《使用python进行自然语言理解》学习笔记二
第一章 安装NLTK环境
四 NLTK下的基本操作
1 命名小技巧
(1) 排序表中大写字母出现在小写字母之前;
(2) 选择有意义的变量名,它能提醒你代码的含义,也帮助别人读懂你的代码;
(3) 经常使用变量来保存计算的中间步骤,尤其是当这样做使代码更容易读懂时;
(4) 应该以字母开始,大小写敏感,不能包含空格但可以用下划线;
2 字符串的合并和拆分
(1) ' '.join(['Monty', 'Python']) 合并
(2) 'Monty Python'.split() 拆分
3 统计信息分析
一段小程序
#!/usr/python/bin
#Filename:NltkTest38,一些关于文本的统计信息的测试
from__future__ import division
importnltk
fromnltk.book import *
classNltkTest38:
def __init__(self,text):
self.text=text
print self.text
def FreqAnalyse(self,queryStr):
'''统计高频和低频词并对TOP50的高频词画图'''
fdist=FreqDist(self.text)
fdist
vocabulary=fdist.keys()
hapaxesWord=fdist.hapaxes()
#单频词
print hapaxesWord[:50]
#高频词
print vocabulary[:50]
#画图,False看的舒服一些
fdist.plot(50, cumulative=False)
print fdist[queryStr]
def LongWord(self):
'''找出长度大于15的词汇'''
voc=set(self.text)
#长度大于15的词
longWords=[word for word in voc iflen(word)>15]
print 'long words :'
print sorted(longWords)
def CheckUseless(self):
'''找出高频词和长低频词'''
fdist=FreqDist(self.text)
print '高频词和长低频:'
print sorted([word for word inset(self.text) if len(word) > 7 and fdist[word] > 7])
def BigramsCheck(self):
'''提取文本词汇中的词对也就是双连词'''
#指定词查找双连词
print '双连词:'
print bigrams(['more', 'is', 'said', 'than','done'])
#全局找双连词
print self.text.collocations()
def Others(self):
'''计数其他东西'''
fdist = FreqDist([len(word) for word inself.text])
fdist
print fdist.keys()
print fdist.items()
print fdist[fdist.max()]
print fdist.freq(fdist.max())
fdist.tabulate()
fdist.plot()
nt38=NltkTest38(text1)
nt38.FreqAnalyse('whale')
nt38.LongWord()
nt38.CheckUseless()
nt38.BigramsCheck()
nt38.Others()
但是好像有点不对
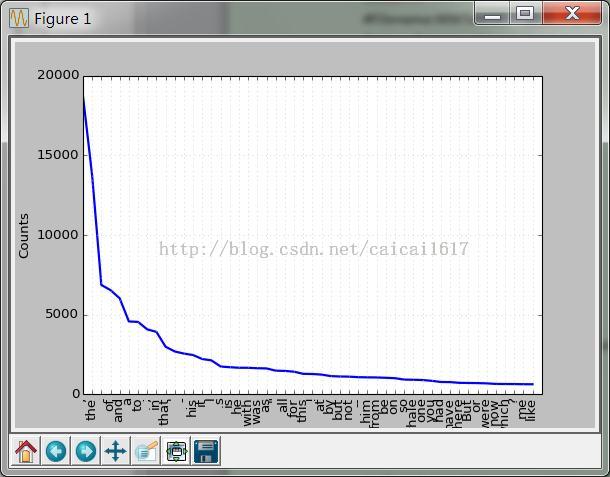
(1) fdist.plot这不是累积频率图啊,这是出现次数的统计图,至于怎么出书里的那个图,再研究一下
(2)在高频词汇中,有很多无用的词汇,称作管道英语。只出现了一次的词hapaxes,低频词汇也很多,如果不分析上下文很难才出他们的意义。高频和低频词汇都很少有帮助,要寻找其他办法分析。这样找到了长词。在此基础上,在分析长词出现的概率,会更有效。这样忽略的短高频词和长低频词。图里可以看到确实是长度3的单词最多,然后长词就大多低频。

(3)词语搭配和双连词(bigrams)
使用bigrams提取文本词汇中的词对,也就是双连词。
text4.collocations()找到比我们基于单个词的频率预期得到的更频繁出现的双连词
(4) 其他
看代码…
一些常用的NLTK频率分布类中定义的函数
fdist=FreqDist(samples)创建包含给定样本的频率分布
fist.inc(sample)增加样本
fdist['monstrous']计数给定样本出现的次数
fdist.freq('monstrous')给定样本的频率
fdistN()样本总数
fdist.keys()以频率递减顺序排序的样本链表
for sample in fdist:以频率递减的顺序遍历样本
fdist.max()数值最大的样本
fdist.tabulate()绘制频率分布表
fdist.plot()绘制频率分布图
fdist.plot(cumulative=True)绘制累计频率分布图
fdist1<fdist2测试样本在fdist1中出现的概率是否小于fdist2
4回到 Python:决策与控制
(1)关系运算符
简单的不说了看代码
#!/usr/python/bin
#Filename:NltkTest42,一些关于文本的统计信息的测试
from __future__ import division
import nltk
from nltk.book import *
import time
import datetime
class NltkTest42:
def __init__(self,text,sent):
self.text=text
self.sent=sent
print self.text
print self.sent
def SomeTests(self):
'''简单的逻辑关系的测试'''
print self.sent
print [w for w in self.sent if len(w) < 4]
print [w for w in self.sent if len(w) <= 4]
print [w for w in self.sent if len(w) == 4]
print [w for w in self.sent if len(w) != 4]
print sorted([w for w in set(self.text) if w.endswith('ableness')])
print sorted([term for term in set(self.text) if 'gnt' in term])
sorted([item for item in set(self.text) if item.istitle()])
sorted([item for item in set(self.sent) if item.isdigit()])
[len(w) for w in self.text]
[w.upper() for w in self.text]
tricky = sorted([w for w in set(self.text) if 'cie' in w or 'cei' in w])
for word in tricky:
if(len(word)>10):
print word
nt42=NltkTest42(text1,sent7)
starttime = datetime.datetime.now()
print 'Start at:'
print time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
nt42.SomeTests()
endtime = datetime.datetime.now()
print 'Finish at:'
print time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
print '程序才运行了%d秒' %(endtime - starttime).seconds
print '聪明的你告诉我,其他的时间都去哪了?'

一些词比较运算符
s.startswith(t) 测试 s 是否以 t 开头
s.endswith(t) 测试 s 是否以 t 结尾
t in s 测试 s 是否包含 t
s.islower() 测试 s 中所有字符是否都是小写字母
s.isupper() 测试 s 中所有字符是否都是大写字母
s.isalpha() 测试 s 中所有字符是否都是字母
s.isalnum() 测试 s 中所有字符是否都是字母或数字
s.isdigit() 测试 s 中所有字符是否都是数字
s.istitle() 测试 s 是否首字母大写(s 中所有的词都首字母大写)
5自动理解自然语言
(1) 在词意消歧中, 我们要算出特定上下文中的词被赋予的是哪个意思。
(2) 要回答这个问题涉及到寻找代词 they 的先行词 thieves 或者 paintings。处理这个问题的计算技术包括指代消解(anaphora resolution ),确定代词或名词短语指的是什么和语义角色标注(semantic role labeling )——确定名词短语如何与动词相关联(如施事,受事,工具等) 。
(3) 自动生成语言, 自动问答和机器翻译。
(4) 人机对话系统, nltk.chat.chatbots()就会那么几句,没有小黄鸡好玩。
(5) 文本的含义,文本含义识别(RecognizingTextual Entailment 简称 RTE)的公开的“共享任务”使语言理解所面临的挑战成为关注焦点。
(6) NLP 的局限性,等大家努力解决吧。
6小结
编程语言都是这样,跟你说怎么是对怎么是错都难一次就记牢,还是得去做才能又长进。而且写python比C和java欢乐多了。嘿嘿
转自http://blog.csdn.net/caicai1617/article/details/21041925