Java程序员笔试经典例题
1.写一个Java应用程序,从键盘输入两个数,然后输出他们的平方值及立方值。
解析:在Java中没有像C语言那样有一个专供接受从键盘输入的scanf函数,所以一般的做法是从键盘输入一行字幅,保存到字符串s中,再将字符组成的字符串s转换成整型数据后返回。
import java.io.*;
class InputData{ //定义从键盘输入数据的类
static private String s = "";
static public void input(){ //从键盘输入一行字幅,保存到字符串s中
BufferedReader bu = new BufferedReader(
new InputStreamReader(System.in)
);
try{ //捕获输入/输出异常
s = bu.readLine();
}catch(IOException e){
e.printStackTrace();
}
}
static public int getInt(){ //静态方法可直接用类名调用
input();
return Integer.parseInt(s); //将字符组成的字符串s转换为整型数据后返回
}
}
class Result{
void print(int d){
System.out.println(d + "的平方:" + d * d);
System.out.println(d + "的立方:" + d * d * d);
}
}
public class PrintResult{
public static void main(String[] args){
Result result = new Result();
System.out.println("请输入一个整数:");
int a = InputData,getInt();
result.print(a);
}
}
2.下面语句中共创建了几个对象?
String s = "a" + "b" + "c" + "d" + "e";
A.没有创建对象 B.1个对象 C.2个对象 D.5个对象
解析:该语句在class文件中就相当于String s = "abcde"。然后当JVM执行到这一句时,就在String pool里找,如果没有这个字符串,就会产生1个对象。可以对比源代码和反编译代码如下:
public class a{
public static void main(String[] args){
String s = "a" + "b" + "c" + "d" + "e";
System.out.println(a);
}
}
//反编译如下:
Java code
Compile from "a.java"
public class a extends java.lang.Object{
public a();
Code:
0: aload_0
1: invokespecial #1;Method java/lang/System.out:Ljava/io/printStream;
4: return
public static void main(java.lang.String[]);
Code:
0: ldc #2; //String abcde 直接是 abcde
2: astore_1
3: getstatic #3; //Field java/lang/System.out.Ljava/io/PrintStream;
6: aload_1
7: invokevirtual #4; //Method java/io/PrintStream.println:(Ljava/lang/String;)V
10: return
}
String的内部结构是通过StringBuilder实现的。所以,没有生成"ab"、"abc"等对象s引用在堆栈里,肯定不是对象,所以只创建了一个对象"abcde"。扩展知识1:Constant Pool常量池的概念
在Java编译好的class文件中,有个区域称为Constant Pool,它是一个由数组组成的表,类型为cp_info constant_pool[],用来存储程序中使用的各种常量,包括Class、String、Integer等各种基本的Java数据类型。对于Constant Pool,表的基本通用结构如下:
cp_info {
u1 tag;
u1 info[];
}
tag是一个数字,用来表示存储的常量类;;info[]根据类型码tag的不同会发生相应的变化。
扩展知识2:关于String类的说明
(1)String使用private final char value[] 来实现字符串的存储,也就是说,String对象创建之后,就不能再修改此对象中存储的字符串内容,就是因为如此,才说String类型是不可变的(immutable),或者是final的。
(2)String类有一个特殊的创建方法,就是使用""双引号来创建。例如new String("helloworld")世纪创建了两个String对象,一个是"helloworld"通过""双引号创建的,另一个是通过new创建的。只不过他们创建的时期不同,一个是编译期,一个是运行期。
(3)Java对String类型重载了加号(+)操作符,可以直接使用“+”对两个字符串进行连接。
(4)运行期调用String类的intern()方法可以向String Pool中动态添加对象。
(5)String的创建方法一般有如下几种:
①直接使用""引号创建;
②使用new String()创建;
③使用new String("helloworld")创建以及其他一些重载构造函数创建;
④使用重载的字符串连接操作符“+”创建。
3.请简述一下Java反射机制。
解析:Java中的反射是一种强大的工具,它能够创建灵活的代码,这些代码在运行时装配,无需在组件之间进行链接。反射允许在编写与执行时,使用程序代码能够接入装载到JVM中的类的内部信息,而不是源代码中选定的类协作的代码。这使反射成为构建灵活应用的主要工具。需要注意的是,如果使用不当,反射的成本会很高。
Java中的类反射Reflection是Java程序开发语言特征之一,它允许运行中的Java程序对自身进行检查,或者说“自审”,并能直接操作程序的内部属性。Java的这一能力在实际应用中也许用的不是很多,但是在其他的程序设计语言中就不存在这一个特性。例如Pascal、C或者C++中就没有办法在程序中获得与函数定义相关的信息。
4.请说明static nested class 和 inner class的不同。
解析:
(1)nested(嵌套)class(一般是C++的说法)
nested class是合成型聚集关系(Composite Aggregation)的另一种表达方式,也就是说,nested class也可以用Aggregation表达出来。但是,nested class更加精确地表达了一种专用的、紧耦合的关系,尤其是在代码生成时,nested class在Java中映射成inline class。比如,计算机专用开关电源类可以作为计算机类的nested class,但是电池组累就不一定适合作为计算机类的nested class,因为电池组类表述的是一个过于通用的对象,可能还被包含(Aggregation)于模型中的其他设备对象。class A nested in class B,则说明A是一个nested class,一般A是用来完成B中的某种重要功能的。
(2)innner class(一般是Java的说法)
Java内部类与C++嵌套类最大的不同就是在于是否有指向外部的引用上。静态内部类(inner class)意味着:创建一个static内部类对象,不需要一个外部类对象,不能从一个static内部类的一个对象访问一个外部类对象。
5.下列程序的输出结果是什么?
import java.util.*; import java.net.MalformedInputException; import java.net.URL; public class Test { private static final String[] URLNAMES = { "http://www.hust.edu.cn", //IP Address:202.114.0.245 "http://www.tsinghua.edu.cn", //IP Address:166.111.4.100 "http://admission.ucas.ac.cn/", //IP Address:210.77.30.83 "http://admission.gucas.ac.cn/", //IP Address:210.77.30.83 "http://Admission.ucas.ac.cn/", //IP Address:210.77.30.83 "http://www.amss.ac.cn", //IP Address:159.226.97.84 }; public static void main(String[] args) throws MalformedInputException { Set<URL> favorites = new HashSet<URL>(); for(String urlnames : URLNAMES){ favorites.add(new URL(urlnames)); } System.out.println(favorites.size()); } }A.一定是4 B.一定是5 C.一定是6 D.以上答案都不对(√)
解析:本题在联网状态下会输出4,这是由于URL的equals比对方式。根据equals的文档说明:如果两个主机名解析为同一个IP地址,责任为两个主机相同(即使主机名不等);如果有一个主机名无法解析,但是两个主机名相等(不区分大小写),或者两个主机名都为null,则也认为这两个主机相同。也就是说,如果两个URL的IP地址是相同的,那么这两个URL就是相等的。根据题干:
"http://admission.ucas.ac.cn/", //IP Address:210.77.30.83
"http://admission.gucas.ac.cn/", //IP Address:210.77.30.83
"http://Admission.ucas.ac.cn/",//IP Address:210.77.30.83
上面3个IP地址是相同的,都是210.77.30.83,所以在Set时都把他们当成同一个,答案为4。
如果在断网时,这些都无法解析成IP地址的,这时就要判断URL的名字,仅认为名字相同时才是相同的URL。"http://admission.ucas.ac.cn/"与"http://Admission.ucas.ac.cn/"因为不区分大小写,所以默认为两者相同,答案为5。
6.Anonymous Inner Class(匿名内部类)是否可以extends(继承)其他类,是否可以implements(实现)interface(接口)?
解析:匿名内部类不能继承,但是一个内部类可以作为一个接口,由另一个内部类实现。final类不能因为性能的原因将类定义为final的(除非程序的框架要求)。如果说整个类都是final的,就表明自己不希望从这个类继承,或者不允许其他任何人采取这种操作。将类定义成final的结果只是进行继承——没有更多的限制,而且所有的方法都默认为final,再也不可以覆盖。
7.String str="2014-04-01 14:00:00",要把这个串编程20140401140000,你会怎么做?
解析:
(1)不用正则表达式的方法(一般印象)
public static void main(String[] args) throws Exception{
String str = "2014-04-01 14:00:00";
str = str.replaceAll("-" , "");
str = str.replaceAll(":" , "");
str = str.replaceAll(" " , "");
System.out.println(str);
}(2)采用正则表达式(加分印象)
class RegularExpression{
public static void main(String[] args){
String str = "2014-04-01 14:00:00";
String str2 = "";
String[] result = str.split("\\D");
for(int i=0;i<result.length;i++){
System.out.println(result[i]);
str2 += result[i];
}
System.out.println(str2);
}
}
8.写一个Singleton出来。
答案:Singleton模式的主要作用是保证在Java应用程序中,一个类Class只有一个实例存在。Singleton通常有两种形式:
第一种形式:
public class Singleton{
private Singleton(){}
private static Singleton instance = new Singleton();
public static Singleton getInstance(){
return instance;
}
}
第二种形式:
//不用每次生成对象,只是第一次使用时生成实例,提高了效率
public class Singleton{
private static Singleton instance = null;
public static synchronized Singleton getInstance(){
if(instance == null){
instance = new Singleton();
}
return instance;
}
}
扩展知识:Java设计模式(共23种):
设计模式主要分三个类型:创建型、结构型和行为型。
创建型有:
Singleton,单例模式:保证一个类只有一个实例,并提供一个访问它的全局访问点
Abstract Factory,抽象工厂:提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们的具体类。
Factory Method,工厂方法:定义一个用于创建对象的接口,让子类决定实例化哪一个类,Factory Method使一个类的实例化延迟到了子类。
Builder,建造模式:将一个复杂对象的构建与他的表示相分离,使得同样的构建过程可以创建不同的表示。
Prototype,原型模式:用原型实例指定创建对象的种类,并且通过拷贝这些原型来创建新的对象。
行为型有:
Iterator,迭代器模式:提供一个方法顺序访问一个聚合对象的各个元素,而又不需要暴露该对象的内部表示。
Observer,观察者模式:定义对象间一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知自动更新。
Template Method,模板方法:定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,TemplateMethod使得子类可以不改变一个算法的结构即可以重定义该算法得某些特定步骤。
Command,命令模式:将一个请求封装为一个对象,从而使你可以用不同的请求对客户进行参数化,对请求排队和记录请求日志,以及支持可撤销的操作。
State,状态模式:允许对象在其内部状态改变时改变他的行为。对象看起来似乎改变了他的类。
Strategy,策略模式:定义一系列的算法,把他们一个个封装起来,并使他们可以互相替换,本模式使得算法可以独立于使用它们的客户。
China of Responsibility,职责链模式:使多个对象都有机会处理请求,从而避免请求的送发者和接收者之间的耦合关系
Mediator,中介者模式:用一个中介对象封装一些列的对象交互。
Visitor,访问者模式:表示一个作用于某对象结构中的各元素的操作,它使你可以在不改变各元素类的前提下定义作用于这个元素的新操作。
Interpreter,解释器模式:给定一个语言,定义他的文法的一个表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
Memento,备忘录模式:在不破坏对象的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
结构型有:
Composite,组合模式:将对象组合成树形结构以表示部分整体的关系,Composite使得用户对单个对象和组合对象的使用具有一致性。
Facade,外观模式:为子系统中的一组接口提供一致的界面,fa?ade提供了一高层接口,这个接口使得子系统更容易使用。
Proxy,代理模式:为其他对象提供一种代理以控制对这个对象的访问
Adapter,适配器模式:将一类的接口转换成客户希望的另外一个接口,Adapter模式使得原本由于接口不兼容而不能一起工作那些类可以一起工作。
Decrator,装饰模式:动态地给一个对象增加一些额外的职责,就增加的功能来说,Decorator模式相比生成子类更加灵活。
Bridge,桥模式:将抽象部分与它的实现部分相分离,使他们可以独立的变化。
Flyweight,享元模式,运用共享技术有效的支持大量细粒度的对象。
推荐一些设计模式的经典文章:
(1)工厂模式:http://www.cnblogs.com/poissonnotes/archive/2010/12/01/1893871.html
(2)建造模式:http://www.cnblogs.com/cbf4life/archive/2010/01/14/1647710.html
(3)工厂方法模式:http://www.cnblogs.com/cbf4life/archive/2009/12/20/1628494.html
(4)原始模型模式:http://blog.csdn.net/tj19832/article/details/1164167
(5)单例模式:http://cantellow.iteye.com/blog/838473
(6)适配器模式(也叫变压器模式):http://www.cnblogs.com/wangjq/archive/2012/07/09/2582485.html
(7)桥梁模式:http://blog.csdn.net/ymeng_bupt/article/details/6834406
(8)合成模式:http://blog.csdn.net/yeyhan/article/details/20452223
(9)装饰模式:http://www.cnblogs.com/god_bless_you/archive/2010/06/10/1755212.html
(10)门面模式:http://www.cnblogs.com/skywang/articles/1375447.html
(11)享元模式:http://blog.csdn.net/wanghao72214/article/details/4046182
(12)代理模式:http://www.cnblogs.com/cbf4life/archive/2010/01/27/1657438.html
(13)责任链模式:http://www.cnblogs.com/java-my-life/archive/2012/05/28/2516865.html
(14)命令模式:http://www.cnblogs.com/devinzhang/archive/2012/01/06/2315235.html
(15)解释器模式:http://www.cnblogs.com/cbf4life/archive/2009/12/17/1626125.html
(16)迭代子模式:http://www.cnblogs.com/java-my-life/archive/2012/05/22/2511506.html
(17)调停者模式:http://www.cnblogs.com/java-my-life/archive/2012/06/20/2554024.html
(18)备忘录模式:http://www.cnblogs.com/ywqu/archive/2010/01/25/1655581.html
(19)观察者模式:http://www.cnblogs.com/wangjq/archive/2012/07/12/2587966.html
(20)状态模式:http://blog.csdn.net/hguisu/article/details/7557252
(21)策略模式:http://www.cnblogs.com/justinw/archive/2007/02/06/641414.html
(22)模板方法模式:http://blog.csdn.net/lenotang/article/details/2911246
(23)访问者模式:http://blog.csdn.net/xiaoquanhuang/article/details/6311319
9.Spring都有哪些特点?为什么要使用Spring?
答案:
(1)Spring的特点:①Spring不同于其他的Framework,它主要提供的是一种管理你的业务对象的方法。②Spring有分层的体系结构,意味着你能选择仅仅使用它的任何一个独立的部分,而其他的仍然是用你的相关实现。③它的设计从一开始就是要帮助你编写易于测试的代码,Spring是使用测试驱动开发(TDD)工程的理想框架。④Spring不会给你的工程添加其他的框架依赖,同时Spring又可以称得上是一个一揽子解决方案,提供了一个典型应用所需要的大部分基础架构。
(2)Spring的使用原因:①Spring能有效地组织你的中间层对象。②Spring能消除在许多工程中常见的对Singleton的过多使用。③通过一种在不同应用程序和项目间一致的方法来处理配置文件,消除各种自定义格式的属性文件的需要,仅仅需要看看类的JavaBean属性。Inversion of Control的使用帮助完成了这种简化。④能够很容易培养你面向接口而不是面向的习惯。⑤Spring的设计会让你使用它创建的应用尽可能少的依赖于他的APIs,在Spring应用中的大多数业务对象没有依赖于Spring。⑥使用Spring构建的应用程序易于单元测试。⑦Spring使EJB成为一个实现选择,而不是必需的选择。你可以用POJOs或者local EJBs来实现业务接口,却不会影响到调用代码。⑧Spring提供一些Web应用上的EJB的替代方案,比如用AOP提供声明性事务管理。⑨Spring为数据存储提供了一个一致的框架,不论是使用JDBC还是O/R mapping的产品。
10.hibernate工作原理是什么?为什么要使用hibernate?
解析:hibernate可以理解为是一个中间件,负责把Java程序的SQL语句接收过来并发送到数据库,而数据库返回来的信息由hibernate接收后直接生成一个对象传给Java。
答案:
hibernate的工作原理如下:①读取并解析配置文件。②读取并解析映射信息,创建SessionFactory。③打开Session。④创建事务Transaction。⑤持久化操作。⑥提交事务。⑦关闭Session。⑧关闭sessionFactory。
使用hibernate的原因如下:①对JDBC访问数据库的代码做了封装,大大简化了数据库访问层繁琐的重复性代码。②hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现,在很大程度上简化了DAO层的编码工作。③hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。④hibernate的性能非常好,因为它是一个轻量级框架,映射的灵活性很出色。它支持各种关系型数据库,从一对一到多对多的各种复杂关系。
11.当你编译和运行下面的代码时,会出现下面的那种情况?
public class Outter{
static boolean aaa;
public static void main(String[] args){
System.out.println(aaa);
}
}
A.编译时错误 B.编译通过并输出结果false
C.编译通过并输出结果true D.编译通过并输出结果null
解析:定义在雷尼面的变量会被赋予一个默认的值(初始化),而布尔值个默认初始值是false,因此选B。
12.Which of the choices below correctly describes the amount of time used by the following code?
n=10; for(i=1;i<n;) for(j=1;j<n;j+=n/2) for(k=1;k<n;k=2*k) x += 2;
A.O(n^3) B.O(n^2 log n) C.O(n(log n)*2) D.(n log n)(√)
解析:一般来说,要选择时间复杂度量级较低的算法。
T(n)=O(f(n))
O(1)<O(log2 n)<O(n)<O(n log2 n)<O(n^2)<O(n^3)<O(2^n)
13.用最有效率的方法实现10×9的操作?
解析:10<<3+10
14.下面代码中,请说出符合垃圾回收器(GC)的收集标准的行有哪些?
1. Object aobj = new Object(); 2. Object bobj = new Object(); 3. Object cobj = new Object(); 4. aobj = bobj; 5. aobj = cobj; 6. cobj = null; 7. aobj = null;解析:第7行。注意,这类题型时可能遇到的最难题型了。
行1~3分别创建了Object类的3个对象:aobj、bobj和cobj。
行4:此时对象aobj的句柄指向bobj,所以该行的执行不能使aobj符合GC的收集标准。
行5:此时对象aobj的句柄指向cobj,所以该行的执行不能使aobj符合GC的收集标准。
行6:此时仍没有任何一个对象符合GC的收集标准。
行7:对象cobj符合了GC的收集标准,因为cobj的句柄指向单一的地址空间。在第6行的时候,cobj已经被赋值为null,但是由于cobj同时还指向了aobj,所以此时cobj并不符合GC的收集标准。而在第7行,aobj所指向的地址空间已经被完全赋予了空值。所以,cobj最终符合了GC的收集标准。但对于aobj和bobj,仍然无法判断其是否符合收集标准。
总之,在Java语言中,判断一块内存空间是否符合GC收集标准的标准之后以下两个:
(1)给对象赋予了空值null,以后再没有调用过。
(2)给对象赋予了新值,即重新分配了内存空间。
15.下列代码有什么错误?
public class Test{
public static void main(String[] args){
List<String> list = new ArrayList<String>();
list.add("Welcome ");
list.add("to ");
list.add("HUST");
for(Iterator i = list.iterator();i.hasNest();){
String s = i.next();
System.out.println(s);
}
}
}
解析:本题会发生编译错误。
这道题考察Java泛型的理解,在代码中可以看到List泛型参数是String,也就是说,List只允许存放String类型的数据。该题的错误之处在于
for(Iterator i = list.iterator();i.hasNext();)
这一句上,通过API文档可以看到Iterator迭代器也是需要采用泛型参数的。如果没有加泛型参数,i.next();返回的结果是Object类型,所以
String s = i.next();
就会报类型不匹配的错误。为了类型安全,应该改为:
import java.util.*;
public class Test{
public static void main(String[] args){
List<String> list = new ArrayList<String>();
list.add("Welcome ");
list.add("to ");
list.add("HUST");
for(Iterator<String> i = list.iterator();i.hasNest();){
String s = i.next();
System.out.println(s);
}
}
}
16.进程进入等待状态有哪几种方式?
解析:本题属于操作系统面试例题。
答案:进程进入等待状态有3种方式:①CPU调度给优先级更高的thread,原先thread进入等待状态。②阻塞的thread获得资源或者信号,进入等待状态。③时间片轮转的情况下,如果时间片到了,也将进入等待状态。
17.简述synchronized和java.util.concurrent.locks.Lock的异同。
答案:主要相同点是,Lock能完成synchronized所实现的所有功能。主要不同点是,Lock有比synchronized更精确的线程语义和更好的性能。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放。
18.在JDBC连接数据库编程应用开发中,利用哪个类可以实现连接数据库?
A.Connection接口(√) B.PreparedStatement类
C.CallableStatement类 D.Statement类
解析:本题涉及以下知识点:JDBC数据库连接问题。PreparedStatement类、CallableStatement类、Statement类这三个类的区别。三个选项中只有Connection接口可以用于连接数据库。
19.请用三叉链表存储二叉树。
解析:三叉链表存储的思想是让每个节点不仅“记住”它的左、右两个子节点,还要记住它的父节点,因此需要为每个节点增加left、right和parent三个指针,分别引用该节点的左、右两个子节点和父节点。因此,三叉链表存储的每个节点有如图所示的结构。
代码如下:
public class ThreeLinkBinTree<E>{
public static class TreeNode{
Object data;
TreeNode left;
TreeNode right;
TreeNode parent;
public TreeNode(){}
public TreeNode(Object data){
//Consructor...
}
public TreeNode(Object data, TreeNode left, TreeNode right, TreeNode parent){
//Consructor...
}
}
private TreeNode root;
//以默认的构造器来创建二叉树
public ThreeLinkBinTree(){
this.root = new TreeNode;
}
//以指定根元素来创建二叉树
public ThreeLinkBinTree(E data){
this.root = new TreeNode(data);
}
/**
* 为指定节点添加子节点
* @param index 需要添加子节点的父节点的索引
* @param data 新子节点的数据
* @param isLeft 是否为左节点
* @return 新增的节点
*/
public TreeNode addNode(TreeNode parent, E data, boolean isLeft){
//Method...
}
//判断二叉树是否为空
public boolean empty(){
//Method...
}
//返回根节点
public TreeNode root(){
//Method...
}
//返回指定节点(非叶子)的左子结点,当左子结点不存在时返回null
public E leftChild(TreeNode parent){
//Method...
}
//返回指定节点(非叶子)的右子结点,当右子结点不存在时返回null
public E rightChild(TreeNode parent){
//Method...
}
//返回该二叉树的深度
public int deep(){
//Method...
}
//这是一个递归方法:每棵子树的深度为其所有子树的最大深度+1
private int deep(TreeNode node){
//Method...
}
}
20.请写出如下代码的输出结果。
class Person{
String name;
int age;
public Person(String name, int age){
this.name = name;
this.age = age;
}
public String toString(){
return "Person[name=" + name + ", age=" + age + "]";
}
}
public class SoftReferenceTest{
public static void main(String[] args) throws Exception{
SoftReference<Person>[] people = new SoftReference[10000];
for(int i=0;i<people.length;i++){
people[i] = new SoftReference<Person>(
new Person(
"名字" + i, (i + 1) * 4 % 100
)
);
}
System.out.println(people[2].get());
System.out.println(people[4].get());
System.gc();
System.runFinalization();
System.out.println(people[2].get());
System.out.println(people[4].get());
}
}解析:
主要考察Java内存回收机制中的引用的使用。在JVM内存管理中,有如下几个概念,强引用,软引用(SoftReference),弱引用(WeakReference)和虚引用(PhantomReference)。在本题中,使用软引用是一个非常好的方案。当堆内存空间足够时,垃圾回收机制不会回收Person对象,可以随时重新访问一个较好的方案。当堆内存空间不足时,系统也可以回收软引用所引用的Person对象,从而提高程序运行性能,避免垃圾回收。
因此,当内存充足时,运行结果与强引用的功能类似:
修改上面程序的命令(为JVM指定使用较小的堆内存)如下:
java -Xmx2m -Xms2m SoftReferenceTest
运行上面的命令,可以看到如下结果:

使用java -Xmx2m -Xms2m SoftReferenceTest命令强制堆内存只有2m,而且程序创建一个长度为10000的数组,这样将使系统内存紧张。在这种情况下,软引用所引用的Java对象将会内垃圾回收,因此会出现这个结果。
21.以下代码的运行结果是什么?
class Base{
int i;
Base(){
add(1);
System.out.println(i);
}
void add(int v){
i += v;
System.out.println(i);
}
void print(){
System.out.println(i);
}
}
class MyBase extends Base{
MyBase(){
add(2);
}
void add(int v){
i += v*2;
System.out.println(i);
}
}
public class TestClass{
public static void main(String[] args){
go(new MyBase());
//System.out.println();
}
static void go(Base b){
b.add(8);
//b.print();
}
}
A.12 B.11 C.22(√) D.21
解析:程序流程是这样的:在主函数中,首先执行new MyBase(),在这个过程中,子类会首先调用父类的构造函数;在父类的构造函数Base()中执行add()方法。在这里需要注意,这个add方法由于是在新建MyBase对象时调用的,将会首先查找MyBase类中是否有此方法。所以,Base()函数中的add(1)实际上是:
void add(int v){
i += v * 2;
System.out.println(i);
}
此时i的值即为2.在打印两个2之后,父类的构造函数执行完毕,执行子类的构造函数,即MyBase(),这里的add(2)当然也是子类的。i的值就变为了6。
22. 下面哪些是Thread类的方法()
A start() B run() C exit() D getPriority()
答案:ABD
23. 下面关于java.lang.Exception类的说法正确的是()
A 继承自Throwable B Serialable CD 不记得,反正不正确
答案:A
解析:Java异常的基类为java.lang.Throwable,java.lang.Error和java.lang.Exception继承 Throwable,RuntimeException和其它的Exception等继承Exception,具体的RuntimeException继承RuntimeException。java.lang.Exception: Throwable的子类,用于指示一种合理的程序想去catch的条件。即它仅仅是一种程序运行条件,而非严重错误,并且鼓励用户程序去catch它。checked exceptions: 通常是从一个可以恢复的程序中抛出来的,并且最好能够从这种异常中使用程序恢复。比如FileNotFoundException, ParseException等。检查了的异常发生在编译阶段,必须要使用try…catch(或者throws)否则编译不通过。unchecked exceptions: 通常是如果一切正常的话本不该发生的异常,但是的确发生了。发生在运行期,具有不确定性,主要是由于程序的逻辑问题所引起的。比如ArrayIndexOutOfBoundException, ClassCastException等。从语言本身的角度讲,程序不该去catch这类异常,虽然能够从诸如RuntimeException这样的异常中catch并恢复,但是并不鼓励终端程序员这么做,因为完全没要必要。因为这类错误本身就是bug,应该被修复,出现此类错误时程序就应该立即停止执行。 因此,面对Errors和unchecked exceptions应该让程序自动终止执行,程序员不该做诸如try/catch这样的事情,而是应该查明原因,修改代码逻辑。
扩展:错误和异常的区别(Error vs Exception)
1) java.lang.Error: Throwable的子类,用于标记严重错误。合理的应用程序不应该去try/catch这种错误。绝大多数的错误都是非正常的,就根本不该出现的。
2) Error和RuntimeException 及其子类都是未检查的异常(unchecked exceptions),而所有其他的Exception类都是检查了的异常(checked exceptions).
RuntimeException:RuntimeException体系包括错误的类型转换、数组越界访问和试图访问空指针等等。
处理RuntimeException的原则是:如果出现 RuntimeException,那么一定是程序员的错误。例如,可以通过检查数组下标和数组边界来避免数组越界访问异常。其他(IOException等等)checked异常一般是外部错误,例如试图从文件尾后读取数据等,这并不是程序本身的错误,而是在应用环境中出现的外部错误。
24. 下面程序的运行结果是()
String str1 = "hello";
String str2 = "he" + new String("llo");
System.err.println(str1 == str2);
解析:System.err.println(str1 == str2);比较的是str1和str2在内存中的地址,而非值。
25. 下列说法正确的有()
A. class中的constructor不可省略
B. constructor必须与class同名,但方法不能与class同名
C. constructor在一个对象被new时执行
D.一个class只能定义一个constructor
答案:C
解析:这里可能会有误区,其实普通的类方法是可以和类名同名的,和构造方法唯一的区分就是,构造方法没有返回值。
26. 具体选项不记得,但用到的知识如下:
String []a = new String[10];
则:a[0]~a[9] = null
a.length = 10
如果是int []a = new int[10];
则:a[0]~a[9] = 0
a.length = 10
27. 下面程序的运行结果:()
public static void main(String args[]) {
Thread t = new Thread() {
public void run() {
pong();
}
};
t.run();
System.out.print("ping");
}
static void pong() {
System.out.print("pong");
}
A pingpong B pongping C pingpong和pongping都有可能 D 都不输出
答案:B
解析:去了static用类对象引用仍为B,对Thread的运行机制不是很了解,不知道为啥,欢迎大家补充。
28. 下列属于关系型数据库的是()
A. Oracle B MySql C IMS D MongoDB
答案:AB
解答:IMS(Information Management System )数据库是IBM公司开发的两种数据库类型之一;
一种是关系数据库,典型代表产品:DB2;
另一种则是层次数据库,代表产品:IMS层次数据库。
非关系型数据库有MongoDB、memcachedb、Redis等。
29. GC线程是否为守护线程?()
答案:是
解析:线程分为守护线程和非守护线程(即用户线程)。
30. volatile关键字是否能保证线程安全?()
答案:不能
解析:volatile关键字用在多线程同步中,可保证读取的可见性,JVM只是保证从主内存加载到线程工作内存的值是最新的读取值,而非cache中。但多个线程对
volatile的写操作,无法保证线程安全。例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值,在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6;线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6;导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
31. 下列说法正确的是()
A LinkedList继承自List
B AbstractSet继承自Set
C HashSet继承自AbstractSet
D WeakMap继承自HashMap
答案:AC
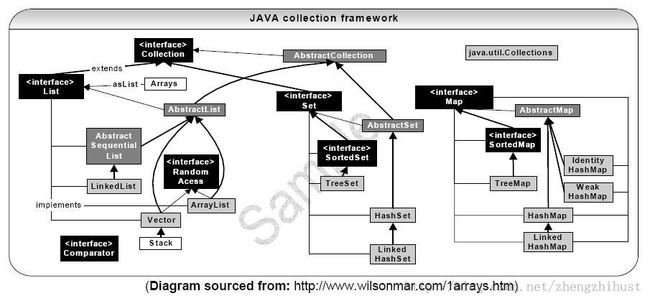
解析:下面是一张下载的Java中的集合类型的继承关系图,一目了然。
32. 存在使i + 1 < i的数吗()
答案:存在
解析:如果i为int型,那么当i为int能表示的最大整数时,i+1就溢出变成负数了,此时不就<i了吗。
扩展:存在使i > j || i <= j不成立的数吗()
答案:存在
解析:比如Double.NaN或Float.NaN。
33. 0.6332的数据类型是()
A float B double C Float D Double
答案:B
解析:默认为double型,如果为float型需要加上f显示说明,即0.6332f
34. 下面哪个流类属于面向字符的输入流( )
A BufferedWriter B FileInputStream C ObjectInputStream D InputStreamReader
答案:A
解析:Java的IO操作中有面向字节(Byte)和面向字符(Character)两种方式。
面向字节的操作为以8位为单位对二进制的数据进行操作,对数据不进行转换,这些类都是InputStream和OutputStream的子类。
面向字符的操作为以字符为单位对数据进行操作,在读的时候将二进制数据转为字符,在写的时候将字符转为二进制数据,这些类都是Reader和Writer的子类。
总结:
以InputStream(输入)/OutputStream(输出)为后缀的是字节流;
以Reader(输入)/Writer(输出)为后缀的是字符流。
扩展:Java流类图结构,一目了然,解决大部分选择题:
35. Java接口的修饰符可以为()
A private B protected C final D abstract
答案:CD
解析:接口很重要,为了说明情况,这里稍微啰嗦点:
(1)接口用于描述系统对外提供的所有服务,因此接口中的成员常量和方法都必须是公开(public)类型的,确保外部使用者能访问它们;
(2)接口仅仅描述系统能做什么,但不指明如何去做,所以接口中的方法都是抽象(abstract)方法;
(3)接口不涉及和任何具体实例相关的细节,因此接口没有构造方法,不能被实例化,没有实例变量,只有静态(static)变量;
(4)接口的中的变量是所有实现类共有的,既然共有,肯定是不变的东西,因为变化的东西也不能够算共有。所以变量是不可变(final)类型,也就是常量了。
(5) 接口中不可以定义变量?如果接口可以定义变量,但是接口中的方法又都是抽象的,在接口中无法通过行为来修改属性。有的人会说了,没有关系,可以通过 实现接口的对象的行为来修改接口中的属性。这当然没有问题,但是考虑这样的情况。如果接口 A 中有一个public 访问权限的静态变量 a。按照 Java 的语义,我们可以不通过实现接口的对象来访问变量 a,通过 A.a = xxx; 就可以改变接口中的变量 a 的值了。正如抽象类中是可以这样做的,那么实现接口 A 的所有对象也都会自动拥有这一改变后的 a 的值了,也就是说一个地方改变了 a,所有这些对象中 a 的值也都跟着变了。这和抽象类有什么区别呢,怎么体现接口更高的抽象级别呢,怎么体现接口提供的统一的协议呢,那还要接口这种抽象来做什么呢?所以接口中 不能出现变量,如果有变量,就和接口提供的统一的抽象这种思想是抵触的。所以接口中的属性必然是常量,只能读不能改,这样才能为实现接口的对象提供一个统 一的属性。
通俗的讲,你认为是要变化的东西,就放在你自己的实现中,不能放在接口中去,接口只是对一类事物的属性和行为更高层次的抽象。对修改关闭,对扩展(不同的实现 implements)开放,接口是对开闭原则的一种体现。
所以:
接口的方法默认是public abstract;
接口中不可以定义变量即只能定义常量(加上final修饰就会变成常量)。所以接口的属性默认是public static final 常量,且必须赋初值。
注意:final和abstract不能同时出现。
36. 不通过构造函数也能创建对象吗()
A 是 B 否
答案:A
解析:Java创建对象的几种方式(重要):
(1) 用new语句创建对象,这是最常见的创建对象的方法。
(2) 运用反射手段,调用java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。
(3) 调用对象的clone()方法。
(4) 运用反序列化手段,调用java.io.ObjectInputStream对象的 readObject()方法。
(1)和(2)都会明确的显式的调用构造函数 ;(3)是在内存上对已有对象的影印,所以不会调用构造函数 ;(4)是从文件中还原类的对象,也不会调用构造函数。
37. ArrayList list = new ArrayList(20);中的list扩充几次()
A 0 B 1 C 2 D 3
答案:A
解析:这里有点迷惑人,大家都知道默认ArrayList的长度是10个,所以如果你要往list里添加20个元素肯定要扩充一次(扩充为原来的1.5倍),但是这里显示指明了需要多少空间,所以就一次性为你分配这么多空间,也就是不需要扩充了。
38. 下面哪些是对称加密算法()
A DES B AES C DSA D RSA
答案:AB
解析:
常用的对称加密算法有:DES、3DES、RC2、RC4、AES
常用的非对称加密算法有:RSA、DSA、ECC
使用单向散列函数的加密算法:MD5、SHA
39.新建一个流对象,下面哪个选项的代码是错误的?()
A)new BufferedWriter(new FileWriter("a.txt"));
B)new BufferedReader(new FileInputStream("a.dat"));
C)new GZIPOutputStream(new FileOutputStream("a.zip"));
D)new ObjectInputStream(new FileInputStream("a.dat"));
答案:B
解析:请记得13题的那个图吗?Reader只能用FileReader进行实例化。
40. 下面程序能正常运行吗()
public class NULL {
public static void haha(){
System.out.println("haha");
}
public static void main(String[] args) {
((NULL)null).haha();
}
}
答案:能正常运行
解析:输出为haha,因为null值可以强制转换为任何java类类型,(String)null也是合法的。但null强制转换后是无效对象,其返回值还是为null,而static方法的调用是和类名绑定的,不借助对象进行访问所以能正确输出。反过来,没有static修饰就只能用对象进行访问,使用null调用对象肯定会报空指针错了。这里和C++很类似。
41. 下面程序的运行结果是什么()
class HelloA {
public HelloA() {
System.out.println("HelloA");
}
{ System.out.println("I'm A class"); }
static { System.out.println("static A"); }
}
public class HelloB extends HelloA {
public HelloB() {
System.out.println("HelloB");
}
{ System.out.println("I'm B class"); }
static { System.out.println("static B"); }
public static void main(String[] args) {
new HelloB();
}
}答案:
static A static B I'm A class HelloA I'm B class HelloB
解析:说实话我觉得这题很好,考查静态语句块、构造语句块(就是只有大括号的那块)以及构造函数的执行顺序。
对象的初始化顺序:(1)类加载之后,按从上到下(从父类到子类)执行被static修饰的语句;(2)当static语句执行完之后,再执行main方法;(3)如果有语句new了自身的对象,将从上到下执行构造代码块、构造器(两者可以说绑定在一起)。
下面稍微修改下上面的代码,以便更清晰的说明情况:
class HelloA {
public HelloA() {
System.out.println("HelloA");
}
{ System.out.println("I'm A class"); }
static { System.out.println("static A"); }
}
public class HelloB extends HelloA {
public HelloB() {
System.out.println("HelloB");
}
{ System.out.println("I'm B class"); }
static { System.out.println("static B"); }
public static void main(String[] args) {
System.out.println("-------main start-------");
new HelloB();
new HelloB();
System.out.println("-------main end-------");
}
}
此时输出结果为:
static A static B -------main start------- I'm A class HelloA I'm B class HelloB I'm A class HelloA I'm B class HelloB -------main end-------42. getCustomerInfo() 方法如下, try 中可以捕获三种类型的异常,如果在该方法运行中产生了一个 IOException ,将会输出什么结果:
public void getCustomerInfo() {
try {
// do something that may cause an Exception
} catch (java.io.FileNotFoundException ex) {
System.out.print("FileNotFoundException!");
} catch (java.io.IOException ex) {
System.out.print("IOException!");
} catch (java.lang.Exception ex) {
System.out.print("Exception!");
}
}
A IOException!
BIOException!Exception!
CFileNotFoundException!IOException!
DFileNotFoundException!IOException!Exception!
答案:A
解析:考察多个catch语句块的执行顺序。当用多个catch语句时,catch语句块在次序上有先后之分。从最前面的catch语句块依次先后进行异常类型匹配,这样如果父异常在子异常类之前,那么首先匹配的将是父异常类,子异常类将不会获得匹配的机会,也即子异常类型所在的catch语句块将是不可到达的语句。所以,一般将父类异常类即Exception老大放在catch语句块的最后一个。
43. 下面代码的运行结果为:
import java.io.*;
import java.util.*;
public class foo{
public static void main (String[] args){
String s;
System.out.println("s=" + s);
}
}
A 代码得到编译,并输出“s=”
B 代码得到编译,并输出“s=null”
C 由于String s没有初始化,代码不能编译通过
D 代码得到编译,但捕获到 NullPointException异常答案:C
解析:开始以为会输出null什么的,运行后才发现Java中所有定义的基本类型或对象都必须初始化才能输出值。
44. System.out.println("5" + 2);的输出结果应该是()。
A 52 B7 C2 D5
答案:A
解析:没啥好说的,Java会自动将2转换为字符串。
45. 指出下列程序运行的结果 ()
public class Example {
String str = new String("good");
char[] ch = { 'a', 'b', 'c' };
public static void main(String args[]) {
Example ex = new Example();
ex.change(ex.str, ex.ch);
System.out.print(ex.str + " and ");
System.out.print(ex.ch);
}
public void change(String str, char ch[]) {
str = "test ok";
ch[0] = 'g';
}
}
A、 good and abc
B、 good and gbc
C、 test ok and abc
D、 test ok and gbc答案:B
解析:大家可能以为Java中String和数组都是对象所以肯定是对象引用,然后就会选D,其实这是个很大的误区:因为在java里没有引用传递,只有值传递。这个值指的是实参的地址的拷贝,得到这个拷贝地址后,你可以通过它修改这个地址的内容(引用不变),因为此时这个内容的地址和原地址是同一地址,但是你不能改变这个地址本身使其重新引用其它的对象,也就是值传递,可能说的不是很清楚,下面给出一个完整的能说明情况的例子吧:
package test;
/**
* @description Java中没有引用传递只有值传递
*
* @author Alexia
* @date 2013-10-16
*
*/
class Person {
private String name;
private String sex;
public Person(String x, String y) {
this.name = x;
this.sex = y;
}
// 重写toString()方法,方便输出
public String toString() {
return name + " " + sex;
}
// 交换对象引用
public static void swapObject(Person p1, Person p2) {
Person tmp = p1;
p1 = p2;
p2 = tmp;
}
// 交换基本类型
public static void swapInt(int a, int b) {
int tmp = a;
a = b;
b = tmp;
}
// 交换对象数组
public static void swapObjectArray(Person[] p1, Person[] p2) {
Person[] tmp = p1;
p1 = p2;
p2 = tmp;
}
// 交换基本类型数组
public static void swapIntArray(int[] x, int[] y) {
int[] tmp = x;
x = y;
y = tmp;
}
// 改变对象数组中的内容
public static void changeObjectArray(Person[] p1, Person[] p2) {
Person tmp = p1[1];
p1[1] = p2[1];
p2[1] = tmp;
// 再将p1[1]修改
Person p = new Person("wjl", "male");
p1[1] = p;
}
// 改变基本类型数组中的内容
public static void changeIntArray(int[] x, int[] y) {
int tmp = x[1];
x[1] = y[1];
y[1] = tmp;
x[1] = 5;
}
}
public class ByValueTest {
public static void main(String[] args) {
// 建立并构造两个对象
Person p1 = new Person("Alexia", "female");
Person p2 = new Person("Edward", "male");
System.out.println("对象交换前:p1 = " + p1.toString());
System.out.println("对象交换前:p2 = " + p2.toString());
// 交换p1对象和p2对象
Person.swapObject(p1, p2);
// 从交换结果中看出,实际对象并未交换
System.out.println("\n对象交换后:p1 = " + p1.toString());
System.out.println("对象交换后:p2 = " + p2.toString());
// 建立两个对象数组
Person[] arraya = new Person[2];
Person[] arrayb = new Person[2];
// 分别构造数组对象
arraya[0] = new Person("Alexia", "female");
arraya[1] = new Person("Edward", "male");
arrayb[0] = new Person("jmwang", "female");
arrayb[1] = new Person("hwu", "male");
System.out.println('\n' + "对象数组交换前:arraya[0] = "
+ arraya[0].toString() + ", arraya[1] = "
+ arraya[1].toString());
System.out.println("对象数组交换前:arrayb[0] = "
+ arrayb[0].toString() + ", arrayb[1] = "
+ arrayb[1].toString());
// 交换这两个对象数组
Person.swapObjectArray(arraya, arrayb);
System.out.println('\n' + "对象数组交换后:arraya[0] = "
+ arraya[0].toString() + ", arraya[1] = "
+ arraya[1].toString());
System.out.println("对象数组交换后:arrayb[0] = "
+ arrayb[0].toString() + ", arrayb[1] = "
+ arrayb[1].toString());
// 建立两个普通数组
int[] a = new int[2];
int[] b = new int[2];
// 给数组个元素赋值
for (int i = 0; i < a.length; i++) {
a[i] = i;
b[i] = i + 1;
}
System.out.println('\n' + "基本类型数组交换前:a[0] = " + a[0] + ", a[1] = " + a[1]);
System.out.println("基本类型数组交换前:b[0] = " + b[0] + ", b[1] = " + b[1]);
// 交换两个基本类型数组
Person.swapIntArray(a, b);
System.out.println('\n' + "基本类型数组交换后:a[0] = " + a[0] + ", a[1] = " + a[1]);
System.out.println("基本类型数组交换后:b[0] = " + b[0] + ", b[1] = " + b[1]);
// 改变对象数组的内容
Person.changeObjectArray(arraya, arrayb);
System.out.println('\n' + "对象数组内容交换并改变后:arraya[1] = " + arraya[1].toString());
System.out.println("对象数组内容交换并改变后:arrayb[1] = " + arrayb[1].toString());
// 改变基本类型数组的内容
Person.changeIntArray(a, b);
System.out.println('\n' + "基本类型数组内容交换并改变后:a[1] = " + a[1]);
System.out.println("基本类型数组内容交换并改变后:b[1] = " + b[1]);
}
}程序有些啰嗦,但能反映问题,该程序运行结果为:
对象交换前:p1 = Alexia female 对象交换前:p2 = Edward male 对象交换后:p1 = Alexia female 对象交换后:p2 = Edward male 对象数组交换前:arraya[0] = Alexia female, arraya[1] = Edward male 对象数组交换前:arrayb[0] = jmwang female, arrayb[1] = hwu male 对象数组交换后:arraya[0] = Alexia female, arraya[1] = Edward male 对象数组交换后:arrayb[0] = jmwang female, arrayb[1] = hwu male 基本类型数组交换前:a[0] = 0, a[1] = 1 基本类型数组交换前:b[0] = 1, b[1] = 2 基本类型数组交换后:a[0] = 0, a[1] = 1 基本类型数组交换后:b[0] = 1, b[1] = 2 对象数组内容交换并改变后:arraya[1] = wjl male 对象数组内容交换并改变后:arrayb[1] = Edward male 基本类型数组内容交换并改变后:a[1] = 5 基本类型数组内容交换并改变后:b[1] = 1说明:不管是对象、基本类型还是对象数组、基本类型数组,在函数中都不能改变其实际地址但能改变其中的内容。
A FileInputStream in=new FileInputStream("file.dat"); in.skip(9); int c=in.read();
B FileInputStream in=new FileInputStream("file.dat"); in.skip(10); int c=in.read();
C FileInputStream in=new FileInputStream("file.dat"); int c=in.read();
D RandomAccessFile in=new RandomAccessFile("file.dat"); in.skip(9); int c=in.readByte();
答案:A、D
解析:long skip(long n)作用是跳过n个字节不读,主要用在包装流中的,因为一般流(如FileInputStream)只能顺序一个一个的读不能跳跃读,但是包装流可以用skip方法跳跃读取。那么什么是包装流呢?各种字节节点流类,它们都只具有读写字节内容的方法,以FileInputStream与FileOutputStream为例,它们只能在文件中读取或者向文件中写入字节,在实际应用中我们往往需要在文件中读取或者写入各种类型的数据,就必须先将其他类型的数据转换成字节数组后写入文件,或者从文件中读取到的字节数组转换成其他数据类型,想想都很麻烦!!因此想通过FileOutputStream将一个浮点小数写入到文件中或将一个整数写入到文件时是非常困难的。这时就需要包装类DataInputStream/DataOutputStream,它提供了往各种输入输出流对象中读入或写入各种类型的数据的方法。
DataInputStream/DataOutputStream并没有对应到任何具体的流设备,一定要给它传递一个对应具体流设备的输入或输出流对象,完成类似 DataInputStream/DataOutputStream功能的类就是一个包装类,也叫过滤流类或处理流类。它对InputOutStream/OutputStream流类进行了包装,使编程人员使用起来更方便。其中DataInputStream包装类的构造函数语法:public DataInputStream(InputStream in)。包装类也可以包装另外一个包装类。
首先BC肯定 是错的,那A正确吗?按上面的解析应该也不对,但我试了下,发现A也是正确的,与网上解析的资料有些出入,下面是我的code:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileStreamTest {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
FileOutputStream out = new FileOutputStream("file.dat");
byte[] b = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
out.write(b);
out.close();
FileInputStream in = new FileInputStream("file.dat");
in.skip(9); // 跳过前面的9个字节
int c = in.read();
System.out.println(c); // 输出为10
in.close();
}
}那么D呢,
RandomAccessFile是IO包的类,但是其自成一派,从Object直接继承而来。可以对文件进行读取和写入。支持文件的随机访问,即可以随机读取文件中的某个位置内容,这么说RandomAccessFile肯定可以达到题目的要求,但是选项有些错误,比如RandomAccessFile的初始化是两个参数而非一个参数,采用的跳跃读取方法是skipBytes()而非skip(),即正确的写法是:
RandomAccessFile in = new RandomAccessFile("file.dat", "r");
in.skipBytes(9);
int c = in.readByte();
这样也能读到第十个字节,也就是A和D都能读到第十个字节。
47. 下面的方法,当输入为2的时候返回值是多少?()
public static int getValue(int i) {
int result = 0;
switch (i) {
case 1:
result = result + i;
case 2:
result = result + i * 2;
case 3:
result = result + i * 3;
}
return result;
}
A0 B2 C4 D10
答案:D
解析:注意这里case后面没有加break,所以从case 2开始一直往下运行。
48. 选项中哪一行代码可以替换题目中//add code here而不产生编译错误?()
public abstract class MyClass {
public int constInt = 5;
//add code here
public void method() {
}
}
Apublic abstract void method(int a);
B constInt = constInt + 5;
C public int method();
D public abstract void anotherMethod() {}
答案:A
解析:考察抽象类的使用。
抽象类遵循的原则:
(1)接口是公开的,里面不能有私有的方法或变量,是用于让别人使用的,而抽象类是可以有私有方法或私有变量的。
(2)abstract class 在 Java 语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface,实现多重继承。接口还有标识(里面没有任何方法,如Remote接口)和数据共享(里面的变量全是常量)的作用。
(3)在abstract class 中可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface中,只能够有静态的不能被修改的数据成员(也就是必须是 static final的,不过在 interface中一般不定义数据成员),所有的成员方法默认都是 public abstract 类型的。
(4)abstract class和interface所反映出的设计理念不同。其实abstract class表示的是"is-a"关系,interface表示的是"has-a"关系。
(5)实现接口的一定要实现接口里定义的所有方法,而实现抽象类可以有选择地重写需要用到的方法,一般的应用里,最顶级的是接口,然后是抽象类实现接口,最后才到具体类实现。抽象类中可以有非抽象方法。接口中则不能有实现方法。
(6)接口中定义的变量默认是public static final 型,且必须给其初值,所以实现类中不能重新定义,也不能改变其值。抽象类中的变量默认是 friendly 型,其值可以在子类中重新定义,也可以在子类中重新赋值。
49. 阅读Shape和Circle两个类的定义。在序列化一个Circle的对象circle到文件时,下面哪个字段会被保存到文件中? ( )
class Shape {
public String name;
}
class Circle extends Shape implements Serializable{
private float radius;
transient int color;
public static String type = "Circle";
}
Aname
B radius
C color
D type
答案:B
解析:Java transient详解
(1). transient的作用及使用方法
我们都知道一个对象只要实现了Serilizable接口,这个对象就可以被序列化,java的这种序列化模式为开发者提供了很多便利,我们可以不必关系具体序列化的过程,只要这个类实现了Serilizable接口,这个类的所有属性和方法都会自动序列化。
然而在实际开发过程中,我们常常会遇到这样的问题,这个类的有些属性需要序列化,而其他属性不需要被序列化,打个比方,如果一个用户有一些敏感信息(如密码,银行卡号等),为了安全起见,不希望在网络操作(主要涉及到序列化操作,本地序列化缓存也适用)中被传输,这些信息对应的变量就可以加上transient关键字。换句话说,这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
总之,java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
/**
* @description 使用transient关键字不序列化某个变量
* 注意读取的时候,读取数据的顺序一定要和存放数据的顺序保持一致
*
* @author Alexia
* @date 2013-10-15
*/
public class TransientTest {
public static void main(String[] args) {
User user = new User();
user.setUsername("Alexia");
user.setPasswd("123456");
System.out.println("read before Serializable: ");
System.out.println("username: " + user.getUsername());
System.err.println("password: " + user.getPasswd());
try {
ObjectOutputStream os = new ObjectOutputStream(
new FileOutputStream("C:/user.txt"));
os.writeObject(user); // 将User对象写进文件
os.flush();
os.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
ObjectInputStream is = new ObjectInputStream(new FileInputStream(
"C:/user.txt"));
user = (User) is.readObject(); // 从流中读取User的数据
is.close();
System.out.println("\nread after Serializable: ");
System.out.println("username: " + user.getUsername());
System.err.println("password: " + user.getPasswd());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class User implements Serializable {
private static final long serialVersionUID = 8294180014912103005L;
private String username;
private transient String passwd;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPasswd() {
return passwd;
}
public void setPasswd(String passwd) {
this.passwd = passwd;
}
}
输出为:
read before Serializable: username: Alexia password: 123456 read after Serializable: username: Alexia password: null密码字段为null,说明反序列化时根本没有从文件中获取到信息。
(2). transient使用小结
1)一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
2)transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
3)被transient关键字修饰的变量不再能被序列化,一个静态变量不管是否被transient修饰,均不能被序列化。
第三点可能有些人很迷惑,因为发现在User类中的username字段前加上transient关键字后,程序运行结果依然不变,即static类型的username也读出来为“Alexia”了,这不与第三点说的矛盾吗?实际上是这样的:第三点确实没错(一个静态变量不管是否被transient修饰,均不能被序列化),反序列化后类中static型变量username的值为当前JVM中对应static变量的值,这个值是JVM中的不是反序列化得出的,不相信?好吧,下面我来证明:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
/**
* @description 使用transient关键字不序列化某个变量
* 注意读取的时候,读取数据的顺序一定要和存放数据的顺序保持一致
*
* @author Alexia
* @date 2013-10-15
*/
public class TransientTest {
public static void main(String[] args) {
User user = new User();
user.setUsername("Alexia");
user.setPasswd("123456");
System.out.println("read before Serializable: ");
System.out.println("username: " + user.getUsername());
System.err.println("password: " + user.getPasswd());
try {
ObjectOutputStream os = new ObjectOutputStream(
new FileOutputStream("C:/user.txt"));
os.writeObject(user); // 将User对象写进文件
os.flush();
os.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
// 在反序列化之前改变username的值
User.username = "jmwang";
ObjectInputStream is = new ObjectInputStream(new FileInputStream(
"C:/user.txt"));
user = (User) is.readObject(); // 从流中读取User的数据
is.close();
System.out.println("\nread after Serializable: ");
System.out.println("username: " + user.getUsername());
System.err.println("password: " + user.getPasswd());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class User implements Serializable {
private static final long serialVersionUID = 8294180014912103005L;
public static String username;
private transient String passwd;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPasswd() {
return passwd;
}
public void setPasswd(String passwd) {
this.passwd = passwd;
}
}
输出为:
read before Serializable: username: Alexia password: 123456 read after Serializable: username: jmwang password: null这说明反序列化后类中static型变量username的值为当前JVM中对应static变量的值,为修改后jmwang,而不是序列化时的值Alexia。
(3). transient使用细节——被transient关键字修饰的变量真的不能被序列化吗?
思考下面的例子:
import java.io.Externalizable;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectInputStream;
import java.io.ObjectOutput;
import java.io.ObjectOutputStream;
/**
* @descripiton Externalizable接口的使用
*
* @author Alexia
* @date 2013-10-15
*
*/
public class ExternalizableTest implements Externalizable {
private transient String content = "是的,我将会被序列化,不管我是否被transient关键字修饰";
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(content);
}
@Override
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
content = (String) in.readObject();
}
public static void main(String[] args) throws Exception {
ExternalizableTest et = new ExternalizableTest();
ObjectOutput out = new ObjectOutputStream(new FileOutputStream(
new File("test")));
out.writeObject(et);
ObjectInput in = new ObjectInputStream(new FileInputStream(new File(
"test")));
et = (ExternalizableTest) in.readObject();
System.out.println(et.content);
out.close();
in.close();
}
}
content变量会被序列化吗?好吧,我把答案都输出来了,是的,运行结果就是:
是的,我将会被序列化,不管我是否被transient关键字修饰
这是为什么呢,不是说类的变量被transient关键字修饰以后将不能序列化了吗?
我们知道在Java中,对象的序列化可以通过实现两种接口来实现,若实现的是Serializable接口,则所有的序列化将会自动进行,若实现的是Externalizable接口,则没有任何东西可以自动序列化,需要在writeExternal方法中进行手工指定所要序列化的变量,这与是否被transient修饰无关。因此第二个例子输出的是变量content初始化的内容,而不是null。
50.下面是People和Child类的定义和构造方法,每个构造方法都输出编号。在执行new Child("mike")的时候都有哪些构造方法被顺序调用?请选择输出结果 ( )
class People {
String name;
public People() {
System.out.print(1);
}
public People(String name) {
System.out.print(2);
this.name = name;
}
}
class Child extends People {
People father;
public Child(String name) {
System.out.print(3);
this.name = name;
father = new People(name + ":F");
}
public Child() {
System.out.print(4);
}
}
A312 B 32 C 432 D 132
答案:D
解析:考察的又是父类与子类的构造函数调用次序。在Java中,子类的构造过程中必须调用其父类的构造函数,是因为有继承关系存在时,子类要把父类的内容继承下来。但如果父类有多个构造函数时,该如何选择调用呢?
第一个规则:子类的构造过程中,必须调用其父类的构造方法。一个类,如果我们不写构造方法,那么编译器会帮我们加上一个默认的构造方法(就是没有参数的构造方法),但是如果你自己写了构造方法,那么编译器就不会给你添加了,所以有时候当你new一个子类对象的时候,肯定调用了子类的构造方法,但是如果在子类构造方法中我们并没有显示的调用基类的构造方法,如:super(); 这样就会调用父类没有参数的构造方法。
第二个规则:如果子类的构造方法中既没有显示的调用基类构造方法,而基类中又没有无参的构造方法,则编译出错,所以,通常我们需要显示的:super(参数列表),来调用父类有参数的构造函数,此时无参的构造函数就不会被调用。
总之,一句话:子类没有显示调用父类构造函数,不管子类构造函数是否带参数都默认调用父类无参的构造函数,若父类没有则编译出错。
最后,给大家出个思考题:下面程序的运行结果是什么?public class Dervied extends Base {
private String name = "dervied";
public Dervied() {
tellName();
printName();
}
public void tellName() {
System.out.println("Dervied tell name: " + name);
}
public void printName() {
System.out.println("Dervied print name: " + name);
}
public static void main(String[] args){
new Dervied();
}
}
class Base {
private String name = "base";
public Base() {
tellName();
printName();
}
public void tellName() {
System.out.println("Base tell name: " + name);
}
public void printName() {
System.out.println("Base print name: " + name);
}
}
运行结果为:
Dervied tell name: null
Dervied print name: null
Dervied tell name: dervied
Dervied print name: dervied