Aerospike-Architecture系列之数据分布
Data Distribution(数据分布)
Aerospike数据库是Shared-Nothing 架构:一个Aerospike集群中的每个节点都是相同的,所有节点对等,无单点故障。
利用Aerospike智能分区算法,数据分布在集群中的各个节点之上。我们已经在这个领域的许多案例中测试过我们的方法,这个非常随机数函数保证分区分布误差在1-2%。
为了确定记录去向,使用RIPEMD160算法,任意长度的记录键(key)被哈希化为一个20位的定长字符串,前12位组成分区ID,用来确定哪个分区包含这条记录。分区同样分布于集群节点中。所以,集群中有N个节点,每个节点大约存储1/N的数据。
因为数据均匀且随机的分布于节点,不会出现热点和瓶颈。也不会出现明显的某个节点比其他节点处理请求多的情况。
例如,在美国很多的姓以R开头。如果数据按照字母排序存储,存储以R开头的服务器其通讯量会远远大于存储以X,Y或Z开头的服务器。数据随机分配保证服务器负载均衡。
对于可靠性,Aerospike在一个或多个节点上复制分区。一个节点作为读写分区的主节点,其他节点存储副本。
例如,在一个4节点的Aerospike集群中,每个节点约是1/4数据的主节点,同时也是1/4数据的副本。作为主节点的数据分区,分布于所有其他作为副本的节点。所以,如果节点#1不可访问,节点#1的副本将被延伸至其他3个节点。
同步复制保证即时一致性,没有数据丢失。在提交数据并返回结果给客户端之前,写事务被传播到所有副本。个别案例中,在集群重新配置期间,当Aerospike智能终端发送请求到那些短 暂过时的错误节点时,Aerospike智能集群会透明的代理请求至正确的节点。最后,当集群正在从分区中恢复,它解决所有发生在不同副本之间的冲突。解 析可以配置为自动的,在这种情况下拥有最新的时间戳的数据被视为标准。或者为了在更高层次解析,所有数据副本可以被返回应用程序。
How Aerospike Creates Partitions(Aerospike如何创建分区)
namespace是Aerospike数据库以相同方式存储的数据的集合。每个namespace分为4096个分区,分区被均等的分到集群中的节点。意味着如果集群中有n个节点,每节点约存储1/n的数据
用非常随机数哈希方法保证分区均匀分布。我们已经在这个领域的许多案例中测试过我们的方法,数据分布误差在1-2%。
因为数据均匀且随机的分布于节点,不会出现热点和瓶颈。也不会出现明显的某个节点比其他节点处理请求多的情况。
例如,在美国很多的姓以R开头。如果数据按照字母排序存储,存储以R开头的服务器其通讯量会远远大于存储以X,Y或Z开头的服务器。数据随机分配保证服务器负载均衡。
下一步,无须人工分片。集群节点间均等的划分分区。客户端发现集群变化并发送请求到正确的节点。定节点被添加或移除,集群自动再平衡。集群中所有节点是均等的-没有单独的master节点失败而导致整个数据库宕掉。
当数据库create一个条记录,记录key的哈希值被用来分配记录到某一分区,哈希算法是确定的-哈希算法总是将记录映射到同样分区。在记录的整个生命周期它驻留在同一节点上。分区可能从一个节点移动到其他节点。但是分区不会分裂或者重新分配记录到其他分区
How Data is Replicated/Synchronized locally(数据如何被局部的复制/同步)
An Aerospike Cluster with No Replication(一个无复制的Aerospike集群)
考虑4节点集群的情况。Aerospike数据库中,无复制数据需要设置复制因子为1(replication factor = 1),意思是数据库中只存在一个副本。
因为所有4096个分区在一个4节点集群中,每个节点有1/4的数据-随机分配的1024个分区。集群看起来如下图,每个节点管理一个分区集合(简单起见,只展示两个节点的分区):

每个节点是1/4数据分区的主数据节点-如果节点是数据的主读写源,那么它就是主数据节点。
客户端对数据有位置感知能力-客户端知道每个分区的位置-索引数据可以单跳从节点返回。每个读写请求发送至主数据节点处理。当智能节点读某条记录时,它发送请求到记录的主数据节点。
An Aerospike Cluster with Replication(有复制的Aerospike集群)
现在考虑一下带数据复制的情况。大多数情况是维护两个数据副本,主数据和副本。Aerospike数据库中,需要指定复制因子为2(replication factor = 2)。
在这个例子中,每个节点拥有1/4的主数据(1024个分区)和1/4的数据副本(1024个分区)。看起来像这样(简单起见,显示两个节点的细节)
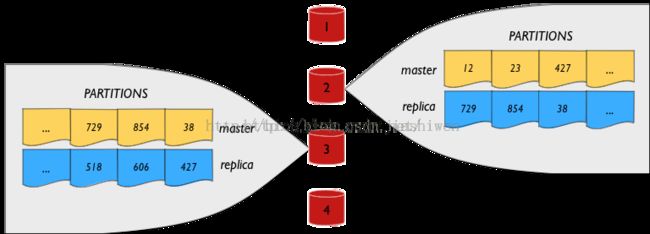
注意,每个节点的主数据作为副本被分布到所有的其他节点。例如,节点#1的主数据分区副本横跨其他节点分布。当节点#1不可用,节点#1的数据副本延伸至跨其他数据节点。
与先前提到的无副本的例子一样,客户端发送请求至主数据。
与无复制的情况一样,读请求通过智能客户端发送至正确的节点,写请求也被发送至正确的节点。当节点收到写请求,它保存数据并转发写请求到副本节点。一旦副本节点确认数据写成功并且主数据节点本身也完成写动作,然后确认被发送至客户端,写操作成功。
Automatic data rebalancing(自动数据再平衡)
无人工分片。
Aerospike数据再平衡算法保证请求量在所有节点间均匀分布,在再平衡期间节点失败发生时,算法依旧健壮。系统被设计为持 续可用,所有数据再平衡不影响集群行为。事务算法与数据分布系统集成,只有一个一致投票来协调集群变化。当客户端发现新的集群配置时,利用集群内部重定向 算法,只有一个小的间隔。这样,在一个可伸缩的无共享机制优化事务简单环境,同时保ACID特征。
Aerospike允许配置选项指定有多少可用的操作开销应该用于管理任务,例如与运行客户端事务相比有多少用于节点间再平衡。在首选事务放缓的情况下,集群愈合更快。在交易量和速度必须维持的情况下,集群再平衡会很慢。
在某些集群因子不能满足的情况下。集群可以配置为减少配置因子以保持所有数据,或者清除哪些标记为可丢弃的就数据。如果集群不成接受更多数据,集群将在read-only模式下操作,直到新的扩容可用-节点会自动变为可以接受应用程序的写操作。
不需要操作员干预,甚至在要求的时间内,集群将自愈。在客户部署中,提取8节点集群中的一个会让整个回路被打断。这就需要无人工干预。即使数据中心在高峰时宕机,事务依旧保持精确的ACID。几小时内,当错误被修复,操作者不需要执行特殊步骤来维护集群。
我们的扩容计划和系统监控,为你提供处理不可预见的错误的能力,而且无服务丢失。你可以配置硬件容量、设置复制/同步策略,这样数据库恢复时可以对用户无影响。
Handling Traffic Saturation(处理通讯量)
讨论网络硬件如何处理高峰流量负载的细节超出了本文档的范围。Aerospike数据库提供了用来评估瓶颈的监控工具。如果网络是瓶颈,数据库不会满负荷运转,请求会变慢。
Handling Capacity Overflows(处理容量溢出)
对于容量规划我们有很多建议,管理存储并监控集群以确保存储不溢出。但是在存储溢出的情况下,Aerospike触发停止写限制-在这种情况下不会有新的记录 被接受。但是数据修改和读取被正常处理。
换句话说,即使超过容量,数据库不会停止处理查询操作,它持续保持尽量多的用户请求处理量。
译 者:北京IT爷们儿