浅解Unicode与UTF-8
Unicode和UCS
在上世纪80年代,世界上出现了两个独立的组织尝试创建单一字符集:
- ISO(国际标准化组织)于1984年成立了ISO/IEC JTC1/SC2,制定了ISO 10646标准,其标准中定义的字符集便是UCS(Universal Character Set)。
- Xerox、Apple等软件制造商于1988年组成The Unicode Consortium(Unicode联盟),这是一个统筹Unicode发展的组织,当然Unicode字符集也是出自这个组织。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。1991年,不包含CJK统一汉字集的Unicode 1.0发布。随后,CJK统一汉字集的制定于1993年完成,发布了ISO 10646-1:1993,即Unicode 1.1。
从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都独立存在,并独立地公布各自的标准。但Unicode联盟和ISO/IEC JTC1/SC2都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。
接下来介绍一下UCS:
UCS有两种格式:UCS-2和UCS-4。顾名思义,UCS-2就是用两个字节编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)编码。
其中 UCS-2有2^16=65536个码位,UCS-4有2^31=2147483648个码位(大到绝对可以涵盖一切语言使用的符号,估计外星文字也可以包括^_^)。
UCS-4根据最高位为0的最高字节分成2^7=128个group。每个group再根据次高字节分为256个plane。每个plane根据第3个字节分为256行 (rows),每行包含256个cells。其中group-0的plane-0被称作Basic Multilingual Plane(即BMP),所以UCS-4中,高两个字节为0的码位被称作BMP。
将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。在UCS-2的两个字节前加上两个零字节,就得到了UCS-4的BMP,换句话说UCS-2中的字符构成了BMP。而目前的UCS-4规范中还没有任何字符被分配在BMP之外。
至于为什么介绍UCS,是因为Unicode的编码方式与ISO 10646的UCS概念相对应。目前实际应用的Unicode版本对应于UCS-2,使用16位的编码空间。最新(但未实际广泛使用)的Unicode版本定义了16个辅助平面,与BMP合起来至少需要占据21位的编码空间,比3字节略少,事实上辅助平面字符仍然占用4字节编码空间,仍然与UCS-4保持一致。(该段文字中的“目前”、“最新”均直接取自维基百科解释)
说到现在,上面出现这么一堆名称可能让人有些混乱,其实UCS和Unicode之间的关系可以简单用一句话总结:IOS 10646标准的字符集UCS和Unicode字符集,是具有相同目的(创建一个可以涵盖一切文字符号的字符集)的,并且紧密保持一致的(可以简单理解为编码相同)。
在介绍UTF-8之前,需要分清两个概念:
- 编码方式:Unicode字符集便是编码方式,它定义一个字符与其对应的编码。
- 实现方式:如果按照Unicode字符集规定的那样一个字符对应2个字节,那么对于ACSII中的字符,每个字符只会用到后一个字节,前一个字节便会被浪费掉,所以Unicode在具体实现中有着不同的实现方式,即UTF(Unicode Transformation Format,中文Unicode转换格式)。
UTF-8
这里只介绍UTF-8,至于UTF-7、UTF-16、UTF-32等不做介绍,如有需要可以参考文后链接(实际上就是维基百科啦)。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。UTF-8是当前互联网与计算机上可以说是使用最广的编码。
下面来看一下UTF-8是如何实现Unicode编码的(图片截取自维基百科):
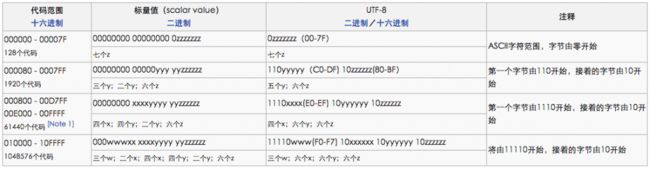
看完这个表格,可能有人会发现D800-DFFF这个范围怎么不见了,这是因为:Unicode在范围D800-DFFF中不存在任何字符,BMP中约定了这个范围用于UTF-16扩展标识辅助平面(两个UTF-16表示一个辅助平面字符)。当然,任何编码都是可以被转换到这个范围,但在unicode中他们并不代表任何合法的值。(知道就行了,如果想深入,自行维基百科亲~)
这时可以总结一下UTF-8编码是如何实现Unicode的了:
- 对于ASCII中的字符,UTF-8采用一个首位为0的字节实现2^7=128个ASCII字符
- UTF-8编码中首字节前几位为n个1和一个0(如 110x xxxx),表示该字符由n个字节构成(UTF-8编码后的字节数)
- UTF-8编码中非首字节的格式是固定的,即 10xx xxxx
- 将上两条中提到的那些位拿掉,剩下的便是对应的Unicode编码
带BOM的UTF-8
BOM全称Byte Order Mark,中文意思是字节序标记,它是一个两字节的编码(FEFF)。主要作用是用于在字节流传输时指定字节序(Big-Endian或Little-Endian),Unicode标准允许在UTF-8编码文件头部添加BOM。
实际上,由于UTF-8以字节为编码单元,它的字节序在所有系统中都是一样的,所以不会存在字节序问题。在类Unix上是不建议采用这种方法的。那么究竟有谁在用呢?答:微软(微软手拉着IE表示:哥就是这么特立独行)。
之所以微软在 UTF-8 中使用 BOM,是因为这样可以把 UTF-8 和 ASCII 等编码明确区分开,但这样的文件在 Windows 之外的操作系统里会带来问题(例如gcc、php)。
参考资料:
- 维基百科 Unicode
- 维基百科 通用字符集
- 维基百科 UTF-8
- 维基百科 字节顺序标记BOM
- 知乎问答
- CSDN博客