说说循环缓冲区(Ring Buffer)
关于循环缓冲区(Ring Buffer)的概念,其实来自于Linux内核(Maybe),是为解决某些特殊情况下的竞争问题提供了一种免锁的方法。这种特殊的情况就是当生产者和消费者都只有一个,而在其它情况下使用它也是必须要加锁的。对应在Linux内核中有对它的定义:
struct kfifo {
unsigned char *buffer;
unsigned int size;
unsigned int in;
unsigned int out;
spinlock_t *lock;
};
当然关于对它有对应的操作函数,这里不再说了(不是今天的重点)。我们只要了解这种概念就好。
关于定义: 其中buffer指向存放数据的缓冲区,size是缓冲区的大小,in是写指针下标,out是读指针下标,lock是加到struct kfifo上的自旋锁(上面说不加锁不是这里的锁),防止多个进程并发访问此数据结构。当in==out时,说明缓冲区为空;当(in-out)==size时,说明缓冲区已满。
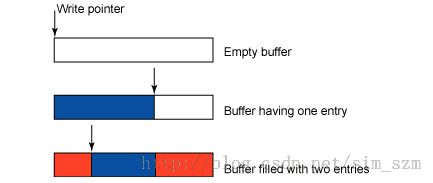
注:我们保有对应的读写指针,当第一批数据(蓝色)完成,第二批数据(红色)会根据当前的写指针位置继续我们的数据操作,当达到最大的Buffer_Size时,会重新回到Buffer的开始端。
对此我给出一个简单的模拟实现Class:
/* * ===================================================================================== * * Filename: ring_buffer_class.h * Version: 1.0 * Created: 2013年11月28日 13时08分04秒 * Revision: none * Compiler: clang * Author: sim szm, [email protected] * * ===================================================================================== */ #include <iostream> class ring_buffer { public: ring_buffer( void* buffer, unsigned int buffer_size ); void buffer_data( const void* data, unsigned int& len ); void get_Data( void* outData, unsigned int& len ); void skip_data( unsigned int& len ); inline unsigned int free_space(); inline unsigned int buffered_bytes(); private: void flush_state(); unsigned char *read_ptr, *write_ptr; unsigned char *end_pos; unsigned char *buffer; int max_read, max_write, buffer_data_; }; ring_buffer::ring_buffer( void* buffer, unsigned int buffer_size ) { buffer = (unsigned char*)buffer; end_pos = buffer + buffer_size; read_ptr = write_ptr = buffer; max_read = buffer_size; max_write = buffer_data_ = 0; flush_state(); } void ring_buffer::buffer_data( const void* data, unsigned int& len ) { if ( len > (unsigned int)max_read ) len = (unsigned int)max_read; memcpy( read_ptr, data, len ); read_ptr += len; buffer_data_ += len; flush_state(); } void ring_buffer::get_Data( void* outData, unsigned int& len ) { if ( len > (unsigned int)max_write ) len = (unsigned int)max_write; memcpy( outData, write_ptr, len ); write_ptr += len; buffer_data_ -= len; flush_state(); } void ring_buffer::skip_data( unsigned int& len ) { unsigned int requestedSkip = len; for ( int i=0; i<2; ++i ) { // 可能会覆盖,做两次 int skip = (int)len; if ( skip > max_write ) skip = max_write; write_ptr += skip; buffer_data_ -= skip; len -= skip; flush_state(); } len = requestedSkip - len; } inline unsigned int ring_buffer::free_space() { return (unsigned int)max_read; } inline unsigned int ring_buffer::buffered_bytes() { return (unsigned int)buffer_data_; } void ring_buffer::flush_state() { if (write_ptr == end_pos) write_ptr = buffer; if (read_ptr == end_pos) read_ptr = buffer; if (read_ptr == write_ptr) { if ( buffer_data_ > 0 ) { max_read = 0; max_write = end_pos - write_ptr; } else { max_read = end_pos - read_ptr; max_write = 0; } } else if ( read_ptr > write_ptr ) { max_read = end_pos - read_ptr; max_write = read_ptr - write_ptr; } else { max_read = write_ptr - read_ptr; max_write = end_pos - write_ptr; } }
我们更多要说的是Ring Buffer关于在我们在日志处理方面的一个应用,我们知道对于Program来说日志记录提供了故障前应用程序状态的详细信息,在一段时间的运行过程中,会将不断地产生大量的跟踪数据,以及调试信息并持续地将其写入到磁盘上的文本文件中。多亿进行有效的日志记录,需要使用大量的磁盘空间,并且在多线程环境中,所需的磁盘空间会成倍地增加。常规的日志处理来说存在一些问题,比如硬盘空间的可用性,以及在对一个文件写入数据时磁盘 I/O 的速度较慢。持续地对磁盘进行写入操作可能会极大地降低程序的性能,导致其运行速度缓慢。通常,可以通过使用日志轮换策略来解决空间问题,将日志保存在几个文件中,当这些文件大小达到某个预定义的字节数时,对它们进行截断和覆盖。
所以要克服空间问题并实现磁盘 I/O 的最小化,某些程序可以将它们的跟踪数据记录在内存中,仅当请求时才转储这些数据。这个循环的、内存中的缓冲区称为循环缓冲区。它可以将相关的数据保存在内存中,而不是每次都将其写入到磁盘上的文件中。在需要的时候(比如当用户请求将内存数据转储到文件中时、程序检测到一个错误时,或者由于非法的操作或者接收到的信号而引起程序崩溃时)可以将内存中的数据转储到磁盘。循环缓冲区日志记录由一个固定大小的内存缓冲区构成,进程使用这个内存缓冲区进行日志记录。
当然现在我们面对的大多是多线程的协同工作,对于日志记录来说,倘若采取传统的加锁机制访问我们的存储文件,这些线程将在获得和释放锁上花费了大部分的时间,所以采取循环缓冲区会是一个不错的办法。通过使得每个线程将数据写入到它自己的内存块,就可以完全避免同步问题。当收到来自用户的转储数据的请求时,每个线程获得一个锁,并将其转储到中心位置。或者分配一个很大的全局内存块,并将其划分为较小的槽位,其中每个槽位都可由一个线程用来进行日志记录。每个线程只能够读写它自己的槽位,而不是整个缓冲区。当每个线程第一次尝试写入数据时,它会尝试寻找一个空的内存槽位,并将其标记为忙碌。当线程获得了一个特定的槽位时,可以将跟踪槽位使用情况的位图中相应的位设置为1,当该线程退出时,重新将这个位设置为 0。在这里需要同时需要维护当前使用的槽位编号的全局列表,以及正在使用它的线程的线程信息。
但是这里需要注意的是当一个线程已经死亡,却没有释放相应的槽位,并在垃圾收集器释放该槽位之前,再次使用了这个线程 ID 并为其分配一个新的槽位。对于新的线程来说,检查全局列表并且重用相同的槽位(如果以前的实例使用了它的话),这是非常重要的。因为垃圾收集器线程和写入者线程可能同时尝试修改全局列表,所以同样也需要使用某种锁定机制。