Storage Performance Virtualization via Throughput and Latency Control
Authors:
Jianyong Zhang, Anand Sivasubramaniam, Qian Wang
From:
ACM Transactions on Storage, Vol.2, No.3, August 2006, Pages 283-308
Abstract:
I/O consolidation is a growing trend in production environments due to increasing complexity in tuning and managing storage systems. A consequence of this trend is the need to serve multiple users and/or workloads simultaneously. It is imperative to ensure that these users are insulated from each other by virtualization in order to meet any service-level objective (SLO). Previous proposals for performance virtualization suffer from one or more of the following drawbacks: (1) They rely on a fairly detailed performance model of the underlying storage system; (2) couple rate and latency allocation in a single scheduler, making them less flexible; or (3) may not always exploit the full bandwidth offered by the storage system.
This article presents a two-level scheduling framework that can be built on top of an existing storage utility. This framework uses a low-level feedback-driven request scheduler, called AVATAR, that is intended to meet the latency bounds determined by the SLO. The load imposed on AVATAR is regulated by a high-level rate controller, called SARC, to insulate the users from each other. In addition, SARC is work-conserving and tries to fairly distribute any spare bandwidth in the storage system to the different users. This framework naturally decouples rate and latency allocation. Using extensive I/O traces and a detailed storage simulator, we demonstrate that this two-level framework can simultaneously meet the latency and throughput requirements imposed by an SLO, without requiring extensive knowledge of the underlying storage system.
More details:
The main goal of performance virtualization is to meet the throughput and latency requirements (and perhaps fairness issues) of different users and/or classes. And earlier solutions can be placed in two categories:
(1) Schemes in the first category use a proportional bandwidth sharing paradigm. These schemes are advantageous both in that they provide, at least in theory, a strong degree of fairness (as in GPS), and are work-conserving (i.e., they do not let the resource remain idle when there are requests waiting in some class). However, on the downside, there are problems that make them less attractive in a practical setting. First, they need a performance model to estimate the service time of an individual I/O request. Second, these schemes couple rate and latency allocation together, making them less flexible and potentially leading to resource over-provisioning.
(2) Schemes in the second category use feedback-based control to avoid the need for an accurate performance model. Within this category, schemes fall into two classes:
—The first class is composed of schemes that perform only rate control. These schemes can provide performance isolation and have good scalability. However, they suffer from several drawbacks. First, latency guarantees are not necessarily the intended goals, making it difficult to bound response times. Second, they are not fully work-conserving. These schemes may not always be able to exploit the full parallelism and/or bandwidth offered by the underlying storage utility. Finally, when spare bandwidth in the underlying storage utility is observed, these schemes may not be very fair in distributing this spareness to different classes.
—The second class is comprised of schemes that directly deal with the latency guarantee problem. As we show later in the article, even though this scheme is simple to implement, it cannot easily isolate performance, and is not fast enough in adapting to transient workload changes.
Architecture Principles
Aiming to provide both throughput and latency guarantees, we opt for a two-level architecture separating rate and latency allocation, rather than integrating everything into a single entity. The higher level of our architecture regulates traffic via a rate controller, called SARC. The lower level provides performance guarantees via a feedback-based controller, called AVATAR. The architecture of our framework is depicted in Figure 2.
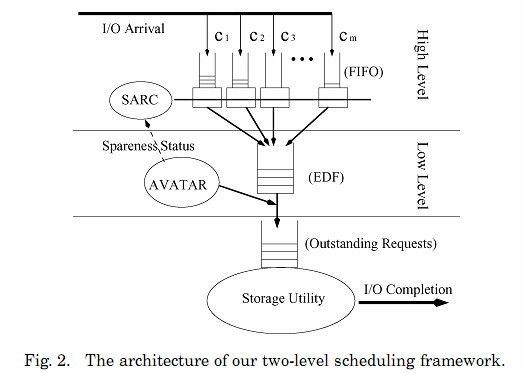
The high-level rate controller, SARC, is mainly responsible for regulating incoming traffic to meet the rate requirements and ensuring isolation between classes. SARC aims to fully utilize the underlying storage bandwidth by distributing fairly between all classes any spare bandwidth that is available. SARC manages the incoming traffic in class-based FIFO queues. A credit amount is assigned to each FIFO queue, indicating how many outstanding requests can be dispatched to the lower level.
The low-level controller, AVATAR, is mainly responsible for satisfying performance guarantees and ensuring effective usage of the storage utility. To meet latency requirements, we use a real-time scheduler, namely, an EDF queue, which orders all incoming requests based on their deadlines. However, merely employing an EDF scheduler may reduce overall throughput because this queue does not optimize the operation of the storage utility. For example, if the utility is a single disk, we prefer a seek or position-based optimization scheme [Worthington et al. 1994], as opposed to EDF. Nevertheless, it is important to strike a good balance between optimizing for latency and optimizing for throughput. AVATAR uses feedback control to dynamically regulate the number of requests dispatched from the EDF queue to the storage utility, where they may get reordered for better efficiency. Note that dispatching a large number of requests to the storage utility optimizes the system for efficiency and throughput, while restricting the number of requests at the storage utility gives more priority to deadlines.
Concluding
Instead of requiring a detailed performance model, the low-level scheduler of our framework—AVATAR—uses feedback to control the relative importance of deadline-versus throughput-based request scheduling for fast adaptation to transient conditions. We have experimentally demonstrated that it can provide better adaptability to the most closely related feedback controller (Facade) hitherto proposed, in terms of meeting latency constraints. In addition, the high-level rate controller, SARC, is not only able to isolate classes from each other, but can also fairly distribute any spare bandwidth to these classes so as to provide better aggregate throughput.
Note that SARC and AVATAR algorithms are not time-consuming, and in fact, most of the code is not in the critical path of I/O processing. Only insertion in the EDF queue is, to some extent, in the critical path, and its cost would be O(lg m) if there are m classes. One possible concern that the reader may have is that the decision making in our framework is somewhat centralized, which can make it less scalable. However, we believe that performance virtualization of a large scale storage system needs hierarchical schemes, and in our ongoing work we are investigating how this two-level framework can be used as a basic building block for a more decentralized hierarchical solution.