XML简介
XML(Extensible Markup Lanaguage),可扩展标记语言,是标准通用标记语言(Standard Generalized Markup Language, SGML)的一个子集,SGML功能强大,是可以定义标记语言的元语言。将强大的SGML的通用性和HTML的易用性结合起来便诞生了适合在Web中应用的XML语言。
1、起源
1998年2月W3C(万维网联盟)发布了XML1.0标准,其目的是为了在Web上能以现有的超文本标记语言(HTML)的使用方式提供、接收和处理通用的SGML。XML是SGML的一个简化子集,它以一种开放的自我描述的方式定义了数据结构。在描述数据内容的同时能突出对结构的描述,从而体现出数据与数据之间的关系。
2、SGML、HTML和XML
SGML是在web发明以前就早已存在的使用标记来描述文档资料的通用语言,它是一种定义标记语言的元语言。HTML和XML都是从SGML发展而来的标记语言。因此,它们有一些共同的特点,如相似的语法和标记的使用。不过,HTML是在SGML定义下的一个描述性语言,只是SGML的一个应用,其DTD作为标准被固定下来,而XML是SGML的一个简化版本,是SGML的一个子集,严格意义上来说,XML仍是SGML。
如下面的例子:
HTML文档将数据、页面排版以及页面的表现形式混合在一起,如果要增加新的数据,就要调整数据的排版与显示方式。当从其他地方获得数据,一旦放入html文档中,整个数据就会被打乱,数据和html标记混合在一起,数据本身变得无法辨析。XML无法描述页面的排版和表现形式,只是用来描述数据和数据的结构。XML将数据和数据的显示分开,我们可以为这些数据设计不同的显示和表现形式(可以对其应用不同的样式表),而数据本身无需做任何修改。XML使数据能够独立于应用系统,数据可以重用,一份数据可以用于不同的场合。有时XML文档被看做文档的数据刻画和数据的文档化。HTML文档格式非常松散,导致html文档解析的复杂性,也造成了浏览器兼容的问题。XML对文档的格式制定了严格的标准,凡是符合这一标准的xml文档就是格式良好的xml文档(Well-Formed XML Documents)。
3、XML结构
XML中开始标签和结束标签成对使用。空元素标签必须要用斜杠关闭。所有的标签都区分大小写。XML中所有的标签成对出现,合理嵌套。所有标签的属性值都必须用单引号或双引号括起来。XML中有且只能有一个根元素。每一个xml文档都有一个逻辑结构和一个物理结构。
3.1 物理结构
物理上而言,文档由称为 实体(entities)的存储单元组成,实体都具有内容并且都通过实体的名字进行标识(文档实体和外部DTD子集除外),实体可以是一段文字、一个文件、一个数据库记录或其他包含数据的项目。一个实体可以引用其他的实体从而将他们包含在文档中,文档开始于“根(root)”或文档实体(document entity)。格式良好的xml文档形成了一种层次结构,而这个树的根就是文档实体,与其他实体不同,文档实体没有名字,只是用于表示文档树的根,xml文档的根元素被称为文档元素(document element),它和在其外部出现的处理指令、注释等作为文档实体的子节点,而根元素和其内部的子元素也是一棵树。
实体可以包含已分析(parsed)或未分析的(unparsed)数据。已分析的数据由字符组成,其中一些字符组成字符数据,另一些字符组成标记。已分析的实体(parsed entity)内容被称为它的替换文本,这个文本被看成是文档整体的一部分。在xml处理器分析xml文档时,凡是文档中出现引用已分析实体的地方,都将被该实体的内容替换。
未分析的实体(unparsed entity)是一种资源,它的内容可以是也可以不是文本,并且,如果是文本的话,可以不是xml文本,每一个未分析的实体有一个相关联的用名字标识的记号(notation)。除了要求xml处理器能向应用程序提供可用的实体和记号的标识符之外,xml对未分析的实体内容不做任何限制。已分析的实体以实体引用的方式通过名字来调用;未分析的实体通过ENTITY或ENTITIES属性中给出的名字来调用。
3.2 逻辑结构
逻辑上而言,文档由声明、元素、注释、字符引用和处理指令组成,在文档中,所有这些都是通过显示的标记(markup)来指明的。
XML标记(markup)包括开始标签(tag)、结束标签、空元素标签、实体引用、字符引用、注释、CDATA段定界符、文档类型声明、处理指令、XML声明、文本声明以及任何在文档实体顶层的空白(即在文档元素之外,且不在任何其它的标记内部)。其他所有非标记的文本组成文档的字符数据。
4、XML组成
4.1 XML声明
XML文档总是以一个XML声明开始,其中指明所用的XML版本、文档的编码、文档的独立性信息。格式如下:
<?xml 版本信息 [编码信息] [文档独立性信息]?>
XML声明必须位于xml文档的第一行,之前不能有任何字符。
4.1.1 版本声明
<?xml version=”1.0”?>
4.1.2 文档编码声明
在XML声明中还可以加上文档编码信息,默认是UTF-8,如果要使用中文,我们可以在声明中加上encoding=”gb2312”(gb2312是中文字符集),如下所示:
<?xml version=1.0 encoding=”gb2312”>
4.1.3 独立文档声明
如果我们的文档不依赖于外部文档,在XML声明中,我们可以通过standalone=”yes”来声明这个文档是独立的文档,如果文档依赖于外部文档,可以通过standalone=”no”来声明,完整的XML声明如下所示:
<?xml version=”1.0” encoding=”gb2312” standalone=”yes”>
4.2 文档类型声明
DTD(Document Type Definition),文档类型定义。XML从SGML继承了用于定义语法规则的DTD机制,但DTD本身并不要求遵循XML规则,几乎所有的XML应用都是使用DTD来定义的,HTML就有一个标准的DTD文件,所以其组织结构和所有的标签都是固定的。DTD文件本事也是一个文本文件,通常用“.dtd”作为其扩展名。通过文档类型声明,指出XML文档所用的DTD,文档类型声明有两种形式:一种是声明DTD在一个外部的文件中,如下:
<!DOCTYPE greeting SYSTEM “hello.dtd”>
greeting 指明xml文档根元素的名称,SYSTEM指明是私有的dtd文件
一种是直接在XML文档中给出DTD,如下:
4.3.1 元素组成
在xml中,元素由开始标签、元素内容和结束标签构成,对于空元素,由空元素标签构成。每一个元素有一个用名字标识的类型,同时它可以有一个属性说明集,每一个属性说明有一个名字和一个值。
4.3.2 元素命名
在给元素命名的时候要注意,以xml或其他任何匹配((‘X’|’x’)(‘M’|’m’)(‘L’|’l’))的字符串开头的名字,被保留用于XML规范的当前版本或后续版本的标准化。此外,在给元素命名的时候,还要遵守以下规范:
1) 名称只能以字母、下划线(_)或者冒号(:)开头;
2) 名称中可以包含字母、数字、下划线以及其它在XML标准中允许的字符;
3) 名称中不能包含空格;
4) 名称中尽可能不要使用冒号(:),因为冒号在名称空间中被用于分割名称空间的前缀和本地部分。
4.3.3 元素的四种形式
1) 空元素
<student/>
2) 带有属性的空元素
<student name=”张三” age=”18”/>
3) 带有内容的元素
<student>
这是一个学生的信息
<name>张三</name>
<age>18</age>
</student>
4) 带有内容和属性的元素
<student name=”张三”>
<age>18</age>
</student>
4.3.4元素和标签
元素和标签具有不同的含义。元素是指开始标签、结束标签以及两者之间的一切内容,包括属性、文本、注释以及子元素。标签是一对尖括号(< >)和两者之间的内容,包括元素名和所有属性。例如:<font color=”blue”>是一个标签,</font>也是一个标签;而<font color=”blue”>Hello World</font>则是一个元素。
4.3.5 元素的内容
4.3.5.1 元素内容的组成
元素的内容可以包含子元素、字符数据、字符引用和实体引用、CDATA段。
子元素本身也是元素,被嵌套在上层元素之内,子元素是相对于父元素而言的,如果子元素还嵌套了其他元素,那么它同时也是父元素。
在一个元素的内容中,字符数据可以是不包括任何标记的起始定界符和CDATA段的结束定界符的任意字符串,也就是说在元素的内容中,字符数据不能有和号(&)和小于号(<),也不能有字符串“]]>”。在CDATA段中,字符数据可以是不包括CDATA段的结束定界符的任意字符串。在字符数据中,不能有和号(&)和小于号(<),因为未经处理的小于号(<)与和号(&)在XML文本中往往被解释为标记的起始定界符(存在例外的情况,见CDATA段)。
4.3.5.2 预定义实体引用
在XML中,提供了五个预定义的实体引用,分别引用XML文档中的5个特殊字符:小于号(<)、大于号(>)、双引号(“)、单引号(‘)、和号(&)。这5个特殊字符也可以通过字符引用的方式去引用。
字符引用和预定义实体引用都是以一个和号(&)开始并以一个分号(;)结束,如果用的是字符引用,需要在和号(&)之后加上一个井号(#),之后是所需字符的十进制代码或十六进制代码(ISO/IEC 10646字符集中字符编码),如果用的是预定义实体引用,在和号(&)之后写上字符的助记符。
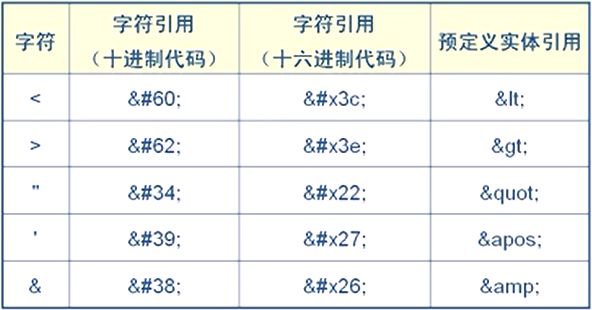 只要在ISO/IEC 10646字符集中的字符都可以通过其字符编码来引用,方式同上。
只要在ISO/IEC 10646字符集中的字符都可以通过其字符编码来引用,方式同上。
4.3.5.2 CDATA段
CDATA段中包含的都是纯字符数据,在字符数据可以出现的任何地方都可以使用CDATA段。CDATA段主要用于需要将整个文本解释为字符数据而不是标记的情况下。CDATA段中的内容不被XML处理器分析,所以可以在其中包含任意的字符。例如,在XML文档中,需要包含java代码,而java代码中可能存在着小于号、大于号、单引号、双引号、和号这些特殊字符,这个时候,CDATA段就派上用场了。
CDATA段以字符串”<!CDATA[”开始,以字符串”]]>”结束。
4.4 注释
在XML文档中,注释可以出现在文档中其它标记之外的任何位置,另外,它们还可以在文档类型声明中语法(grammar)允许的地方出现。XML的注释和HTML的注释类似,都是以<!—开始,以-->结束。位于<!—和-->之间的数据将被XML处理器忽略。如<!—This is a comment-->。注释用于对文档中的内容起一个说明作用。使用注释时,要注意一下五点:
1) 注释部分不能出现在XML声明之前,XML声明必须是文档最前面的部分。下面的情况是不允许的:
 2)
注释不能出现在标记中。
2)
注释不能出现在标记中。
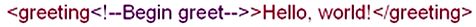 3)
注释可以包围和隐藏标记,但是要注意的是,在注释掉标记之后,要保证剩余的文本仍然是一个结构完整的XML文档,如:
3)
注释可以包围和隐藏标记,但是要注意的是,在注释掉标记之后,要保证剩余的文本仍然是一个结构完整的XML文档,如:
4)
字符串”--”(双连字符)不能再注释中出现。下面的例子是非法的:
<!--This is a great example--Hello, World-->
5) 在XML中,不允许注释以--->结尾。下面的例子是非法的:
<!--This is a great example--->
4.5 处理指令
处理指令(Processing Instructions,简称PIs)允许文档中包含由应用程序来处理的指令。在XML文档中,有可能会包含一些非XML格式的数据,这些数据XML处理器无法处理,我们就可以通过处理指令来通知其它应用程序来处理这些数据。
处理指令(PI)的语法和XML声明类似,以<?开始,以?>结束。一个常见的使用样式表单的处理指令如下所示:
<?xml-stylesheet href=”hello.css” type=”text/css”?>
在开始标记<?后的第一个字符串”xml-stylesheet”叫做处理指令的目标,它必须标识要用到的应用程序,要注意的是对于其它的非W3C定义的处理指令不能以字符串”XML”和”xml”开头,其余的部分是传递给应用程序的字符数据。应用程序从处理指令中取得目标和数据,执行要求的动作。
处理指令的目标可以是要使用的程序的名字,或者是一个类似于xml-stylesheet这样的很多程序可以识别的通用标识符。不同的应用程序支持不同的处理指令,对于不认识的处理指令,大多数应用程序采取忽略的方式进行处理。Xml-stylesheet处理指令总是放在XML声明之后,第一个元素之前。其它的处理指令可以放在除标记的内部和XML声明之前的任何位置。
1、起源
1998年2月W3C(万维网联盟)发布了XML1.0标准,其目的是为了在Web上能以现有的超文本标记语言(HTML)的使用方式提供、接收和处理通用的SGML。XML是SGML的一个简化子集,它以一种开放的自我描述的方式定义了数据结构。在描述数据内容的同时能突出对结构的描述,从而体现出数据与数据之间的关系。
2、SGML、HTML和XML
SGML是在web发明以前就早已存在的使用标记来描述文档资料的通用语言,它是一种定义标记语言的元语言。HTML和XML都是从SGML发展而来的标记语言。因此,它们有一些共同的特点,如相似的语法和标记的使用。不过,HTML是在SGML定义下的一个描述性语言,只是SGML的一个应用,其DTD作为标准被固定下来,而XML是SGML的一个简化版本,是SGML的一个子集,严格意义上来说,XML仍是SGML。
如下面的例子:
HTML: <html> <head> <title>这是一个欢迎的例子</title> <head> <body> 你好,你好! <body> </html> XML: <?xml version=”1.0” encoding=”gb2312”?> <欢迎词> <标题>这是一个欢迎的例子</标题> <内容>你好,你好!</内容> </欢迎词>可以看出HTML的标记都是固定的,而XML的标记都是用户自定义的。因此HTML和XML处在标记语言中的不同层次,XML是创建标记语言的元语言。
HTML文档将数据、页面排版以及页面的表现形式混合在一起,如果要增加新的数据,就要调整数据的排版与显示方式。当从其他地方获得数据,一旦放入html文档中,整个数据就会被打乱,数据和html标记混合在一起,数据本身变得无法辨析。XML无法描述页面的排版和表现形式,只是用来描述数据和数据的结构。XML将数据和数据的显示分开,我们可以为这些数据设计不同的显示和表现形式(可以对其应用不同的样式表),而数据本身无需做任何修改。XML使数据能够独立于应用系统,数据可以重用,一份数据可以用于不同的场合。有时XML文档被看做文档的数据刻画和数据的文档化。HTML文档格式非常松散,导致html文档解析的复杂性,也造成了浏览器兼容的问题。XML对文档的格式制定了严格的标准,凡是符合这一标准的xml文档就是格式良好的xml文档(Well-Formed XML Documents)。
3、XML结构
XML中开始标签和结束标签成对使用。空元素标签必须要用斜杠关闭。所有的标签都区分大小写。XML中所有的标签成对出现,合理嵌套。所有标签的属性值都必须用单引号或双引号括起来。XML中有且只能有一个根元素。每一个xml文档都有一个逻辑结构和一个物理结构。
3.1 物理结构
物理上而言,文档由称为 实体(entities)的存储单元组成,实体都具有内容并且都通过实体的名字进行标识(文档实体和外部DTD子集除外),实体可以是一段文字、一个文件、一个数据库记录或其他包含数据的项目。一个实体可以引用其他的实体从而将他们包含在文档中,文档开始于“根(root)”或文档实体(document entity)。格式良好的xml文档形成了一种层次结构,而这个树的根就是文档实体,与其他实体不同,文档实体没有名字,只是用于表示文档树的根,xml文档的根元素被称为文档元素(document element),它和在其外部出现的处理指令、注释等作为文档实体的子节点,而根元素和其内部的子元素也是一棵树。
实体可以包含已分析(parsed)或未分析的(unparsed)数据。已分析的数据由字符组成,其中一些字符组成字符数据,另一些字符组成标记。已分析的实体(parsed entity)内容被称为它的替换文本,这个文本被看成是文档整体的一部分。在xml处理器分析xml文档时,凡是文档中出现引用已分析实体的地方,都将被该实体的内容替换。
未分析的实体(unparsed entity)是一种资源,它的内容可以是也可以不是文本,并且,如果是文本的话,可以不是xml文本,每一个未分析的实体有一个相关联的用名字标识的记号(notation)。除了要求xml处理器能向应用程序提供可用的实体和记号的标识符之外,xml对未分析的实体内容不做任何限制。已分析的实体以实体引用的方式通过名字来调用;未分析的实体通过ENTITY或ENTITIES属性中给出的名字来调用。
3.2 逻辑结构
逻辑上而言,文档由声明、元素、注释、字符引用和处理指令组成,在文档中,所有这些都是通过显示的标记(markup)来指明的。
XML标记(markup)包括开始标签(tag)、结束标签、空元素标签、实体引用、字符引用、注释、CDATA段定界符、文档类型声明、处理指令、XML声明、文本声明以及任何在文档实体顶层的空白(即在文档元素之外,且不在任何其它的标记内部)。其他所有非标记的文本组成文档的字符数据。
4、XML组成
4.1 XML声明
XML文档总是以一个XML声明开始,其中指明所用的XML版本、文档的编码、文档的独立性信息。格式如下:
<?xml 版本信息 [编码信息] [文档独立性信息]?>
XML声明必须位于xml文档的第一行,之前不能有任何字符。
4.1.1 版本声明
<?xml version=”1.0”?>
4.1.2 文档编码声明
在XML声明中还可以加上文档编码信息,默认是UTF-8,如果要使用中文,我们可以在声明中加上encoding=”gb2312”(gb2312是中文字符集),如下所示:
<?xml version=1.0 encoding=”gb2312”>
4.1.3 独立文档声明
如果我们的文档不依赖于外部文档,在XML声明中,我们可以通过standalone=”yes”来声明这个文档是独立的文档,如果文档依赖于外部文档,可以通过standalone=”no”来声明,完整的XML声明如下所示:
<?xml version=”1.0” encoding=”gb2312” standalone=”yes”>
4.2 文档类型声明
DTD(Document Type Definition),文档类型定义。XML从SGML继承了用于定义语法规则的DTD机制,但DTD本身并不要求遵循XML规则,几乎所有的XML应用都是使用DTD来定义的,HTML就有一个标准的DTD文件,所以其组织结构和所有的标签都是固定的。DTD文件本事也是一个文本文件,通常用“.dtd”作为其扩展名。通过文档类型声明,指出XML文档所用的DTD,文档类型声明有两种形式:一种是声明DTD在一个外部的文件中,如下:
<!DOCTYPE greeting SYSTEM “hello.dtd”>
greeting 指明xml文档根元素的名称,SYSTEM指明是私有的dtd文件
一种是直接在XML文档中给出DTD,如下:
<?xml version=”1.0” encoding=”gb2312” standalone=”yes”?> <!DOCTYPE greeting [ <!ELEMENT greeting (#PCDATA)> ]>4.3 元素
4.3.1 元素组成
在xml中,元素由开始标签、元素内容和结束标签构成,对于空元素,由空元素标签构成。每一个元素有一个用名字标识的类型,同时它可以有一个属性说明集,每一个属性说明有一个名字和一个值。
4.3.2 元素命名
在给元素命名的时候要注意,以xml或其他任何匹配((‘X’|’x’)(‘M’|’m’)(‘L’|’l’))的字符串开头的名字,被保留用于XML规范的当前版本或后续版本的标准化。此外,在给元素命名的时候,还要遵守以下规范:
1) 名称只能以字母、下划线(_)或者冒号(:)开头;
2) 名称中可以包含字母、数字、下划线以及其它在XML标准中允许的字符;
3) 名称中不能包含空格;
4) 名称中尽可能不要使用冒号(:),因为冒号在名称空间中被用于分割名称空间的前缀和本地部分。
4.3.3 元素的四种形式
1) 空元素
<student/>
2) 带有属性的空元素
<student name=”张三” age=”18”/>
3) 带有内容的元素
<student>
这是一个学生的信息
<name>张三</name>
<age>18</age>
</student>
4) 带有内容和属性的元素
<student name=”张三”>
<age>18</age>
</student>
4.3.4元素和标签
元素和标签具有不同的含义。元素是指开始标签、结束标签以及两者之间的一切内容,包括属性、文本、注释以及子元素。标签是一对尖括号(< >)和两者之间的内容,包括元素名和所有属性。例如:<font color=”blue”>是一个标签,</font>也是一个标签;而<font color=”blue”>Hello World</font>则是一个元素。
4.3.5 元素的内容
4.3.5.1 元素内容的组成
元素的内容可以包含子元素、字符数据、字符引用和实体引用、CDATA段。
子元素本身也是元素,被嵌套在上层元素之内,子元素是相对于父元素而言的,如果子元素还嵌套了其他元素,那么它同时也是父元素。
在一个元素的内容中,字符数据可以是不包括任何标记的起始定界符和CDATA段的结束定界符的任意字符串,也就是说在元素的内容中,字符数据不能有和号(&)和小于号(<),也不能有字符串“]]>”。在CDATA段中,字符数据可以是不包括CDATA段的结束定界符的任意字符串。在字符数据中,不能有和号(&)和小于号(<),因为未经处理的小于号(<)与和号(&)在XML文本中往往被解释为标记的起始定界符(存在例外的情况,见CDATA段)。
4.3.5.2 预定义实体引用
在XML中,提供了五个预定义的实体引用,分别引用XML文档中的5个特殊字符:小于号(<)、大于号(>)、双引号(“)、单引号(‘)、和号(&)。这5个特殊字符也可以通过字符引用的方式去引用。
字符引用和预定义实体引用都是以一个和号(&)开始并以一个分号(;)结束,如果用的是字符引用,需要在和号(&)之后加上一个井号(#),之后是所需字符的十进制代码或十六进制代码(ISO/IEC 10646字符集中字符编码),如果用的是预定义实体引用,在和号(&)之后写上字符的助记符。
4.3.5.2 CDATA段
CDATA段中包含的都是纯字符数据,在字符数据可以出现的任何地方都可以使用CDATA段。CDATA段主要用于需要将整个文本解释为字符数据而不是标记的情况下。CDATA段中的内容不被XML处理器分析,所以可以在其中包含任意的字符。例如,在XML文档中,需要包含java代码,而java代码中可能存在着小于号、大于号、单引号、双引号、和号这些特殊字符,这个时候,CDATA段就派上用场了。
CDATA段以字符串”<!CDATA[”开始,以字符串”]]>”结束。
4.4 注释
在XML文档中,注释可以出现在文档中其它标记之外的任何位置,另外,它们还可以在文档类型声明中语法(grammar)允许的地方出现。XML的注释和HTML的注释类似,都是以<!—开始,以-->结束。位于<!—和-->之间的数据将被XML处理器忽略。如<!—This is a comment-->。注释用于对文档中的内容起一个说明作用。使用注释时,要注意一下五点:
1) 注释部分不能出现在XML声明之前,XML声明必须是文档最前面的部分。下面的情况是不允许的:
<!--This is a great example--Hello, World-->
5) 在XML中,不允许注释以--->结尾。下面的例子是非法的:
<!--This is a great example--->
4.5 处理指令
处理指令(Processing Instructions,简称PIs)允许文档中包含由应用程序来处理的指令。在XML文档中,有可能会包含一些非XML格式的数据,这些数据XML处理器无法处理,我们就可以通过处理指令来通知其它应用程序来处理这些数据。
处理指令(PI)的语法和XML声明类似,以<?开始,以?>结束。一个常见的使用样式表单的处理指令如下所示:
<?xml-stylesheet href=”hello.css” type=”text/css”?>
在开始标记<?后的第一个字符串”xml-stylesheet”叫做处理指令的目标,它必须标识要用到的应用程序,要注意的是对于其它的非W3C定义的处理指令不能以字符串”XML”和”xml”开头,其余的部分是传递给应用程序的字符数据。应用程序从处理指令中取得目标和数据,执行要求的动作。
处理指令的目标可以是要使用的程序的名字,或者是一个类似于xml-stylesheet这样的很多程序可以识别的通用标识符。不同的应用程序支持不同的处理指令,对于不认识的处理指令,大多数应用程序采取忽略的方式进行处理。Xml-stylesheet处理指令总是放在XML声明之后,第一个元素之前。其它的处理指令可以放在除标记的内部和XML声明之前的任何位置。