> <flight-bean number="426"> <arrival-time>8:42a</arrival-time> <departure-time>6:23a</departure-time> <carrier>AR</carrier> </flight-bean> |
Castor 使用 Java 内部检查机制检查 Marshaller.marshal() 调用传递的对象。在本例中,它发现了定义的四个属性值。Castor 在输出的 XML 中创建一个元素(文档的根元素)表示整个对象。元素名从对象的类名中衍生出来,在这里是 flight-bean 。然后Castor 用以下两种方法中的一个,把该对象的属性值包括进来:
- 对于具有基本类型值的属性创建元素的一个属性(本例中只有
number属性通过getNumber()方法公开为int值)。 - 对于每个具有对象类型值的属性创建根元素的一个子元素(本例中的所有其他属性,因为它们是字符串)。
结果就是上面所示的 XML 文档。
回页首
改变 XML 格式
如果不喜欢 Castor 的默认映射格式,您可以方便地改变映射。在我们的航班信息例子中,比方说,假定我们需要更紧凑的数据表示。使用属性代替子元素有助于实现这个目标,我们也许还希望使用比默认的名字更短一些的名字。如下所示的文档就可以很好地满足我们的需要:
<?xml version="1.0"?> <flight carrier="AR" depart="6:23a" arrive="8:42a" number="426"/> |
定义映射
为了让 Castor 使用这种格式而非默认的格式,首先需要定义描述这种格式的映射。映射描述本身(非常意外的)是一个 XML 文档。清单 3 给出了把 bean 编组成上述格式的映射。
清单 3. 紧凑格式的映射
<!DOCTYPE databases PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN" "http://castor.exolab.org/mapping.dtd"> <mapping> <description>Basic mapping example</description> <class name="FlightBean" auto-complete="true"> <map-to xml="flight"/> <field name="carrier"> <bind-xml name="carrier" node="attribute"/> </field> <field name="departureTime"> <bind-xml name="depart" node="attribute"/> </field> <field name="arrivalTime"> <bind-xml name="arrive" node="attribute"/> </field> </class> </mapping> |
class 元素定义了一个命名类 FlightBean 的映射。通过在该元素中加入 auto-complete 属性并把值设为 true ,您可以告诉 Castor 对于该类的任何属性,只要没有在这个元素中专门列出,就使用默认映射。这样非常简便,因为 number 属性已经按照希望的方式处理了。
子元素 map-to 告诉 Castor,要把 FlightBean 类的实例映射为 XML 文档中的 flight 元素。如果您继续使用默认的元素名 flight-bean (参阅 幕后小节中默认映射输出的例子),可以不使用该元素。
最后,对于每个希望以非默认方式处理的属性,可以引入一个 field 子元素。这些子元素都按照相同的模式: name 属性给出映射的属性名, bind-xml 子元素告诉 Castor 如何映射那个属性。这里要求把每个属性映射成给定名称的属性。
使用映射
现在已经定义了一个映射,您需要告诉 Castor 框架在编组和解组数据时使用那个映射。清单 4 说明了要实现这一点,需要对前面的代码做哪些修改。
清单 4. 使用映射编组和解组
...
// write it out as XML (if not already present)
Mapping map = new Mapping();
map.loadMapping("mapping.xml");
File file = new File("test.xml");
Writer writer = new FileWriter(file);
Marshaller marshaller = new Marshaller(writer);
marshaller.setMapping(map);
marshaller.marshal(bean);
// now restore the value and list what we get
Reader reader = new FileReader(file);
Unmarshaller unmarshaller = new Unmarshaller(map);
FlightBean read = (FlightBean)unmarshaller.unmarshal(reader);
...
} catch (MappingException ex) {
ex.printStackTrace(System.err);
...
|
与前面 清单 2默认映射所用的代码相比,这段代码稍微复杂一点。在执行任何其他操作之前,首先要创建一个 Mapping 对象载入您的映射定义。真正的编组和解组也有区别。为了使用这个映射,您需要创建 Marshaller 和 Unmarshaller 对象,用定义的映射配置它们,调用这些对象的方法,而不是像第一个例子那样使用静态方法。最后,您必须提供对映射错误产生的另一个异常类型的处理。
完成这些修改后,您可以尝试再次运行程序。控制台输出与第一个例子相同(如 清单 2所示),但是现在的 XML 文档看起来符合我们的需要:
<?xml version="1.0"?> <flight carrier="AR" depart="6:23a" arrive="8:42a" number="426"/> |
回页首
处理集合
现在单个航班数据已经有了我们喜欢的形式,您可以定义一个更高级的结构:航线数据。这个结构包括起降机场的标识符以及在该航线上飞行的一组航班。清单 5 给出了一个包含这些信息的 bean 类的例子。
清单 5. 航线信息 bean
import java.util.ArrayList;
public class RouteBean
{
private String m_from;
private String m_to;
private ArrayList m_flights;
public RouteBean() {
m_flights = new ArrayList();
}
public void setFrom(String from) {
m_from = from;
}
public String getFrom() {
return m_from;
}
public void setTo(String to) {
m_to = to;
}
public String getTo() {
return m_to;
}
public ArrayList getFlights() {
return m_flights;
}
public void addFlight(FlightBean flight) {
m_flights.add(flight);
}
} |
在这段代码中,我定义了一个 addFlight() 方法,用于每次增加一个属于这条航线的航班。这是在测试程序中建立这种数据结构非常简便的办法,但是可能和您预料的相反, Castor 在解组时并不使用种方法向航线中增加航班。相反,它使用 getFlights() 方法访问一组航班,然后直接添加到集合中。
在映射中处理航班集合只需要稍微改变上一个例子(如 清单 3所示)中的 field 元素。清单 6 显示了修改后的映射文件。
清单 6. 映射包含一组航班的航线
<!DOCTYPE databases PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN" "http://castor.exolab.org/mapping.dtd"> <mapping> <description>Collection mapping example</description> <class name="RouteBean"> <map-to xml="route"/> <field name="from"> <bind-xml name="from" node="attribute"/> </field> <field name="to"> <bind-xml name="to" node="attribute"/> </field> <field name="flights" collection="collection" type="FlightBean"> <bind-xml name="flight"/> </field> </class> <class name="FlightBean" auto-complete="true"> <field name="carrier"> <bind-xml name="carrier" node="attribute"/> </field> <field name="departureTime"> <bind-xml name="depart" node="attribute"/> </field> <field name="arrivalTime"> <bind-xml name="arrive" node="attribute"/> </field> </class> </mapping> |
一切都和上一个映射(如 清单 3所示)完全相同,只不过用 field 元素定义了一个 RouteBean 的 flights 属性。这个映射用到了两个原来不需要的属性。 collection 属性的值 collection 把该属性定义成一个 java.util.Collection (其他值分别定义数组,java.util.Vectors 等等)。 type 属性定义包含在集合中的对象类型,值是完整的限定类名。这里的值是 FlightBean ,因为对这些类我没有使用包。
另一个区别在 FlightBean 类元素中,不再需要使用 map-to 子元素定义绑定的元素名。定义 RouteBean 的 flights 属性的 field 元素,通过它的 bind-xml 子元素定义了这一点。因为编组或解组 FlightBean 对象只能通过该属性,它们将永远使用这个 bind-xml 元素设定的名称。
我不再详细列出这个例子的测试程序,因为数据绑定部分和上一个例子相同。以下是用一些示例数据生成的 XML 文档:
<?xml version="1.0"?> <route from="SEA" to="LAX"> <flight carrier="AR" depart="6:23a" arrive="8:42a" number="426"/> <flight carrier="CA" depart="8:10a" arrive="10:52a" number="833"/> <flight carrier="AR" depart="9:00a" arrive="11:36a" number="433"/> </route> |
回页首
对象引用
现在可以为处理完整的航班时刻表做最后的准备了。您还需要增加三个 bean:
-
AirportBean用于用于机场信息 -
CarrierBean用于航线信息 -
TimeTableBean把一切组合起来
为了保持趣味性,除了上一个例子(参阅 处理集合)中用到的 RouteBean 和 FlightBean 之间的从属关系,您还要在 bean 之间增加一些联系。
连接 bean
要增加的第一个联系是修改 FlightBean ,让它直接引用班机信息,而不再仅仅用代码标识班机。以下是对 FlightBean 的修改:
public class FlightBean
{
private CarrierBean m_carrier;
...
public void setCarrier(CarrierBean carrier) {
m_carrier = carrier;
}
public CarrierBean getCarrier() {
return m_carrier;
}
...
} |
然后对 RouteBean 做同样的修改,让它引用机场信息:
public class RouteBean
{
private AirportBean m_from;
private AirportBean m_to;
...
public void setFrom(AirportBean from) {
m_from = from;
}
public AirportBean getFrom() {
return m_from;
}
public void setTo(AirportBean to) {
m_to = to;
}
public AirportBean getTo() {
return m_to;
}
...
} |
我没有给出新增 bean 自身的代码,因为和前面的代码相比没有什么新鲜的东西。您可以从下载文件 code.jar 中找到完整的示例代码(请参阅 参考资料)。
映射引用
您可能需要映射文档的其他一些特性,以支持编组和解组的对象之间的引用。清单 7 给出了一个完整的映射:
清单 7. 完整的时刻表映射
<!DOCTYPE databases PUBLIC "-//EXOLAB/Castor Mapping DTD Version 1.0//EN" "http://castor.exolab.org/mapping.dtd"> <mapping> <description>Reference mapping example</description> <class name="TimeTableBean"> <map-to xml="timetable"/> <field name="carriers" type="CarrierBean" collection="collection"> <bind-xml name="carrier"/> </field> <field name="airports" type="AirportBean" collection="collection"> <bind-xml name="airport"/> </field> <field name="routes" type="RouteBean" collection="collection"> <bind-xml name="route"/> </field> </class> <class name="CarrierBean" identity="ident" auto-complete="true"> <field name="ident"> <bind-xml name="ident" node="attribute"/> </field> </class> <class name="AirportBean" identity="ident" auto-complete="true"> <field name="ident"> <bind-xml name="ident" node="attribute"/> </field> </class> <class name="RouteBean"> <field name="from" type="AirportBean"> <bind-xml name="from" node="attribute" reference="true"/> </field> <field name="to" type="AirportBean"> <bind-xml name="to" node="attribute" reference="true"/> </field> <field name="flights" type="FlightBean" collection="collection"> <bind-xml name="flight"/> </field> </class> <class name="FlightBean" auto-complete="true"> <field name="carrier"> <bind-xml name="carrier" node="attribute" reference="true"/> </field> <field name="departureTime"> <bind-xml name="depart" node="attribute"/> </field> <field name="arrivalTime"> <bind-xml name="arrive" node="attribute"/> </field> </class> </mapping> |
除了新增的 bean 之外,这里有一个重要的变化,就是增加了 identity 和 reference 属性。 class 元素的 identity 属性,通知 Castor 这个命名属性是该类实例的唯一标识符。在这里,我把 CarrierBean 和 AirportBean 的 ident 属性定义成它们的标识符。
bind-xml 元素的 reference 属性,提供了对于该映射 Castor 所需要的另一部分链接信息。 reference 设为 true 的映射告诉 Castor 编组和解组引用对象的标识符,而不是对象本身的副本。从 RouteBean 链接 AirportBean (表示航线的起止点)的引用,从FlightBean 链接 CarrierBean 的引用,都使用了这种方法。
当 Castor 使用这种类型的映射解组数据时,它自动把对象标识符转化为对实际对象的引用。您需要保证标识符的值确实是唯一的,甚至不同类型的对象之间也要保证这种唯一性。对于本例中的数据,这一点不成问题:飞机的标识符是两个字符,而机场的标识符是三个字符,永远不会冲突。如果 确实有潜在冲突的可能性,只要在所代表的对象类型的每个标识符加上唯一的前缀,就可以很容易地避免这种问题。
编组后的时刻表
这个例子的测试代码没有新东西,只是增加了一些示例数据。清单 8 给出了编组形成的 XML 文档:
清单 8. 编组的时刻表
<?xml version="1.0"?> <timetable> <carrier ident="AR" rating="9"> <URL>http://www.arcticairlines.com</URL> <name>Arctic Airlines</name> </carrier> <carrier ident="CA" rating="7"> <URL>http://www.combinedlines.com</URL> <name>Combined Airlines</name> </carrier> <airport ident="SEA"> <location>Seattle, WA</location> <name>Seattle-Tacoma International Airport</name> </airport> <airport ident="LAX"> <location>Los Angeles, CA</location> <name>Los Angeles International Airport</name> </airport> <route from="SEA" to="LAX"> <flight carrier="AR" depart="6:23a" arrive="8:42a" number="426"/> <flight carrier="CA" depart="8:10a" arrive="10:52a" number="833"/> <flight carrier="AR" depart="9:00a" arrive="11:36a" number="433"/> </route> <route from="LAX" to="SEA"> <flight carrier="CA" depart="7:45a" arrive="10:20a" number="311"/> <flight carrier="AR" depart="9:27a" arrive="12:04p" number="593"/> <flight carrier="AR" depart="12:30p" arrive="3:07p" number="102"/> </route> </timetable> |
回页首
使用数据
现在,时刻表中的所有数据都最终完成了,简单地看一看如何在程序中处理它们。使用数据绑定,您已经建立了时刻表的数据结构,它由几种类型的 bean 组成。处理数据的应用程序代码可以直接使用这些 bean。
比方说,假设您要查看在西雅图和洛杉矶之间有哪些航班可供选择,并且要求班机至少具备指定的最低品质评价级别。清单 9 给出了使用数据绑定 bean 结构获取这些信息的基本代码(完整的细节请参阅从 参考资料下载的源文件)。
清单 9. 航班查找程序代码
private static void listFlights(TimeTableBean top, String from,
String to, int rating) {
// find the routes for outbound and inbound flights
Iterator r_iter = top.getRoutes().iterator();
RouteBean in = null;
RouteBean out = null;
while (r_iter.hasNext()) {
RouteBean route = (RouteBean)r_iter.next();
if (route.getFrom().getIdent().equals(from) &&
route.getTo().getIdent().equals(to)) {
out = route;
} else if (route.getFrom().getIdent().equals(to) &&
route.getTo().getIdent().equals(from)) {
in = route;
}
}
// make sure we found the routes
if (in != null && out != null) {
// find outbound flights meeting carrier rating requirement
Iterator o_iter = out.getFlights().iterator();
while (o_iter.hasNext()) {
FlightBean o_flight = (FlightBean)o_iter.next();
if (o_flight.getCarrier().getRating() >= rating) {
// find inbound flights meeting carrier rating
// requirement, and leaving after outbound arrives
int time = timeToMinute(o_flight.getArrivalTime());
Iterator i_iter = in.getFlights().iterator();
while (i_iter.hasNext()) {
FlightBean i_flight = (FlightBean)i_iter.next();
if (i_flight.getCarrier().getRating() >= rating
&&
timeToMinute(i_flight.getDepartureTime())
> time) {
// list the flight combination
printFlights(o_flight, i_flight, from, to);
}
}
}
}
}
}
|
您可以尝试使用前面 清单 8中的数据。如果您询问从西雅图(SEA)到洛杉矶(LAX)、级别大于或等于 8 的班机,就会得到如下的结果:
Leave SEA on Arctic Airlines 426 at 6:23a return from LAX on Arctic Airlines 593 at 9:27a Leave SEA on Arctic Airlines 426 at 6:23a return from LAX on Arctic Airlines 102 at 12:30p Leave SEA on Arctic Airlines 433 at 9:00a return from LAX on Arctic Airlines 102 at 12:30p |
与文档模型的比较
这里我不准备全面讨论使用 XML 文档模型的等价代码,那太复杂了,足以单独成章。解决这个问题最简单的方式,可能是首先解析carrier 元素,创建每个标识符代码到相应对象之间的映射链接。然后使用和 清单 9中示例代码类似的逻辑。和使用 bean 的例子相比,每一步都更加复杂,因为代码使用的是 XML 成分而不是真正的数据值。性能可能更糟——只对数据进行少量的操作还不算是问题,但是如果数据处理是应用程序的核心,这就会成为一个主要的焦点。
如果在 bean 和 XML 的映射中使用更多的数据类型转换,差别会更大(无论从代码的复杂性还是从性能的角度看)。比方说,假设您使用很多的航班时间,可能希望把文本时间转化成一种更好的国际化表示(如一天内的分钟数,参见 清单 9)。您可以选择为文本和国际化格式定义可以替换的 get 和 set 方法(让映射仅仅使用文本形式),也可以定义一个定制的org.exolab.castor.mapping.FieldHandler 实现让 Castor 使用这些值。保留时间值的内部形式,可以避免匹配清单 9 中的航班时进行转换,也许还能加快处理速度。
除了本文中所述的之外—— FieldHandler 只是一个例子,Castor 还有许多迷人的特性。但愿这些例子和讨论使您能够初步领略这个框架的强大功能和灵活性。 我相信,您将和我一样发现 Castor 非常有用也非常有趣。
回页首
结束语
对于使用 XML 交换数据的应用程序,数据绑定是文档模型很好的替代品。它简化了编程,因为您不必再按照 XML 的方式思考。相反,您可以直接使用代表应用程序所用数据含义的对象。与文档模型相比,它还潜在地提供了更好的内存和处理器使用效率。
本文中,我使用 Castor 框架展示了一些越来越复杂的数据绑定的例子。所有这些例子都使用所谓的 直接数据绑定:开发人员根据数据定义类,然后把数据映射到 XML 文档结构。下一篇文章中,我将探讨另一种方法: 模式数据绑定,利用模式(如 DTD、XML 模式或者其他的类型)生成和那个模式对应的代码。
Castor 同时支持模式方法和本文中介绍的直接绑定,您将在以后看到更多的 Castor 应用。我还关注着 JSR-031 Java 数据绑定标准的进展,并对这些方法的性能进行比较。更多了解 Java 中的 XML 数据绑定这个领域,请速来访问离您最近的 IBMdeveloperWorks。
参考资料
- 请在 讨论论坛参与本文的讨论。(您也可以单击本文顶部或底部的 讨论来访问论坛。)
- 了解 Castor 的最新进展,请访问该项目的 主页。
- 回顾作者以前的 developerWorks文章,包括 Java XML 文档模型的 性能(2001 年 9 月)和 用法(2002 年 2 月)的比较。
- 其他作者对使用 Castor XML 数据绑定的看法,阅读 Scott L. Bain 的论文 “ XML Data Binding with Castor”以及 Dion Almaer 在 OnJava.com上的文章 “ XML Data Binding with Castor”。
- Sam Brodkin 的 JavaWorld文章,“ Use XML data binding to do your laundry”,比较了JAXB 和 Castor XML 数据绑定。
- Jacek Kruszelnicki 的 JavaWorld文章,“ Persist data with Java Data Objects, Part 2”,比较了 Castor 和 Sun JDO 的数据绑定和数据存储。
- 最后,看一看 IBM WebSphere Studio Application Developer,这是一个创建、测试和部署 J2EE 应用程序简单易用的集成开发环境,包括从 DTD 和模式生成 XML 文档。
- 其他链接
- 阅读并下载 Java Architecture for XML Binding(JAXB) 。
- 进一步了解 JSR 31 - XML Data Binding Specification。
关于作者
Dennis Sosnoski 是西雅图地区 Java 咨询公司 Sosnoski Software Solutions, Inc.的创始人和首席顾问,他是 J2EE、XML 和 Web 服务支持方面的专家。他已经有 30 多年专业软件开发经验,最近几年他集中研究服务器端的 Java 技术。Dennis 经常在全国性的会议上就 XML 和 Java 技术发表演讲,您可以通过 [email protected]与 Dennis 联系。
http://www.ibm.com/developerworks/cn/xml/x-bindcastor/