concepts阅读总结5——堆表
1、方案对象概述:
表:
当oracle创建一个表的时候,数据库会在对应的表空间中为此表分配数据段,具体如何控制数据段的分配和使用的呢?有两个方面的控制:
* 通过设置段的存储参数,控制其空间分配方式(如开始分配多少个数据扩展,这个表总共可以用多少个数据扩展)
* 通过控制数据段内的PCTFREE, PCTUSED 两个参数,控制数据段中的数据扩展内的数据块的可用空间的大小。
Oracle 在存储簇表(clustered table)的数据时统一使用为其所属簇(cluster)创建的数据段(data segment),而不是为每个簇表单独创建数据段。创建或修改簇表时不能为其设定存储参数(storage parameter)。一个簇内的所有簇表都使用此簇的存储参数来控制其空间分配。
2、表中行的存储:
Oracle 使用一个或多个行片断(row piece)来存储表的每一行数据的前255列。当一个数据块(data block)可以容纳一个完整的数据行时(且表的列数小于等于 256),那么此行就可以使用一个行片断来存储。当插入(insert)一个数据行,或更新(update)已有数据行时,数据行容量大于数据块容量,那么 Oracle 将使用多个行片断来存储此行。大多数情况下,每个数据行只存储于一个行片断中,且在同一数据块内。当 Oracle 必须使用多个行片断来存储同一数据行时(且每个行片断位于不同的数据块内),此行将在多个数据块间构成行链接(Row Chaining)。
当一个表超过 255 列时,每行第255列之后的数据将作为一个新的行片断(row piece)存储在相同的数据块(data block)中,这被称为块内链接(intra-block chaining)。由多个行片断组成的行进行块内链接时,使用各行片断的 rowid 进行链接。当一个行为块内链接时,用户可以从同一数据块中访问此行的全部数据。如果一个数据行位于同一数据块内,那么访问此行不会影响 I/O 性能,因为访问此行不会带来额外的 I/O 开销。
无论链接(chained)或非链接(unchained)的行片断,都包含一个行头(row header),及此行部分或全部的数据。 一行内某一列的数据也有可能跨多个行片断(row piece),甚至跨多个数据块(data block)。图5-3 显示了行片断的格式。
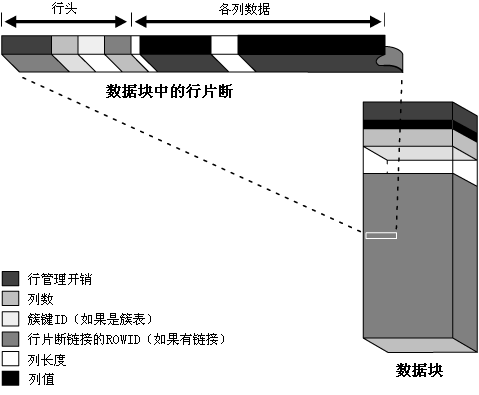
图5-3 显示了数据块(data block)中的一个行片断(row piece)。一个行片断由行头(row header)及列数据(column data)构成。列数据部分包含了各列的列长(column length)及列值(column value)。而行头内包含以下内容:行管理开销(row overhead),列数,簇键ID(cluster key ID)(如果是簇表),行片断链接(chained row pieces)的ROWID(如果有链接)。
行头(row header)位于行数据之前,包含以下信息:
- 行管理开销(row overhead)
- 行片断链接(chained row pieces)的ROWID(如果有链接)
- 列数
- 簇键ID(cluster key ID)(如果是簇表)
如果一行能被存储于一个数据块(data block)中,那么其行头(row header)所需容量将不少于 3 字节(byte)。在行头信息之后依次储存的是各列的列长(column length)及列值(column value)。列长存储于列值之前,如列值不超过 250 字节,那么 Oracle 使用 1 字节存储其列长;如列值超过 250 字节,则使用 3 字节存储其列长。列数据(column data)所需的存储空间取决于此列的数据类型(datatype)。如果某列的数据类型为变长(variable length)的,那么存储此列值所需的空间可能会随着数据更新而增长或缩小。
为了节约存储空间,如果某列值为空(null),那么数据库中只存储其列长(column length)(值为 0),而不存储任何数据。对位于一行末尾的空列值(trailing null column),数据库中将列长也忽略不予存储。
提示:
每行还要占用数据块头(data block header)中行目录区(row directory)的 2 字节(byte)空间。
簇表(clustered)内的行需要存储与非簇表(nonclustered)行相同的信息。除此之外,簇表内各行还需要存储其所属的簇键(cluster key)。
另见:
- Oracle 数据库管理员指南 了解簇表及簇表内的行
- “簇概述”
- “行链接及行迁移”
- “空值的含义”
- “行目录区”
行片断的 rowid Oracle 使用 rowid 记录每个行片断(row piece)的存储位置和地址。每个行片断得到一个 rowid 之后,这个值将会保持不变,直到其所属行被删除(delete)或经过 Oracle 工具导出并再次导入。对于簇表(clustered table)来说,如果某行的簇键值(cluster key value)发生改变,那么此行除了保存原有的 rowid 之外,还将为新簇键值存储一个额外的 rowid 指针(pointer)。
列顺序一个表内所有行的列顺序(column order)都是一致的。列的存储顺序通常和 CREATE TABLE 语句中定义的列顺序是一致的,但是也有例外情况。例如,如果一个表含有数据类型(datatype)为 LONG 的列,那么 Oracle 会将此列存储在行的末尾。当用户修改了表定义向其中添加了新的列,这些列也将存储在行的末尾。
表压缩,实际上是压缩的数据块内重复的值,一个包含压缩数据的数据块,同时会包含解压缩的数据,因为这样可以防止再去访问别的数据块,防止增加额外I/O。相同的数据只有一份,放在数据块头部的一个叫符号表(symbol table)里。然后再在每一个用到这个数据的地方加一个指向这个符号表内对应数据的指针。
可以被压缩的数据库对象有表和物化视图(materialized view)。对于分区表(partitioned table),用户可以选择压缩部分或全部分区(partition)。表空间(tablespace),表,及分区表都可以被设定为压缩模式。如果在表空间级作了设定,那么在此表空间内创建的表默认都以压缩模式存储。用户也可以修改一个表(表空间,或分区)的压缩属性,在修改后插入的数据将按照新的模式存储。这样,一个表或分区可以同时包含压缩及常规的数据块(data block)。有时使用表压缩反而会导致数据块内数据容量增长,因此利用上述特性能避免这种压缩带来的容量增长。
4、临时表
临时表使用临时段来存储数据,与永久表不同,临时表只有在进行insert(或者create table as select)的时候才进行段的分配,之前只是声明了临时表,这样一来,在insert之前执行的任何DML操作(select delect update)都是对空表进行的不起作用的操作。
只有当没有会话与临时表绑定的时候,才能进行对临时表执行DDL操作,(alter table ,drop table ,create table等)。对一个临时表进行insert 操作的时候,就绑定了这个临时表。在会话结束时对临时表执行的 TRUNCATE 语句将解除(unbound)会话与此临时表的绑定。对于与事务相关的(transaction-specific)临时表行 COMMIT 或 ROLLBACK 将解除会话与此临时表的绑定。
在事务(transaction)结束时与事务相关的(transaction-specific)临时表(temporary table)所使用的临时段(temporary segment)将被回收。同样的,在会话(session)结束时与会话相关的(session-specific)临时表所使用的临时段也将被回收。
5、freelist
使用MSSM 表空间时,Oracle 会在自由列表(freelist)中为有自由空间的对象维护HWM 一些的块。注意freelists 组和freelist 组在ASSM 表空间中根本就没有;仅MSSM 表空间使用这个技术。
每个对象都至少有一个相关的freelist,使用块时,可能会根据需要把块放在freelist 上或者从freelist 删除。需要说明的重要一点是,只有位于HWM 以下的对象块才会出现在freelist 中。仅当freelist 为空时才会使用HWM 之上的块,此时Oracle 会推进HWM,并把这些块增加到freelist 中,采用这种方式,Oracle 会延迟到不得已时才增加对象的HWM。
一个对象可以有多个freelist。如果预计到会有多个并发用户在一个对象上执行大量的INSERT 或UPDATE 活动,就可以配置多个freelist,这对性能提升很有好处(但是可能要以额外的存储空间为代价)。根据需要配置足够多的freelist 非常重要。
对于一个表来说,你可能想确定最多能有多少个真正的并发插入或更新(这需要更多空间)。这里我所说的“真正的并发”是指,你认为两个人在同一时刻请求表中一个自由块的情况是否频繁。这不是对重叠事务的一种量度;而是量度多少个会话在同时完成插入,而不论事务边界是什么。你可能希望对表的并发插入有多少, freelist 就有多少,以此来提高并发性。只需把freelist 设置得相当高,然后就万事大吉了,是这样吗?当然不是,哪有这么容易。
使用多个freelist 时,有一个主freelist,还有一些进程freelist。如果一个段只有一个freelist,那么主freelist 和进程freelist 就是这同一个自由列表。如果你有两个freelist,实际上将有一个主freelist和两个进程freelist。对于一个给定的会话,会根据其会话ID 的散列值为之指定一个进程freelist。目前,每个进程freelist 都只有很少的块,余下的自由块都在主freelist 上。使用一个进程freelist 时,它会根据需要从主freelist 拉出一些块。如果主freelist 无法满足空间需求,Oracle 就会推进HWM,并向主freelist 中增加空块。过一段时间后,主freelist 会把其存储空间分配多个进程freelist(再次说明,每个进程freelist 都只有为数不多的块)。因此,每个进程会使用一个进freelist。它不会从一个进程freelist 到另一个进程freelist 上寻找空间。这说明,如果一个表上有10 个进程freelist,而且你的进程所用的进程freelist 已经用尽了该列表中的自由缓冲区,它不会到另一个进程freelist 上寻找空间,即使另外9 个进程freelist 都分别有5 块(总共有45 个块),此时它还是会去求助主freelist。假设主freelist 上的空间无法满足这样一个自由块请求,就会导致表推进HWM,或者如果表的HWM 无法推进(所有空间都已用),就要扩展表的空间(得到另一个区段)。然后这个进程仍然只使用其freelist上的空间(现在不再为空)。使用多个freelist 时要有所权衡。一方面,使用多个freelist 可以大幅度提升性能。另一方面,有可能导致表不太必要地使用稍多的磁盘空间。你必须想清楚在你的环境中哪种做法麻烦比较小。
不要低估了FREELISTS 参数的用处,特别是在Oracle 8.1.6 及以后版本中,你可以根据意愿自由地将其改大或改小。可以把它修改为一个大数,从而与采用传统路径模式的SQL*Loader 并行完成数据的加载。这样可以获得高度并发的加载,而只有最少的等待。加载之后,可以再把这个值降低为某个更合理的平常的数。将空间改小时,现有的多个freelist 上的块要合并为一个主freelist。