Latex中使用dvipdfm转换方式hyperref包生成PDF中文书签乱码的解决方案
Latex 中使用 dvipdfm 转换方式 hyperref 包生成 PDF 中文书签乱码的解决方案
【下载】
gbk2uni
TeX 生成 pdf 文件时中文书签经常出现乱码 , 网上讨论颇多 , 解决方法之一是用 gbk2uni 把 .out 文件中的 GBK 编码转化为 Unicode 编码后再编译一遍。这个 gbk2uni 是 cxterm 、张林波和 HookLee 共同开发的 , 点击 这里 下载 , 解压后可以把 gbk2uni.exe 拷入 path 所在路径 , 比如 MiKTeX 的安装目录 texmf/miktex/bin 下。
使用方法如下:
Linux 命令行编译顺序如下:
$ latex main.tex
$ bibtex main.tex
$ latex main.tex
$ gbk2uni main.out
$ latex main.tex
$ dvipdfm main.dvi
DOS 用批处理编译的话与些相似 ( 省略了扩展名 ) :
latex main
bibtex main
latex main
gbk2uni main
latex main
dvipdfmx main
参考链接 :
1. http://www.hooklee.com/tex.html
2. http://www.ctex.org
gbk2uni 的问题
关键的问题就是如果文档不是 GBK 编码的,比如用的最多的 UTF-8 或其他编码,这种方式就会失效,因为 gbk2uni 依然按照 GBK 字符去转换,为了和国际接轨( ^^ ),建议统一使用 UTF-8 进行 latex 文档的编写,为了正常生成 PDF 标签,我使用 java 做了一个工具可以辅助生成。此工具支持所有编码类型的转换。
解决方案 LatexHyperrefCharsetTool
实例文档
| % @charset: UTF-8 % 可用字体 song fs hei kai li you %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % 导言区 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% /documentclass[9pt,b5paper]{article} /usepackage{CJKutf8}
% 导言区使用中文,必须引入一个 CJK 环境 /begin{CJK*}{UTF8}{song} /end{CJK*}
/usepackage{indentfirst} /setlength{/parindent}{2em}% 中文缩进两个汉字位 /renewcommand{/baselinestretch}{1.2}% 行距
/usepackage[dvipdfm,% 需要使用 dvipdfm 或 dvipdfmx 进行 pdf 生成 pdfstartview=FitH, CJKbookmarks=true, %unicode=true,% 不要让 latex 自动转换 unicode 字符会出现各种问题 bookmarksnumbered=true, bookmarksopen=true, colorlinks=true, % 注释掉此项则交叉引用为彩色边框 ( 将 colorlinks 和 pdfborder 同时注释掉 ) %pdfborder=001, % 注释掉此项则交叉引用为彩色边框 citecolor=magenta,% magenta , cyan linkcolor=blue, linktocpage=true, ]{hyperref} % hyperref 宏包通常要求放在导言区的最后 !!!
/renewcommand/contentsname{/hfil{} 目 ~~~~~ 录 }% 目录文字
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % 正文 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% /begin{document} /begin{CJK*}{UTF8}{song}
/tableofcontents% 目录
/section{ 中华人民共和国 }
这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。
/subsection{ モバイル }
`` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。
这是中文。 `` 哈哈 '' 。
TeXworks 是在 TUG ( TeX Users Group )的支持下正在开发的一个全新的 TeX/LaTeX 编辑器。它的首要特点如下:自带了一个 pdf 浏览器,编辑 latex 文件时可以迅速预览排版后的 pdf 文件;默认情况下 latex 编辑窗口在左边, pdf 浏览窗口在右边,各占一半桌面,在大屏幕宽屏显示器显示的效果最好不过了。还有就是它的设计目标是简单易用,所以只支持直接生成并预览 pdf ,避免 dvi, ps, pdf 各种文件格式对初学者的干扰。
All packages using GNU Automake to produce distribution tarballs with make dist should update to the 1.11.1 or 1.10.3 release, or otherwise work around the problem.
/section{ 日本語のページを検索 } /subsection{ 亴壪惸蠪衋 } /subsection{Цкюёя} /subsection{Recherche avancée d'entreprise}
/section{België} /section{Ελλάδα}
这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是
% 解决 bug 创建新页 /newpage{} /end{CJK*} /end{document} |
注意此文档必须使用 UTF-8 编码
1 检查您机器上的 java 环境是否正确 ( 需求 :JRE/JRE 1.5+ 下载 ) 。
2 将 Charset2Unicode.class 文件放入与此文件相同的目录下。
3 执行编译 ( 建议编写批处理文件 ) 。
批处理文件实例
| latex t_UTF-8 java -classpath . Charset2Unicode UTF-8 t_UTF-8.out latex t_UTF-8 dvipdfmx t_UTF-8 |
t_UTF-8 是文件名(省略后缀)
编译结果 ( 运行 t_UTF-8.pdf)
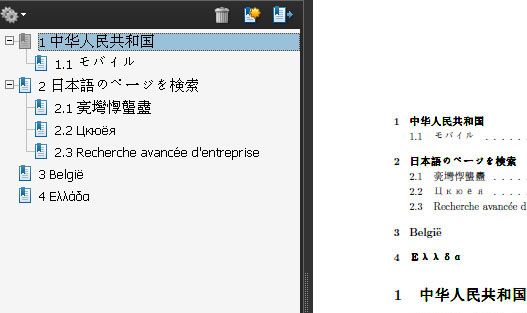
可见 PDF 一切正常。
附 1 GBK tex 文件实例及编译脚本
| % @charset: GBK % 可用字体 song fs hei kai li you %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % 导言区 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% /documentclass[9pt,b5paper]{article} /usepackage{CJK}
% 导言区使用中文,必须引入一个 CJK 环境 /begin{CJK*}{GBK}{song} /end{CJK*}
/usepackage{indentfirst} /setlength{/parindent}{2em}% 中文缩进两个汉字位 /renewcommand{/baselinestretch}{1.2}% 行距
/usepackage[dvipdfm,% 需要使用 dvipdfm 或 dvipdfmx 进行 pdf 生成 pdfstartview=FitH, CJKbookmarks=true, %unicode=true,% 不要让 latex 自动转换 unicode 会出现各种问题 bookmarksnumbered=true, bookmarksopen=true, colorlinks=true, % 注释掉此项则交叉引用为彩色边框 ( 将 colorlinks 和 pdfborder 同时注释掉 ) %pdfborder=001, % 注释掉此项则交叉引用为彩色边框 citecolor=magenta,% magenta , cyan linkcolor=blue, linktocpage=true, ]{hyperref} % hyperref 宏包通常要求放在导言区的最后 !!!
/renewcommand/contentsname{/hfil{} 目 ~~~~~ 录 }% 目录文字
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % 正文 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% /begin{document} /begin{CJK*}{GBK}{song}
/tableofcontents% 目录
/section{ 中华 /{ 哈 /} 人民共和国 } /subsection{1} /section{ 二 } /subsection{1} /subsubsection{1}
这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。
这是中文。 `` 哈哈 '' 。
TeXworks 是在 TUG ( TeX Users Group )的支持下正在开发的一个全新的 TeX/LaTeX 编辑器。它的首要特点如下:自带了一个 pdf 浏览器,编辑 latex 文件时可以迅速预览排版后的 pdf 文件;默认情况下 latex 编辑窗口在左边, pdf 浏览窗口在右边,各占一半桌面,在大屏幕宽屏显示器显示的效果最好不过了。还有就是它的设计目标是简单易用,所以只支持直接生成并预览 pdf ,避免 dvi, ps, pdf 各种文件格式对初学者的干扰。
All packages using GNU Automake to produce distribution tarballs with make dist should update to the 1.11.1 or 1.10.3 release, or otherwise work around the problem.
/section{ 嘿嘿 }
这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。这是中文。 `` 哈哈 '' 。
% 解决 bug 创建新页 /newpage{} /end{CJK*} /end{document} |
脚本
| latex gbk_1 java -classpath . Charset2Unicode GBK gbk_1.out latex gbk_1 dvipdfmx gbk_1 |
附 2 Charset2Unicode 源代码
import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.io.PrintWriter; import java.nio.charset.Charset; import java.util.Map; import java.util.SortedMap; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * @author 杨帆 [email protected] */ public class Charset2Unicode { public static void main(String[] args) throws IOException { if (args.length != 2) { System.out.println("usage: Charset2Unicode {charset} filename"); System.out.println("Available Charsets:"); SortedMap<String, Charset> availableCharsets = Charset .availableCharsets(); for (Map.Entry<String, Charset> entry : availableCharsets .entrySet()) { System.out.println(entry.getKey()); } } else { // 处理文件 File srcFile = new File(args[1]); // 文件不存在 if (!srcFile.exists()) { System.out.println(args[1] + " not exists!"); System.exit(-1); } // 清除备份文件 try { new File(args[1] + ".bak").delete(); } catch (Exception e) { } // 改名为备份文件 srcFile.renameTo(new File(args[1] + ".bak")); // 操作文件 srcFile = new File(args[1] + ".bak"); // 生成新文件 File desFile = new File(args[1]); // 输出流 PrintWriter writer = new PrintWriter(desFile, "UTF-8"); // 读取字符流 BufferedReader reader = new BufferedReader(new InputStreamReader( new FileInputStream(srcFile), args[0])); String line; Pattern pattern = Pattern .compile("^([^//{]*//{[^//}]*//}//{)([^//}]*)(//}.*)$"); while ((line = reader.readLine()) != null) { // System.out.println(line); StringBuffer sb = new StringBuffer(); // 分解字符串 Matcher matcher = pattern.matcher(line); if (matcher.find()) { // 匹配 for (int i = 1; i <= matcher.groupCount(); i++) { if (i == 2) { // 固定格式 sb.append("//376//377"); // 将字符转换为八进制UTF16-BE String srcStr = matcher.group(i); for (int j = 0; j < srcStr.length(); j++) { char c = srcStr.charAt(j); if (c == '//') { // /ddd此种格式原样输出, 应该在之前增加/000(需要测试) sb.append("//000" + c + srcStr.charAt(j + 1) + srcStr.charAt(j + 2) + srcStr.charAt(j + 3)); j = j + 3; } else { // 字符转换 byte[] b = new String(c + "") .getBytes("UTF-16BE"); for (int k = 0; k < b.length; k++) { sb.append(Byte2OctString(b[k])); } } } } else { sb.append(matcher.group(i)); } } } else { // 不匹配不操作 } // 写入目标文件 System.out.println("log:" + sb.toString()); writer.println(sb.toString()); } reader.close(); writer.flush(); writer.close(); } } public static synchronized String Byte2OctString(byte b) { // 修正负数为无符号数 String s = (b < 0 ? Integer.toString(b + 256, 8) : Integer.toString(b, 8)); StringBuffer sb = new StringBuffer(); sb.append("//"); for (int i = 0; i < 3 - s.length(); i++) { sb.append("0"); } sb.append(s); return sb.toString(); } }
【下载】
祝使用愉快,如果有什么建议,请给我发邮件 yifi(a)tom.com.