hibernate关系映射——继承映射
上篇总结的是关联映射,今天学习继承映射。
继承映射也有三种方式:1. 一棵继承树映射一张表 2. 每个类对应一张表 3. 每个子类对应一张表
下面以Animal父类和Pig、Bird两个子类为例来学习hibernate的继承映射。
1. 一棵继承树对应一张表
这种映射方式只需要为基类Animal创建一张表。
表中要提供与所有子类属性对应的字段,此外,还要额外增加一个鉴别字段,用于区分子类的具体类型,即图中的Type字段。
在映射文件中表示:
<classname="Animal" table="t_animal" lazy="false">
<idname="id">
<generatorclass="native"/>
</id>
<discriminatorcolumn="type" type="string"/> <!-- 鉴别字段 -->
<propertyname="name"/>
<propertyname="sex"/>
<subclass name="Pig"discriminator-value="P"> <!-- P为Pig的鉴别值 -->
<propertyname="weight" ></property>
</subclass>
<subclass name="Bird"discriminator-value="B"> <!--B为Bird的鉴别值 -->
<propertyname="height"></property>
</subclass>
</class>
这种方式优点:因为数据存在一张表中,所以插入、查询速度快,执行效率高
缺点:存在大量冗余字段,不适合大数据量
2.每个类对应一张表
父类以及所有子类分别生成一张表。
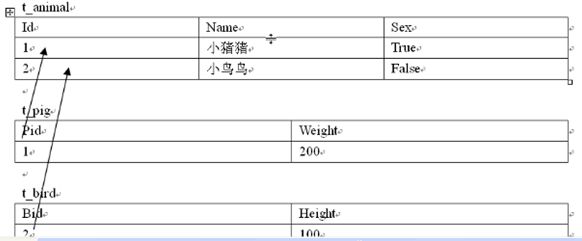
通过主外键关联控制子类和父类的对应关系。在两个子类中分别以Pid和Bid作为主键,同时还作为外键参照t_animal表。
在映射文件中表示为:
<classname="Animal" table="t_animal">
<idname="id">
<generatorclass="native"/>
</id>
<propertyname="name"/>
<propertyname="sex"/>
<joined-subclassname="Pig" table="t_pig">
<keycolumn="pid"/>
<propertyname="weight"/>
</joined-subclass>
<joined-subclassname="Bird" table="t_bird">
<keycolumn="bid"/>
<propertyname="height"/>
</joined-subclass>
</class>
<joined-sbclass>元素用于映射子类
此种映射方式的优点: 层次清晰,没有冗余
缺点:类的继承层次非常多的时候,表非常多,当添加和查询数据时,需要关联很多张表。
3.每个具体类对应一张表
只为每个子类建立表,表中包含了从父类继承的属性以及自己的特有属性
在映射文件中表示为:
<classname="Animal" table="t_animal"abstract="true" > <!--设置abstract="true",不创建t_animal表,创建出来也没有意义 -->
<idname="id">
<generator class="assigned"/> <!-- assigned为自定义主键方式 -->
</id>
<propertyname="name"/>
<propertyname="sex"/>
<union-subclassname="Pig" table="t_pig">
<propertyname="weight"/>
</union-subclass>
<union-subclassname="Bird" table="t_bird">
<propertyname="height"/>
</union-subclass>
</class>
此种映射方式的缺点:如果每个子类设置主键自增,在添加数据时会报错。每个子类都属于animal,所以,必须保证所有子类主键不重复,即pig或者bird中都不能含有互相重复的主键值。
综上所述:
当子类属性不是很多时,优先考虑1继承树对应一张表映射
当子类属性非常多,且对性能要求很严格时,优先考虑2每个类对应一张表映射。