搜索引擎蜘蛛算法与蜘蛛程序构架
一、
网络蜘蛛基本原理
网络蜘蛛即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
对于搜索引擎来说,要抓取互联网上所有的网页几乎是不可能的,从目前公布的数据来看,容量最大的搜索引擎也不过是抓取了整个网页数量的百分之四十左右。这其中的原因一方面是抓取技术的瓶颈,薹ū槔械耐常行矶嗤澄薹ù悠渌车牧唇又姓业剑涣硪桓鲈蚴谴娲⒓际鹾痛砑际醯奈侍猓绻凑彰扛鲆趁娴钠骄笮∥0K计算(包含图片),100亿网页的容量是100×2000G字节,即使能够存储,下载也存在问题(按照一台机器每秒下载20K计算,需要340台机器不停的下载一年时间,才能把所有网页下载完毕)。同时,由于数据量太大,在提供搜索时也会有效率方面的影响。因此,许多搜索引擎的网络蜘蛛只是抓取那些重要的网页,而在抓取的时候评价重要性主要的依据是某个网页的链接深度。
在抓取网页的时候,网络蜘蛛一般有两种策略:广度优先和深度优先(如下图所示)。广度优先是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。这是最常用的方式,因为这个方法可以让网络蜘蛛并行处理,提高其抓取速度。深度优先是指网络蜘蛛会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。这个方法有个优点是网络蜘蛛在设计的时候比较容易。两种策略的区别,下图的说明会更加明确。
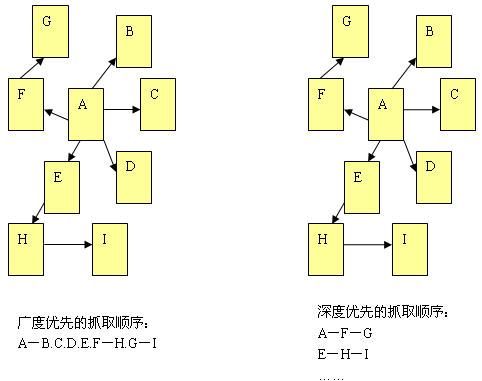
由于不可能抓取所有的网页,有些网络蜘蛛对一些不太重要的网站,设置了访问的层数。例如,在上图中,A为起始网页,属于0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。如果网络蜘蛛设置的访问层数为2的话,网页I是不会被访问到的。这也让有些网站上一部分网页能够在搜索引擎上搜索到,另外一部分不能被搜索到。对于网站设计者来说,扁平化的网站结构设计有助于搜索引擎抓取其更多的网页。
网络蜘蛛在访问网站网页的时候,经常会遇到加密数据和网页权限的问题,有些网页是需要会员权限才能访问。当然,网站的所有者可以通过协议让网络蜘蛛不去抓取,但对于一些出售报告的网站,他们希望搜索引擎能搜索到他们的报告,但又不能完全免费的让搜索者查看,这样就需要给网络蜘蛛提供相应的用户名和密码。网络蜘蛛可以通过所给的权限对这些网页进行网页抓取,从而提供搜索。而当搜索者点击查看该网页的时候,同样需要搜索者提供相应的权限验证。
二、
网站与网络蜘蛛
网络蜘蛛需要抓取网页,不同于一般的访问,如果控制不好,则会引起网站服务器负担过重。每个网络蜘蛛都有自己的名字,在抓取网页的时候,都会向网站标明自己的身份。网络蜘蛛在抓取网页的时候会发送一个请求,这个请求中就有一个字段为User-agent,用于标识此网络蜘蛛的身份。例如Google网络蜘蛛的标识为GoogleBot,Baidu网络蜘蛛的标识为BaiDuSpider,Yahoo网络蜘蛛的标识为Inktomi Slurp。如果在网站上有访问日志记录,网站管理员就能知道,哪些搜索引擎的网络蜘蛛过来过,什么时候过来的,以及读了多少数据等等。如果网站管理员发现某个蜘蛛有问题,就通过其标识来和其所有者联系。
网络蜘蛛进入一个网站,一般会访问一个特殊的文本文件Robots.txt,这个文件一般放在痉衿鞯母柯枷拢竟芾碓笨梢酝ü齬obots.txt来定义哪些目录网络蜘蛛不能访问,或者哪些目录对于某些特定的网络蜘蛛不能访问。例如有些网站的可执行文件目录和临时文件目录不希望被搜索引擎搜索到,那么网站管理员就可以把这些目录定义为拒绝访问目录。Robots.txt语法很简单,例如如果对目录没有任何限制,可以用以下两行来描述:
User-agent: *
Disallow:
当然,Robots.txt只是一个协议,如果网络蜘蛛的设计者不遵循这个协议,网站管理员也无法阻止网络蜘蛛对于某些页面的访问,但一般的网络蜘蛛都会遵循这些协议,而且网站管理员还可以通过其它方式来拒绝网络蜘蛛对某些网页的抓取。
网络蜘蛛在下载网页的时候,会去识别网页的HTML代码,在其代码的部分,会有META标识。通过这些标识,可以告诉网络蜘蛛本网页是否需要被抓取,还可以告诉网络蜘蛛本网页中的链接是否需要被继续跟踪。例如: 表示本网页不需要被抓取,但是网页内的链接需要被跟踪。
关于Robots.txt的语法和META Tag语法,前面的一篇“ 禁止搜索引擎收录的方法”一文中做了详细的介绍。
现在一般的网站都希望搜索引擎能更全面的抓取自己网站的网页,因为这样可以让更多的访问者能通过搜索引擎找到此网站。为了让本网站的网页更全面被抓取到,网站管理员可以建立一个网站地图,即Site Map。许多网络蜘蛛会把sitemap.htm文件作为一个网站网页爬取的入口,网站管理员可以把网站内部所有网页的链接放在这个文件里面,那么网络蜘蛛可以很方便的把整个网站抓取下来,避免遗漏某些网页,也会减小对网站服务器的负担。(Google专门为网站管理员提供了XML的Sitemap)
三、网络蜘蛛对内容提取
set Inet1 = CreateObject("InetCtls.Inet")
Inet1.protocol = 4 'HTTP
Inet1.accesstype = 1 'Direct connection to internet
Inet1.requesttimeout = 60'in seconds
Inet1.URL = strURL
strHTML = Inet1.OpenURL'grab HTML page
现在strHTML保存着strURL指向的整个页面的HTML内容。要建立一个常规网络蜘蛛,你现在只需要调用 instr() 功能来看看你寻找的串是否在当前位置即可。你也可以按照href标记寻找,解析当前的 URL,然后把它设置到Internet 控件的属性中去,接着再继续打开另一个页面。用来查看所有链接的最 好方法是使用递归。
要注意的是,尽管这种方法很易于实行,却不是非常准确和强大。今天的许多搜索引擎都可以进行额外的 逻辑检查,例如计算一个页面中某一短语重复的次数,相关字词的近似程度等,有些甚至可以用来判断所搜寻 的语段与上下文的关系。
当把层次2全部记录到数据库后即硬愦中顺序为第一的(这里指序号为2的网站)网站链接开始提取其下面的的所有链接记录到数据库,并把这些网站链接标识为层次3;然后依次把层次为2的网站的所有链接记录到数据库,同时把他们的层次标识为层次3;
当层次3全部记录数据库后,开始从层次3中顺序为第一的网站链接开始提取,依次类推即可!
注意:程序要保留一个指针记录当前正在操作的序号!另外您也可以增加一个父序号字段来记录他们之间的继承关系!
搜索引擎建立网页索引,处理的对象是文本文件。对于网络蜘蛛来说,抓取下来网页包括各种格式,包括html、图片、doc、pdf、多媒体、动态网页及其它格式等。这些文件抓取下来后,需要把这些文件中的文本信息提取出来。准确提取这些文档的信息,一方面对搜索引擎的搜索准确性有重要作用,另一方面对于网络蜘蛛正确跟踪其它链接有一定影响。
对于doc、pdf等文档,这种由专业厂商提供的软件生成的文档,厂商都会提供相应的文本提取接口。网络蜘蛛只需要调用这些插件的接口,就可以轻松的提取文档中的文本信息和文件其它相关的信息。
HTML等文档不一样,HTML有一套自己的语法,通过不同的命令标识符来表示不同的字体、颜色、位置等版式,如:、、等,提取文本信息时需要把这些标识符都过滤掉。过滤标识符并非难事,因为这些标识符都有一定的规则,只要按照不同的标识符取得相应的信息即可。但在识别这些信息的时候,需要同步锹夹矶喟媸叫畔ⅲ缥淖值淖痔宕笮 ⑹欠袷潜晏狻⑹欠袷羌哟窒允尽⑹欠袷且趁娴墓丶实龋庑┬畔⒂兄诩扑愕ゴ试谕持械闹匾潭取M保杂贖TML网页来说,除了标题和正文以外,会有许多广告链接以及公共的频道链接,这些链接和文本正文一点关系也没有,在提取网页内容的时候,也需要过滤这些无用的链接。例如某个网站有“产品介绍”频道,因为导航条在网站内每个网页都有,若不过滤导航条链接,在搜索“产品介绍”的时候,则网站内每个网页都会搜索到,无疑会带来大量垃圾信息。过滤这些无效链接需要统计大量的网页结构规律,抽取一些共性,统一过滤;对于一些重要而结果特殊的网站,还需要个别处理。这就需要网络蜘蛛的设计有一定的扩展性。
四、网络蜘蛛的程序构架
用ASP构造网络蜘蛛
那么如何用ASP构建网络蜘蛛呢?答案是:Internet transfer control (ITC)。这个由 微软提供的控件,将使你能够通过ASP程序访问Internet资源。你可以用ITC搜寻Web页面,访问FTP服务器,甚 至可以发送邮件标题。在本文里,我们将着重讨论搜寻Web页面的功能。
有几个缺陷必须先说明一下。第一,ASP无权访问Windows的注册表,这就使某些ITC正常存储的常量和数 值不可用。通常你可以通过设置ITC为“不使用默认值”来解决这个问题,这就需要你在运行过程中指明每一 次的值。
另一个更严重的问题是关于许可证书的。由于ASP不具备调用License Manager(一项Windows中的功 能,可以保证组件和控件的合法使用)的功能,那么当License Manager检查当前组件的密钥密码,并将 其与Windows注册表进行比较后,如果发现它们不同,该组件将不会工作。因此,当你想把ITC配置到另一台没 有所需密钥的计算机上时,将导致ITC崩溃。解决的办法之一是将ITC捆绑到另一个VB组件中,由VB组件复制 ITC的路径和工具,从而进行配置。这项工作很麻烦,但不幸的是,它是必不可少的。
下面是一些例子:
你可以用下面的编码建立ITC:
有几个缺陷必须先说明一下。第一,ASP无权访问Windows的注册表,这就使某些ITC正常存储的常量和数 值不可用。通常你可以通过设置ITC为“不使用默认值”来解决这个问题,这就需要你在运行过程中指明每一 次的值。
另一个更严重的问题是关于许可证书的。由于ASP不具备调用License Manager(一项Windows中的功 能,可以保证组件和控件的合法使用)的功能,那么当License Manager检查当前组件的密钥密码,并将 其与Windows注册表进行比较后,如果发现它们不同,该组件将不会工作。因此,当你想把ITC配置到另一台没 有所需密钥的计算机上时,将导致ITC崩溃。解决的办法之一是将ITC捆绑到另一个VB组件中,由VB组件复制 ITC的路径和工具,从而进行配置。这项工作很麻烦,但不幸的是,它是必不可少的。
下面是一些例子:
你可以用下面的编码建立ITC:
set Inet1 = CreateObject("InetCtls.Inet")
Inet1.protocol = 4 'HTTP
Inet1.accesstype = 1 'Direct connection to internet
Inet1.requesttimeout = 60'in seconds
Inet1.URL = strURL
strHTML = Inet1.OpenURL'grab HTML page
现在strHTML保存着strURL指向的整个页面的HTML内容。要建立一个常规网络蜘蛛,你现在只需要调用 instr() 功能来看看你寻找的串是否在当前位置即可。你也可以按照href标记寻找,解析当前的 URL,然后把它设置到Internet 控件的属性中去,接着再继续打开另一个页面。用来查看所有链接的最 好方法是使用递归。
要注意的是,尽管这种方法很易于实行,却不是非常准确和强大。今天的许多搜索引擎都可以进行额外的 逻辑检查,例如计算一个页面中某一短语重复的次数,相关字词的近似程度等,有些甚至可以用来判断所搜寻 的语段与上下文的关系。
用VB构造网络蜘蛛
蜘蛛程序网站层次及其工作原理描述:
序号网站层次父序号
1http://www.netfox.cn/ 10
2http://www.sina.com.cn/21
3http://www.cnnic.cn/21
4http://www.baidu.cn/32
5http://www.yahoo.cn/32
序号网站层次父序号
1http://www.netfox.cn/ 10
2http://www.sina.com.cn/21
3http://www.cnnic.cn/21
4http://www.baidu.cn/32
5http://www.yahoo.cn/32
蜘蛛程序首先从层次1(http://www.netfox.cn/)开始提取所有的网站链接,把所有网站链接记录到数据库(或者大数组等),并把这些网站链接标识为层次2;
当把层次2全部记录到数据库后即硬愦中顺序为第一的(这里指序号为2的网站)网站链接开始提取其下面的的所有链接记录到数据库,并把这些网站链接标识为层次3;然后依次把层次为2的网站的所有链接记录到数据库,同时把他们的层次标识为层次3;
当层次3全部记录数据库后,开始从层次3中顺序为第一的网站链接开始提取,依次类推即可!
注意:程序要保留一个指针记录当前正在操作的序号!另外您也可以增加一个父序号字段来记录他们之间的继承关系!
层次1表示为网络种子;我们这里把网络种子放在第一层,根据需要您可以设置一个或者多个网络种子,实际上我们通过这个层次图可以很显然地看出来,低层次的网址就是高层次的网络种子。也就是说只要有一个或者几个网络种子,我们就可以通过他们的链接找到更多的网络种子。只要这样我们的蜘蛛才能永远地运行下去!
层次2是通过层次1(即网络种子)抓取到的链接;
层次3是通过层次2抓取到的链接;
依次类推,构成一棵大树!
蜘蛛程序关键代码:
这里使用VB实现核心部分的代码,当然您也可以很简单地转换成其他语言代码。在这里了为了简单起见,我们这里不对数据库操作,我们建立一个二维数组存放我们的网址!
Dim Web(4,10000)‘//建立数组
Dim Pointer‘//建立指针,记录当前种子
Dim Id ‘//建立序号,记录当前抓区网站的序号
Dim Layer‘//建立层次,记录当前正在运行种子的层次
Dim Running‘//建立是否运行的标志,
Private Function NewworkSeed_Set() As Boolean ‘//用来设置网络种子,为演示方便我们把种子放在数组,
'//当然您也可以根据需要把他们直接放到数据库中
Web(0,0) = 1 ‘//序号
Web(1,0) = “ http://www.netfox.cn/” ‘//网站
Web(2,0) = 1 ‘//层次
Web(3,0) = 0 ‘//父序号,0表示为网络原始种子
Web(4,0) = “奈福网络”
‘//当然这里可以设置多个网络原始种子
Web(0,1) = 1
Web(1,1) = “ http://www.aspfaq.cn/”
Web(2,1) = 1
Web(3,1) = 0
Web(4,1) = “asp技术站”
‘//设置网络种子后,记录种子序号开始后的序号,这里设置了2个种子,所以Id=2开始
Id = 2
End Function
Private Sub Spider_Work()‘//蜘蛛工作程序,抓取网站并记录到数组
‘//根据需要可以把他们放到数据库中
‘//根据需要可以把他们放到数据库中
Dim A
For Each A In WebBrowser.Document.All
If UCase(A.tagName) = "A" Then
If IsValidWeb(A.href) Then
Id = Id + 1
Web(0, Id) = Id‘//记录当前网站的序号
Web(1, Id) = A.href ‘//记录当前网站
Web(2, Id) = Layer ‘//记录当前网站的层次
If Web(2,Pointer)<> Layer Then Layer = Layer + 1‘//当指针层次与当前层次不同的话
‘//则说明层次已经发生了增加
Web(3, Id) = Pointer ‘//记录当前网站的父序号
Web(4,Id) = A.innerText‘//记录当前网站的名称
End If
End If
Next
Pointer = Pointer + 1
WebBrowser.Navigate Web(1, Pointer-1) ‘//抓取当前种子完毕后,自动跳转到下一个种子
If Running = False Then‘//运行为否,退出运行
Exit Sub
End If
End Sub
Private Function Spider_Init() As Boolean‘//蜘蛛程序初始化函数
Pointer = 1 ‘//指针设置为1,表示从第一个序号开始运行
Id = 2‘//序号设置为2,以后可以读取记录
Layer = 0‘//层次设置为0,表示蜘蛛第一次运行
‘//以上指针,序号,层次都可以记录并且方便以后读取
If IsValidWeb(Web(1, Pointer-1)) Then‘//判断种子是否正确,如果正确初始化成功,否则失败
Running = True
Spider_Init = True
WebBrowser.Navigate Web(1, Pointer-1)
Else
Running = False
Spider_Init = False
Exit Function
End If
End Function
Private Sub WebBrowser_DocumentComplete(ByVal pDisp As Object, URL As Variant) ‘//WebBrowser控件
Call Spider_Work()
End Sub
Private Function IsValidWeb(_href) As Boolean ‘//判断是否是cn域名函数
‘//通过该函数可以实现抓取指定网站或数据
If InStr(_href, " http://www.") > 0 And InStr(_href, ".cn/") > 0 And Len(_href) < 60 Then
IsValidWeb = True
Else
IsValidWeb = False
End If
End Function
Private Sub InitCommand_Click()‘//Init初始化 命令控件
If Spider_Init() Then
Msgbox “蜘蛛初始化成功并开始运行了”
Else
Msgbox “蜘蛛初始化失败”
End If
End Private
Private Sub StopCommand_Click()‘//Stop停止 命令控件
Running = False ‘//停止运行
End Private
Private Sub RunCommand_Click() ‘//Run运行 命令控件
Running = True‘//继续运行
Call Spider_Work()‘//蜘蛛运行主程序
End Private
特定网络蜘蛛
相对的,一个特定网络蜘蛛要复杂一些。如我们早先提到的,一个特定网络蜘蛛会搜寻一个页面的特定部 分,因而要求预先知道该部分相关的情况。让我们先看看下面的HTML:
<HTML>
<HTML>
<HEAD>
<TITLE>My News Page</TITLE>
<META Name="keywords" Content="News, headlines">
<META Name="descr iption" Content="The current news headlines.">
</HEAD>
<BODY BGCOLOR="#FFFFFF" TEXT="#000000" LINK="#FF3300 "VLINK="#CC0000" ALINK="#0000FF">
<p><h3>Headlines&l t;/h3></p>
<!--put headlines here-->
<a href="/news/8094.asp _fcksavedurl=""/news/8094.asp" ">Stocks prices fall</a><a href="/news/8095.asp">New movies today</a><ahref="/news/8096.asp">Bush and&nb sp;Gore to debate tonight</a><a href="/news/8097.asp"> Fall TV lineup</a>
<!--end headlines-->
</BODY>
</HTML>
在这个页面内,我们只关心位于“put headlines here”和 “end headlines”这 两个标记之间的东西。你可以构建一个只返回该区域查找结果的功能设置:
在这个页面内,我们只关心位于“put headlines here”和 “end headlines”这 两个标记之间的东西。你可以构建一个只返回该区域查找结果的功能设置:
Function GetText(strText, strStartTag, strEndTag)
dim intStart
intStart = instr(1, strText, strStartTag, vbtextcompare)
if intStart then
intStart = intStart + len(strStartTag)
intEnd = InStr(intStart + 1, strText, strEndTag, vbtextcompar e)
GetText = Mid(strText, intStart + 1, intEnd - intStart&n bsp;- 1)
else
GetText = " "
end if
End Function
dim intStart
intStart = instr(1, strText, strStartTag, vbtextcompare)
if intStart then
intStart = intStart + len(strStartTag)
intEnd = InStr(intStart + 1, strText, strEndTag, vbtextcompar e)
GetText = Mid(strText, intStart + 1, intEnd - intStart&n bsp;- 1)
else
GetText = " "
end if
End Function
按照上面构建ITC控件的例子,你可以很容易地将strHTML中的“ <!--put headlines here-->”和 “<!--end headlines-->”作为参数传 送到GetText中。
要注意,用于开始和结束的标记都不一定要是实际的HTML专用标记——它们可以是你想使用的任何文本界 定符。在通常情况下,你不容易找到好的HTML标记来界定搜寻区域。你只能使用比较方便称手的标记——例如 ,你的首尾标记可以分别如下:
按照上面构建ITC控件的例子,你可以很容易地将strHTML中的“ <!--put headlines here-->”和 “<!--end headlines-->”作为参数传 送到GetText中。
要注意,用于开始和结束的标记都不一定要是实际的HTML专用标记——它们可以是你想使用的任何文本界 定符。在通常情况下,你不容易找到好的HTML标记来界定搜寻区域。你只能使用比较方便称手的标记——例如 ,你的首尾标记可以分别如下:
strStartTag = "/td><td><font face="arial" size=&q uot;2"><p><b><u>"
strEndTag = "<p></td></tr><tr><td><ums>&quo t;
一定要确定搜索的是HTML页中比较独特的标识,这样你才可以准确地获得你需要的东西。你也可以按照你 所返回的文本部分中的链接进行搜寻,不过如果你不知道那些页面的格式,你的网络蜘蛛将无功而返。
strEndTag = "<p></td></tr><tr><td><ums>&quo t;
一定要确定搜索的是HTML页中比较独特的标识,这样你才可以准确地获得你需要的东西。你也可以按照你 所返回的文本部分中的链接进行搜寻,不过如果你不知道那些页面的格式,你的网络蜘蛛将无功而返。