C++类对象内存模型与成员函数调用分析
转自:http://blog.csdn.net/fairyroad/article/details/6376620
C++类对象内存模型是一个比较抓狂的问题,主要是C++特性太多了,所以必须建立一个清晰的分析层次。一般而言,讲到C++对象,都比较容易反应到以下这个图表:
这篇文章,就以这个表格作为分析和行文的策略的纵向指导;横向上,兼以考虑无继承、单继承、多重继承及虚拟继承四方面情况,这样一来,思维层次应该算是比较清晰了。
1、C++类数据成员的内存模型
1.1 无继承情况
实验最能说明问题了,首先考虑下面一个简单的程序1:
#include<iostream>
class memtest
{
public:
memtest(int _a, double _b) : a(_a), b(_b) {}
inline void print_addr(){
std::cout<<"Address of a and b is:/n/t/t"<<&a<<"/n/t/t" <<&b<<"/n";
}
inline void print_sta_mem(){
std::cout<<"Address of static member c is:/n/t/t"<<&c<<"/n";
}
private:
int a;
double b;
static int c;
};
int memtest::c = 8;
int main()
{
memtest m(1,1.0);
std::cout<<"Address of m is : /n/t/t"<< &m<<"/n";
m.print_addr();
m.print_sta_mem();
return 0;
}
在GCC4.4.5下编译,运行,结果如下:
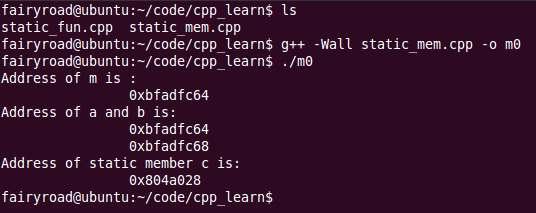
可以发现以下几点:
1. 非静态数据成员a的存储地址就是从类的实例在内存中的地址中(本例中均为0xbfadfc64)开始的,之后的double b也紧随其后,在内存中连续存储;
2. 对于静态数据成员c,则出现在了一个很“莫名其妙”的地址0x804a028上,与类的实例的地址看上去那是八竿子打不着;
其实不做这个测试,关于C++数据成员存储的问题也都是C++ Programmer的常识,对于非静态数据成员,一般编译器都是按其在类中声明的顺序存储,而且数据成员的起始地址就是类得实例在内存中的起始地址,这个在上面的测试中已经很明显了。对非静态数据成员的读写,我们可以这样想,其实C++程序完全可以转换成对应的C程序来编写,有一些C++编译器编译C++程序时就是这样做的。对非静态数据成员的读写也可以借助这个等价的C程序来理解。考虑下面代码段2:
// C++ code
struct foo{
public:
int get_data() const{ return data; }
void set_data(int _data){ data = _data;}
private:
int data;
};
foo f();
int d = f.get_data();
如果要你用C你会怎么实现呢?
// C code
struct foo{
int data;
};
int get_foo_data(const foo* pFoo){ return pFoo->data;}
void set_foo_data(foo* pFoo, int _data){ pFoo->data = _data;}
foo f;
f.data = 8;
foo* pF = &f;
int d = get_foo_data(pF);
在C程序中,我们要实现同样的功能,必须是要往函数的参数列表中压入一个指针作为实参。实际上C++在处理非静态数据成员的时候也是这样的,C++必须借助一个直接的或暗喻的实例指针来读写这些数据,这个指针,就是大名鼎鼎的 this指针。有了this指针,当我们要读写某个数据时,就可以借助一个简单的指针运算,即this指针的地址加上该数据成员的偏移量,就可以实现读写了。这个偏移量由C++编译器为我们计算出来。
对于静态数据成员,如果在static_mem.cpp中加入下面一条语句:
std::cout<<”Size of class memtest is : ”<<sizeof(memtest)<<”/n”;
我们得到的输出是:12。也就是说,class的大小仅仅是一个int 和一个double所占用的内存之和。这很简单,也很明显,静态数据成员没有存储在类实例的地址空间中,它被C++编译器弄到外面去了也就是程序的data segment中,因为静态数据成员不在类的实例当中,所以也就不需要this指针的帮忙了。
1.2 单继承与多重继承的情况
由于我们还没有讨论类函数成员的情况,尤其,虚函数,在这一部分我们不考虑继承中的多态问题,也就是说,这里的父类没有虚函数——虽然这在实际中几乎就是禁手。如此,我们的讨论简洁很多了。
在C++继承模型中,一个子类的内存模型可以看成就是父类的各数据成员与自己新添加的数据成员的总和。请看下面的程序段3。
class father
{
public:
// constructors destructor
// access functions
// operations
protected:
int age;
char sex;
std::string phone_number;
};
class child : public father
{
public:
// ...
protected:
std::string twitter_url; // 儿子时髦,有推号
};
这里sizeof(father)和sizeof(child)分别是12和16(GCC 4.4.5)。先看sizeof(father)吧,int占4 bytes,char占1byte,std::string再占4 bytes,系统再将char圆整到4的倍数个字节,所以一共就是12 bytes了,对于child类,由于它仅仅引入了一个std::string,所以在12的基础上加上std::string的4字节就是16字节了。
在单继承不考虑多态的情况下,数据成员的布局是很简单的。用一个图来说明,如下。

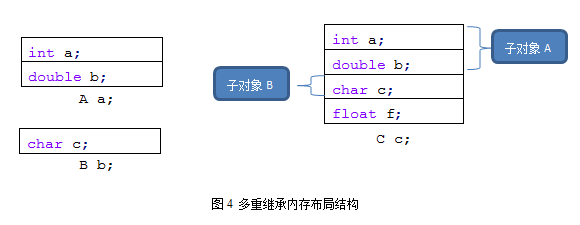
假设有下面三个类,如下面的程序段4所示,继承结构关系如图:
class A{
public:
// ...
protected:
int a;
double b;
};
class B{
public:
// ...
protected:
char c;
};
class C : public A, public B
public:
// ...
protected:
float f;
};
那么,对应的内存布局就是图4所示。
1.3 虚继承
多重继承的一个语意上的副作用就是它必须支持某种形式的共享子对象继承,所谓共享,其实就是环形继承链问题。最经典的例子就是标准库本身的iostream继承族。
class ios{...};
class istream : public ios {...};
class ostream : public ios {...};
class iostream : public istream, public ostream {...};
无论是istream还是ostream都含有一个ios类型的子对象。然而在iostream的对象布局中,我们只需要一个这样的ios子对象就可以了,由此,新语法虚拟继承就引入了。
虚拟继承中,关于对象的数据成员内存布局问题有多种策略,在Inside the C++ Object Model中提出了三种流行的策略,而且Lippman写此书的时候距今天已经很遥远了,现代编译器到底如何实现我也讲不太清楚,等哪天去翻翻GCC的实现手册再论,今天先前一笔债在这。
2、C++类函数成员的内存模型
2.1 关于C++指针类型
要理解好C++类的函数成员的内存模型,尤其是虚函数的实现机制,一定要对指针的概念非常清晰,指针是绝对的利器,无论是编写代码还是研究内部各种机制的实现机理,这是由计算机体系结构决定的。先给一段代码,标记为代码段5:
class foo{
//...
};
int a(1);
double b(2.0);
foo f = foo();
int* pa = &a;
double* pb = &b;
foo* pf = &f;
我们知道,int指针的内容是一个 表征int数据结构 的地址,foo指针的内容就是一个 表征foo数据结构 的地址。那么,系统是如何分别对待这些看上去就是0101的地址的呢?同样是一个 1000110100...10100,我怎么知道这个地址就一个int 数据结构的地址呢?它NN的拼什么就不是一个 foo 数据结构的地址呢?我只有知道了它是int,我才知道应该取出从1000110100...10100开始的4个byte,对不对?
所以我就想——强调一下,我也只是在猜想——一定是指针的数据类型(比如int*,还是foo*?)里面保存了相关的信息,这些信息告诉系统,我要的是一个int,你给我取连续的4个byte出来;我要的是一个foo结构,你给我取XX个连续的byte出来…
简单地说,指针类型中包含了一个类似于 sizeof 的信息,或者其他的辅助信息——至少我们先这么来理解,至于系统到底怎么实现的,那是《编译原理》上艰深的理论和GCC浩繁的代码里黑客们的神迹了。这个sizeof的信息就告诉了系统你应该拿几个(连续)地址上的字节返回给我。例如,int* pInt的值为0xbfadfc64,那么系统根据int*这个指针的类型,就知道应该把从0xbfadfc64到0xbfadfc68的这一段内存上的数据取出来返回。
回到C++的话题上,假设下面的代码段6,其实就是前面代码段3,为了阅读的方便copy过来一下。
class father
{
public:
// constructors destructor
// access functions
// operations
protected:
int age;
char sex;
std::string phone_number;
};
class child : public father
{
public:
// ...
protected:
std::string twitter_url; // 儿子时髦,有推号
};
现在我进行下面的调用:
child c();
father* pF = &c;
child* pC = &c;
std::string tu;
tu = pF->twitter_url;// 这个调用是非法的,原因我们后面说,暂且将这一行标记为(*)
tu = pC->twitter_url;
if(child* pC1 = dynamic_cast<child*>(pF))
tu = pC1->twitter_url;
对于(*)行,其实原因就是我们前面所说的,指针类型中包含了一个类似于sizeof 的信息,或者其他的辅助信息,对比图5,我们可以这样子想,一个father类型object嵌套在了一个child类型的object里面,因为指针类型有一个sizeof的信息,这个信息决定了一个pF类型的指针只能取到12个连续字节的内容,(*)试图访问到这个12个字节之外的内容,当然也就要报错了。
我得说明一句,这样子想只是一种理解上的自由(而且我认为这样理解,从结论和效果上讲是靠谱的),到底是不是这样子,我还并没有调查清楚。
这里,我们先调查了一下指针访问类的数据成员,还没有涉及到函数成员,但其实这才是本部分的核心内容。OK,马不停蹄趁热打铁,接下来我们就说这个故事。
2.2 静态函数成员
如果取一个静态函数成员的地址,获得的就是其在内存中的地址,由于它们没有this指针,所以其地址类型并不是一个指向类成员函数的特别的指针。
也由于没有了this指针这一本质特点,静态函数成员有了以下的语法特点:
l 它不能直接读写class内的非静态成员,无论是数据成员还是函数成员;
l 它不能声明为const或是virtual;
l 它不是由类的实例来调用的,而是类作用域界定符;
这里,我想起了《大学》上一段话:物有本末,事有终始,知所先后,则近道矣”,这话太TMD妙了,凡事入乎其内,外面的什么东西都是浮云,就像《越狱》里的Micheal看到一面墙就想得到里面的钢筋螺丝,这时候这面墙已经不是一面墙了。如果只是生硬地去记忆上面那些东西,那是何其痛苦的事情,也几乎不可能,但是一旦“入乎其内”了,这些东西就真的很简单了。
静态函数成员的特点赋予了它一些有趣的应用场合,比如它可以成为一个回调函数,MFC大量应用了这一点;它也可以成功地应用线程函数身上。
2.3 非静态函数成员
还是可以回到代码段3,其实这个代码段已经给出了非静态成员函数的实现机制。
1. 改写非静态成员函数的函数原型,压入一个额外的this指针到成员函数的参数列表中,目的就是提供一个访问类的实例的非静态数据/函数成员的渠道;
2. 将每一个对非静态数据/函数成员的读写操作改为经由this指针来读写;
3. 最惊讶的一步是,将成员函数改写为一个外部函数——Gotcha!这就是为什么sizeof(Class)的时候不会将非虚函数地址指针计算进去的原因,因为(非静态)成员函数都被搬到类的外面去了,并借助Name Mangling算法将函数名转化为一个全局唯一的名字。
对于第3点,有一个明显的好处就是,对类成员函数的调用就和一般的函数调用几乎没任何开销上的差异,几乎从C++投胎开始,效率就成为了C++的极致追求之一。
2.4 虚拟成员函数
| 这 |
是本文中最复杂也最有趣的话题了。虚拟函数也是和继承这个话题相伴相生,所以本节将纳入对单继承、多重继承和虚拟继承,一起描述他们之间的关系,这样,对C++对虚拟函数的调用,以及由此所变现出来的多态的理解,应该是非常清晰了。
2.4.1 单继承下的虚拟成员函数
对于虚拟函数,我们首先引入两个数据结构,为什么引入一会就知道了。
1. Virtual table. 大名鼎鼎的vtbl,如果一个类有虚拟函数,编译器首先一堆指向virtual function的指针,这些指针,就存放在了这个vtbl之中。
2. vptr. 编译器会为每个或自己有,或其父类/祖爷类等有虚拟函数的类的实例压入一个指针,指向相关联的virtual table,这个指针就是vptr。
先不管为什么要这么做,先看看这么一些数据结构引入之后,编译器怎么来处理虚拟函数调用的问题。考虑代码段7:
class base{
public:
virtual int sayhello(){
std::cout<<"Hello, I'm a BASE lass instance!/n";
}
};
class derived : public base{
public:
virtual int sayhello(){
std::cout<<"Hello, I'm a DERIVED class instance!/n";
}
};
base b;
derived d;
base* pB = &d;
pB->sayhello();
pB = &b;
pB->sayhello();
对于这句:pB->sayhello();
虚拟函数的关键——从效用角度讲就是多态的关键——就是为sayhello()找到适当的执行体。为此我们必须好好理解多态。
/ *******************************************************插叙:关于多态
我的理解是:同样的操作,得到不同的结果。我们或许接触得多的是override,因为一开始比较正式和系统的讲多态这个概念的时候是虚函数的 override 引发的,但是不尽然,按照“同样的操作,得到不同的结果”的观点,override和overload都是实现多态的手段。(当然还有其它的手段)。
l override意思是重写,仅仅发生在继承这个过程,在基类中定义了某个函数,且这个函数是virtual的——这是必要条件——再从基类继承出一个新的派生类,就可以在派生类重新定义这个函数”。override的条件比较苛刻,继承+虚函数。
l overload就是重载了,允许多个函数具有相同的名字,这里的函数既可以是类的成员函数——如构造函数就可以重载多个版本,也可以是全局的函数。更明显的例子是运算符重载,complex类中复数的相加等运算就是+的重载,可以把运算符看成函数,从而被overload。
由上面的讨论可以看出,override和overload最大的相同点是:多个函数具有相同的名字。最大的不同点是:override是在程序运行的时候才决定调用哪个函数,overload是在代码被编译的时候决定调用哪个函数——静态联编。
那么,多态到底有什么用呢?
Google一下,曰:多态是一种不同的对象以单独的方式作用于相同消息的能力。注意这几个相同与不同,这个概念是从自然语言中引进的——这个意识对于理解OOP是很好的——我的一种学习体会就是,尽量在自然界中寻找神似的感觉,嘿,OOP还是很好理解嘛!举个例子,动词“关闭”应用到不同的事务上其意思是不同的。关门,关闭银行账号或关闭一个程序的窗口都是不同的行为,其实际的意义取决于该动作所作用的对象。这个比方应该对理解多态有帮助,总之还是那句话:同样的操作,不同的对象执行,就会出现不同的结果。
大多数面向对象语言的多态特性都仅以虚拟函数的形式来实现,但C++除了一般的虚拟函数形式之外,还多了两种“类似于静态的”(因为我觉得没有虚函数那样足够灵活,不过,也够强大的了)多态机制:
1、操作符重载(函数重载的一种):例如,对整型和string对象应用 += 操作符时,每个对象都是以单独的方式各自进行解释。显然,潜在的 += 实现在每种类型中是不同的。但是从直观上看,我们能够预期结果是什么。
2、模板:例如,当接受到相同的消息时,整型vector对象和串vector对象对消息反映是不同的,我们以关闭行为为例:
vector<int> vi;
vector<string> names;
string name("C++有点BT呀");
vi.push_back(5);
names.push_back(name);
静态的多态机制不会导致和虚拟函数相关的运行时开销。此外,操作符重载和模板两者是通用算法最基本的东西,在STL中体现得尤为突出。
关于多态的优点,说不清,可能主要是编程实践不够,很多书上是这样说的(比如C++ primer)依赖动态联编,达到统一的接口,不同的实现的功能。从代码执行角度来看,动态联编产生对象的静态类型和动态类型的区别,用户通过对象动态类型来匹配相应的实现,使得同样的代码有了不同的表现。多态使得类的接口和实现分离,降低了程序的耦合性和编译的依赖性,提高了软件的模块化,从而诞生了各种各样所谓的模式。概括起来多态所带来的优点——灵活。
*******************************************************************/
罗里吧嗦一大堆,让我们再次回到代码段7。为了实现所谓的根据对象的实际情况作出相应动作的所谓“多态”,必须首先能够对于多态对象有某种形式的运行期对象识别办法。也就是说,我们需要在运行期获得pB->sayhello();中关于pB的某些相关信息,pB他老人家到底指向了啥子捏?前面我(猜想)着说过,指针类型中可能加入了某些类似于sizeof的信息,好吧,计算这个猜想是对的,也不能保证多态就一定可以实现——单纯这样一个信息太老土了,不够。万一子类没有引入新的数据成员怎么办呢?那好吧,我就直接引入一个对象类型的编码,比如我用某些bit位表示表示类,但是这样对空间要求增加了,而且,这样也不优雅,不简洁。
根据《Inside the C++ Object Model》,这些额外(类型)信息是有的——我前面的猜测部分是正确的——但是不是和指针放在一起。我们一步步来,首先,额外信息到底是什么?知道了这个,我们可以精确的评估开销。其次,我们到底把这些信息放哪里呢?放对了地方,才有可能争取时间与空间的优势。
对于第一个问题,我们需要知道:
A. pB所指对象的真实类型,到底是base还是derived?
B. sayhello()函数体在内存中间的位置。
对于第二个问题,C++的办法是,在每一个需要多态(有virtual函数)的类对象身上压入两个成员:
a) 一个字符串或数组,表示class的类型,即type-info;
b) 一个指针,指向某个表格,表格中保存了类和类的继承链中virtual函数的运行期地址。
这两点,分别对应于前面A, B两项需求。而对于b)中提到的两份数据,就是本小节一开始提到的vptr和vtbl了。
vtbl中的virtual函数地址从何得知呢?在C++中,virtual函数可以在编译期间就得到,此外,这一组地址是固定不变的,运行期不可能增加或更改。由于程序在执行中vtbl的大小和内容不会改变,所以vtbl构造可以完全由编译器掌控,不需要运行期的任何介入。
然而,为运行期准备好这些地址雷锋还只做了一半。还有一个问题就是找到这些地址。这个,就是vptr的用途了。首先,vptr将指向编译器分配好的vtbl表格,然后被压入类的实例中,这样,我们借助这个vptr找到了vtbl,又因为vtbl表格中一个个表项就是这些virtual的地址,所以万里长征终于到头了。剩下的,就是运行期在vtbl中找到特点的表项,取出virtual函数的地址即可。
一个类只有一个vtbl,每个vtbl内含其对应的类对象中所有虚函数实体的地址,这些虚函数包括:
1. 该类所定义的函数实体。它会override一个可能存在的基类中的虚函数。
2. 继承自基类的函数实体,这些是在子类决定不改写虚拟函数时才会出现的情况。
3. 一个纯虚函数实体。
每一个虚拟函数都被指派一个固定的索引值,这个索引在整个集成体系中保持与特定的虚函数的关联。考虑一个实例代码段8:
class Parent {
public:
Parent():nParent(888) {}
virtual void sayhello() { cout << "Perent()::sayhello()" << endl; }
virtual void walk() { cout << "Parent::walk()" << endl; }
virtual void sleep() { cout << "Parent::sleep()" << endl; }
protected:
int nParent;
};
class Child : public Parent {
public:
Child():nChild(88) {}
virtual void sayhello() { cout << "Child::sayhello()" << endl; }
virtual void walk_child() { cout << "Child::walk_child()" << endl; }
virtual void sleep_child() { cout << "Child::sleep_child()" << endl; }
protected:
int nChild;
};
class GrandChild : public Child{
public:
GrandChild():nGrandchild(8) {}
virtual void sayhello() { cout << "GrandChild::sayhello()" << endl; }
virtual void walk_child() { cout << "GrandChild::walk_child()" << endl; }
virtual void sleep_grandchild() { cout << "GrandChild::sleep_grandchild()" << endl; }
protected:
int nGrandchild;
};
现在,我们使用一个int** pVtbl 来作为遍历对象内存布局的指针,这样可以方便地像使用数组一样来遍历所有的成员包括其虚函数表:
typedef void(*Fun)(void);
GrandChild gc;
int** pVtbl = (int**)&gc;
cout << "[0] GrandChild::_vptr->" << endl;
for(int i=0; (Fun) pVtbl[0][i]!=NULL; i++){
pFun = (Fun) pVtbl[0][i];
cout << " ["<<i<<"] ";
pFun();
}
cout << "[1] Parent.nParent = " << (int)pVtbl[1] << endl;
cout << "[2] Child.nChild = " << (int) pVtbl[2] << endl;
cout << "[3] GrandChild.nGrandchild = " << (int) pVtbl[3] << endl;
运行结果如下:
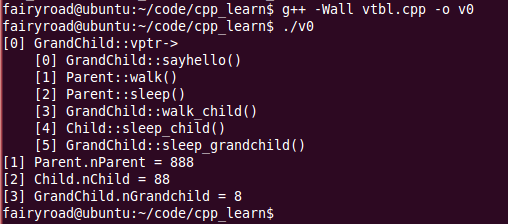
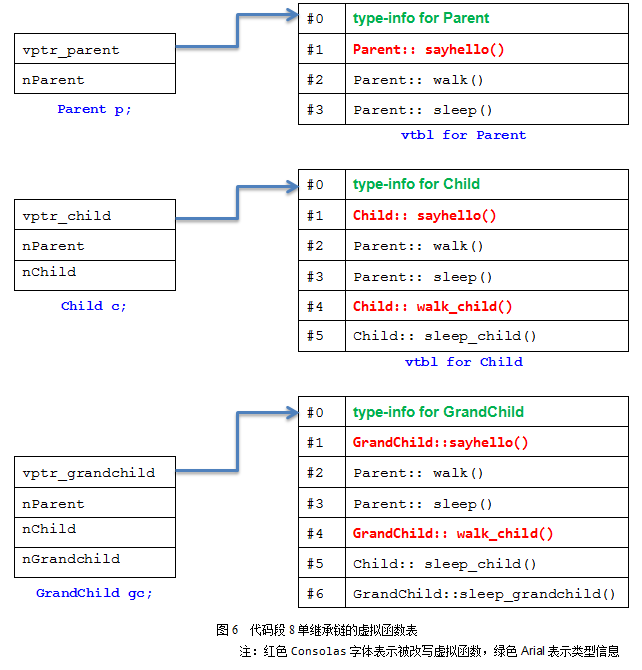
我们发现,当一个子类继承父类时:
1. 它可以继承父类中所声明的virtual函数的函数实体,准确地说,是该函数实体的地址会被拷贝到子类的虚拟函数表中;
2. 它可以使用自己的函数体,如Child::sayhello()和GrandChild::walk_child()。
3. 它可以加入新的虚函数。
由前面的讨论,我们已经可以画出这三个类的内存布局图了,如下页图6所示。由这个图,如果我们计算sizeof(GrandChild),对于结果应该就不会差异了:3个int变量,再加上一个指针。
下一步,就是编译期间如何对pB->sayhello()设定对虚函数的调用呢?
1. 首先,我们并不知道pB所指对象的真正类型,但是我知道经由pB可以存取到该对象的虚拟函数表。
2. 虽然我并不知道哪个sayhello()应该被调用,但是我知道每一个sayhello()函数的地址都放在vbtl的某个表项中,比如上述代码中的第1表项。
由以上的这些信息,编译器已经可以将pB->sayhello()转化为:
(*pB->vptr[1]) (pB);
在这个转化中,vptr表示编译器所压入的指针,指向vtbl,1表示sayhello()在vtbl中的索引号。。唯一一个需要在运行期才能知道的信息是:该索引所对表项到底是哪一个sayhello()的函数实体,这个可以借助type-info的信息获得,因为pB也被压入了参数列表中。
(未完待续...)
2.4.2 多重继承下的虚拟函数
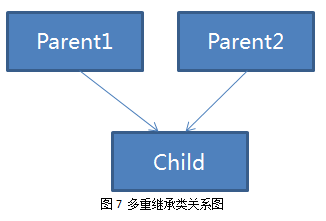
多重继承下的虚拟函数主要有一下几个麻烦:
1. 几个父类都声明了相同原型的virtual函数;
2. 有不止一个父类将其析构函数声明为虚拟;
3. 一般的虚拟函数问题;
先给出代码段9。
class Parent1{
public:
Parent1() : data_parent1(0.0){}
virtual ~Parent1(){cout<<"Parent1::~Parent1()"<<endl;}
virtual void speakClearly(){cout<<"Parent1::speakClearly()"<<endl;}
virtual Parent1* clone() const{cout<<"Parent1::clone()"<<endl; return null;}
protected:
int data_parent1;
};
class Parent2{
public:
Parent2() : data_parent2(1.0){}
virtual ~Parent2(){cout<<"Parent2::~Parent2()"<<endl;}
virtual void mumble(){cout<<"Parent2::mumble()"<<endl;}
virtual Parent2* clone() const{cout<<"Parent2::clone()"<<endl; return null;}
protected:
int data_parent2;
};
class Child : public Parent1, public Parent2
{
public:
Child() : data_child(2.0){}
virtual ~Child(){cout<<"Child::~Child()"<<endl;}
virtual Child* clone() const{cout<<"Child::clone()"<<endl; return null;}
protected:
int data_child;
};
就内存布局而言,有了前面的基础了,猜得出来大概是个什么样子了。好吧,我们就先猜一把,然后再写段代码验证验证。对于数据成员,多重继承使用的就是各自分配一段空间“叠放”在一起,如之前的图4所示。对于虚拟函数,其实就是多了个vptr嘛,也放进去不久结了吗?
嗯,所以我们可以猜想了,见图8。
接下来就是调试验证了,调试代码段10如下:
typedef void(*Fun)(void);
int main()
{
Child c;
Fun pFun;
int** pVtbl = (int**)&c;
cout << "[0] Parent1::_vptr->" << endl;
pFun = (Fun)pVtbl[0][0];
cout << " [0] ";
pFun();
pFun = (Fun)pVtbl[0][1];
cout << " [1] ";
pFun();
cout << " Parent1.data_parent1 = " << (int)pVtbl[1] << endl;
int s = sizeof(Parent1)/4;
cout << "[" << s << "] Parent2::_vptr->"<<endl;
pFun = (Fun)pVtbl[s][0];
cout << " [0] "; pFun();
pFun = (Fun)pVtbl[s][1];
cout << " [1] "; pFun();
s++;
cout << " Parent2.data_parent2 = " << (int)pVtbl[s] << endl;
s++;
cout << "[3] Child.data_child = " << (int)pVtbl[s] << endl;
}
需要的是,这段代码的运行要将虚析构函数注释掉,理由应该很好理解吧,对象都被析构掉了,指针也就成为悬挂指针了,SIGSEGV就会触发。Code::Blocks(GCC 4.5.2)下运行结果如下:
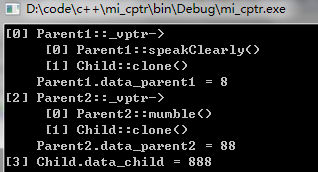
再次说明一下,因为我们注释掉了虚析构函数那一行,所以上面的输出中没有Child::~Child()之类的信息。所以,我们的猜想图8是正确的。
根据《Inside The C++ Object Model》一书,关于多重继承主要有三种情况要仔细考虑,对着图8,这三种情况其实都是浮云。
1. 通过一个“指向第二个父类,如Parent2”的指针,调用子类的虚拟函数。请看代码段11:
Parent2* pP2 = new Child;
// 下面的代码将调用Child::~Child()
// 因此pP2必须被向后调整sizeof(Parent1)个bytes,由编译器和运行期信息参与完成
delete pP2;
还是回到图8,注意到一个问题,Parent1和Child指针所指向的位置是一样的(如果都是取的同一个Child对象的地址),但是Parent2不是,它与Parent1和Child的指针之间存在一个偏移量,看下面的代码就知道了:
Child c;
Parent1* pP1 = &c;
Parent2* pP2 = &c;
Child* pC = &c;
cout<<pP1<<"/n"<<pC<<"/n"<<pP2<<"/n/n";
运行结果如下图:

pP1与pC内容一样,pP2与pP1和pC之间存在8个字节的偏移量(8个字节是由一个4字节int变量和一个4字节指针引起的)。
对于代码段11,因为pP2指向Child对象中Parent2子对象处,为了能够正确执行,pP2必须调整到Child对象起始处。
1. 通过一个“指向Child类”的指针,调用Parent2中一个继承而来的虚拟函数。在这种情况下,子类指针必须再次被调整,以指向第二个父类Parent2处。例如:
Child* pC = new Child;
// 调用Parent2::mumble()
// pC必须被向前调整sizeof(Parent1)个bytes,由编译器和运行期信息参与完成
pC->mumble();
2. 第三种情况发生在一个语言扩充性质之下:允许一个虚拟函数的返回值类型有所变化(注意,返回值类型不是激活C++重载机制的充分条件),可能是父类类型,也可能是子类类型,这一点通过clone()函数来描述,看下面代码:
Parent2* pP1 = new Child;
// 调用Child* Child::clone()
// 返回值必须被调整,以指向Parent2子对象,由编译器和运行期信息参与完成
Parent2* pP2 = pP1->clone();
当进行pP1->clone()时,pP1会被调整到指向Child对象的起始地址,于是clone的Child版会被调用,它会传回一个指针,指向一个新的Child对象,该对象的地址在被指定给pP2之前,必须经过调整,以指向Parent2子对象处。
之前的注释中都有一句话,“XXX必须被调整,以指向Parent2子对象,由编译器和运行期信息参与完成”,确实,就是编译器会去做的事情,我们也不用管,因为这也是compiler-dependent的。
2.4.3 虚继承下的虚拟函数
虚拟继承的出现就是为了解决重复继承中多个间接父类的问题的,经典继承结构图就是环形继承链:
class PP {……};
class P1 : virtual public PP{……};
class P2: virtual public PP{……};
class C : public P1, public P2{…… };
虚拟继承是个有点麻烦乃至无聊的东西,实践中不被推荐,一般来说:
1) 先是P1,然后是P2,接着是C,而PP这个超类都放在最后的位置;
2) 各个类内部的布局与多重继承一样;
3、C++对象模型总结
大道至简,如果理解了前面的文字,下面四句话应该就差不多了:
l 非静态数据成员都存放在对象所跨有的地址空间中,静态数据成员则存放于对象所跨有的地址空间之外;
l 非虚拟成员函数(静态和非静态)也存放于对象所跨有的地址空间之外,且编译器将其改写为普通的非成员函数的形式(以求降低调用开销);
l 对于虚拟成员函数,则借助vtbl和vptr支持。
l 对于继承关系,子类对象跨有的地址空间中包含了父类对象的实体,通过嵌入type-info信息进行识别和虚函数调用。
4、参考资料
[1] Inside The C++ Object Model,Lippaman,第1、2、4章。
[2] C++对象内存布局,陈皓专栏, http://blog.csdn.net/haoel/archive/2008/10/15/3081328.aspx