算法学习笔记----归并排序
一、算法描述
归并排序算法完全遵循分治模式,将问题分解为若干子问题,如果子问题的规模足够小,则直接求解,否则递归地求解各子问题。算法步骤如下所示:
1)将待排序的n个元素的序列分解为各具n/2个序列的两个字序列
2)使用归并排序递归地将两个子序列排序
3)将两个已排序的子序列合并,生成排好序的序列。
二、算法实现
1、递归版本
为了避免在合并两个子序列时每次都要检查是否某个子序列已全部处理完,在每个子序列最后都添加了一个“哨兵”元素。源码如下所示:
#include <stdio.h>
#include <errno.h>
#ifndef INT_MAX
#define INT_MAX ((int)(~0U>>1))
#endif
#define ARRAY_SIZE(__s) (sizeof(__s) / sizeof(__s[0]))
static void merge(int *a, int start, int mid, int end)
{
int nl = mid - start + 1;
int nr = end - mid;
int sentinel = INT_MAX;
int left[nl + 1], right[nr + 1];
int i, j, k = start;
for (i = 0; i < nl; ++i) {
left[i] = a[k++];
}
/* Set sentinel */
left[i] = sentinel;
for (j = 0; j < nr; ++j) {
right[j] = a[k++];
}
/* Set sentinel */
right[j] = sentinel;
i = j = 0;
for (k = start; k <= end; ++k) {
if (left[i] <= right[j]) {
a[k] = left[i++];
} else {
a[k] = right[j++];
}
}
}
static void merge_sort(int *a, int start, int end)
{
int mid;
if ((start >= 0) && (start < end)) {
mid = (start + end) /2 ;
merge_sort(a, start, mid);
merge_sort(a, mid + 1, end);
merge(a, start, mid, end);
}
}
int main(void)
{
int source[] = { 7, 5, 2, 4, 6, 1, 5, 3};
int i;
printf("Before sort: ");
for (i = 0; i < ARRAY_SIZE(source); ++i) {
printf("%d ", source[i]);
}
printf("\n");
merge_sort(source, 0, ARRAY_SIZE(source) - 1);
printf("After sort: ");
for (i = 0; i < ARRAY_SIZE(source); ++i) {
printf("%d ", source[i]);
}
printf("\n");
return 0;
} 2、迭代版本
这个版本是在维基百科上看到的, 做一个简单的分析,记录一下,代码如下所示:
#include <stdio.h>
#include <errno.h>
#define ARRAY_SIZE(__s) (sizeof(__s) / sizeof(__s[0]))
void merge_sort_iterate(int *source, int n)
{
int i, left_min, right_min, left_max, right_max, next;
int tmp[n];
for (i = 1; i < n; i *= 2) {
/*
* 将数组分段处理,每个段的长度为2*i。其中每段的前一半作为左半部,
* 后一半作为右半部,然后合并。
*/
for (left_min = 0; left_min < n - 1; left_min = right_max) {
/*
* left_max其实是左半部的长度,right_max其实是右半部的长度,
* 所以应该叫left_len、righ_len更合适一些。
*/
right_min = left_max = left_min + i;
right_max = left_max + i;
if (right_max > n) {
right_max = n;
}
next = 0;
/*
* 合并当前段中左半部和右半部的元素
*/
while ((left_min < left_max) &&
(right_min < right_max)) {
tmp[next++] = source[left_min] > source[right_min] ?
source[right_min++] : source[left_min++];
}
/*
* 左半部和右半部从长度为1开始处理,每次处理后,左半部和右半部
* 组成的段是排好序的,所以在下次处理中,每个段的左半部和右半部
* 已经是排好序的。如果判断条件为真,说明右半部中当前元素已经全
* 部放在tmp中,而左半部中剩余的元素肯定比已经放在tmp中的元素大,
* 因此循环将左半部中剩余的元素放在段的后面。
*/
while (left_min < left_max) {
source[--right_min] = source[--left_max];
}
/*
* 将tmp中已经排好序的元素放回到原数组中,此时source数组中的元素不是
* 并不是已经排好序了,只是段中已经排好序。
*/
while (next > 0) {
source[--right_min] = tmp[--next];
}
}
}
}
int main(void)
{
int source[] = { 7, 5, 2, 4, 6, 1, 5, 3};
int i;
printf("Before sort: ");
for (i = 0; i < ARRAY_SIZE(source); ++i) {
printf("%d ", source[i]);
}
printf("\n");
merge_sort_iterate(source, ARRAY_SIZE(source));
printf("After sort: ");
for (i = 0; i < ARRAY_SIZE(source); ++i) {
printf("%d ", source[i]);
}
printf("\n");
return 0;
}
其处理过程如下图所示(阴影部分为代码注释中提到的当前正在处理的段):
3、空间复杂度O(1)版本
这个是在搜索的时候看到的一个题目,就是在合并两个已经排好序的子序列后时,不分配临时存储左右子序列的空间,而是使用类似插入排序的方法,将右子序列的元素插入到左子序列中。虽然这种方法节省了空间,但是时间复杂度由nlg(n)变为(n^2)lgn,牺牲了性能。代码实现如下:
#include <stdio.h>
#include <errno.h>
#ifndef INT_MAX
#define INT_MAX ((int)(~0U>>1))
#endif
#define ARRAY_SIZE(__s) (sizeof(__s) / sizeof(__s[0]))
static void merge(int *a, int start, int mid, int end)
{
int i, left, right;
int key;
for (right = mid + 1; right <= end; ++right) {
left = right - 1;
key = a[right];
while (a[left] > key) {
a[left + 1] = a[left];
--left;
}
a[left + 1] = key;
}
}
static void merge_sort(int *a, int start, int end)
{
int mid;
if ((start >= 0) && (start < end)) {
mid = (start + end) /2 ;
merge_sort(a, start, mid);
merge_sort(a, mid + 1, end);
merge(a, start, mid, end);
}
}
int main(void)
{
int source[] = { 7, 5, 2, 4, 6, 1, 5, 3};
int i;
printf("Before sort: ");
for (i = 0; i < ARRAY_SIZE(source); ++i) {
printf("%d ", source[i]);
}
printf("\n");
merge_sort(source, 0, ARRAY_SIZE(source) - 1);
printf("After sort: ");
for (i = 0; i < ARRAY_SIZE(source); ++i) {
printf("%d ", source[i]);
}
printf("\n");
return 0;
}
三、算法分析
当输入的序列只有一个元素时,归并排序需要常量时间。假设当有n个元素时,使用归并排序算法来排序需要的时间为T(n)。当有n>1个元素时,按如下方式来分解时间:
1)分解,分解步骤仅仅是计算子数组的中间位置,需要常量时间,记作D(n),D(n)=Θ(1)。
2)解决,递归地求解两个规模均为n/2的子序列的排序问题,运行时间为2T(n/2)。
3)合并,将两个规模为n/2的子序列合并到规模为n的序列中需要的的时间记作C(n), C(n)=Θ(n)。
根据上面的的分析,可以得到归并排序的运行时间公式,如下所示:
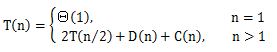
D(n)和C(n)相加时,相当于是把一个Θ(1)函数与另一个Θ(n)函数相加,相加的和是n的一个线性函数,即Θ(n)。因此我们将T(n)的计算公式转换为下面的形式:
![]()
为了更直观地理解T(n)的递归式,以及后面分析这个运行时间的分解,继续重写T(n)递归式。假设c为求解规模为1的为所需的时间以及在分解步骤和合并步骤处理每个数组元素所需的时间,将T(n)的递归式重写为下面的形式:
![]()
相同常量一般不可能刚好既代表求解规模为1的问题的运行时间,又代表在分解步骤和合并步骤处理每个数组元素的时间,但是这两个时间肯定都是一个常量,为了后续的分析,做这样的假设不会影响最终的结果。
为方便起见,假设n刚好是2的幂,将T(n)递归式用下面的树来表示:
树中各个节点的值相加得到T(n)的值,其中cn为分解序列和合并序列所需的时间,T(n/2)为解决子序列排序问题所需的时间。将规模为n/2的子序列的问题进一步分解,得到下面的等价树:
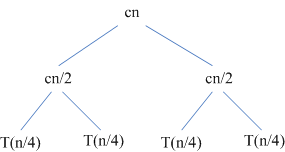
在第二层的递归中,两个子结点中每个引起的代价都是cn/2,但是此时子问题的规模还是没有不够小,也就是不能直接求解,所以还需要进一步的分解,直到问题规模下降到1,这时每个子问题的代价就很容易计算出来,其代价为c,如下图所示:

下面具体分析下层数的计算和每层所需的代价的计算。
第一层只有一个节点,规模为n;第二层每个节点的规模为n/2,第三层每个节点的规模为n/4,以此类推直到节点的规模为1.假设k为层数,每层节点的规模为S(k),则得到下面的计算公式:
问题的规模为1时,k的值为lgn+1,也就是上图中分解得到的树的层数。
现在需要确定分解和组合每层节点所需要的代价。总的问题规模为n,在分解问题时每层的节点的规模为n/2^(k-1),其中k为层数,每层各节点的问题规模相加得到的总规模仍为n,因此每层的节点个数为2^(k-1),将每个节点所需的代价乘以节点个数,即得到每层所需要的代码,如下所示:
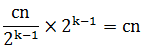
为了计算T(n)递归式表示的总代价,只要把各层的代价加起来,递归树有lgn+1层,每层的代价为均为cn,所以总的代价为cn(lgn+1)=cnlgn+cn。忽略低阶项和常量c,得到时间复杂度为Θ(nlgn)。从上面的分析可以看出,归并排序是一种稳定的排序算法,最坏、最好情况下时间复杂度均为Θ(nlgn),平均时间复杂度也为Θ(nlgn)。
归并排序的空间复杂度为Θ(n)。这个空间复杂度有些疑问,网上看到这样的解释“由于归并排序在归并过程中需要与原始记录序列同样数量的存储空间存放归并结果以及递归时深度为log2n的栈空间,因此空间复杂度为O(n+logn)”,但是感觉这个解释说不通。我是这样理解的,递归就是要高度抽象,在递归式中对左半部和右半部分别排序看作一个过程,真正要考虑的空间是在对左半部和右半部排序之后合并时需要的空间,因此空间复杂度为Θ(n)。这个理解很是牵强,,,,,