Lucene.Net Research
Lucene.Net Research
The history of Lucene. 1
What is the Lucene. 1
Lucene.net basic objects. 2
Behind the scenes of indexing. 8
Concurrency rules of Lucene. 10
The history of Lucene
Lucene的起源
1997年末,Doug Cutting的工作任务不是很明确,Doug Cutting已经会编写搜索软件,这个时候他发现Java是一个不错的新语言,为了给自己找了个理由学习Java编程,他很自然的结合了自己会编写搜索程序的能力,编写了Lucene.
本来Doug Cutting打算出售Lucene,但是到了2000年,他发现自己对于和别人谈判做生意的事情没有兴趣,也不喜欢组建公司,所以他就将Lucene源代码递交到了SourceForge组织。
很快,一些人开始使用Lucene。2001年,Aparch开始使用Lucene。到了2004年,已经有很多人非常熟悉Lucene的核心代码,这么一支强有力的队伍不停的提高Lucene的稳定性和性能。Lucene也演绎出了多个语言版本,c++ 、c#、Perl、Python。Lucene应用之广泛已经远远超过了Doug Cutting当初能够梦想到的程度。
Lucene增强了财富论坛前一百名的公司的各种应用程序的搜索能力,应用于商业问题追踪,应用于Microsoft的email搜索服务,并且作为web搜索引擎的核心部分可以支持100亿网页的搜索。
如果当初Doug Cutting出售Lucene,Lucene就不可能像今天这样广泛应用,这就是开源的巨大力量,Doug Cutting给了Lucene生命,但是更多的Lucene社区的人的加入使得Lucene真正兴旺起来。
What is the Lucene
Lucene是一个类库,提供了对文本建立索引和搜索的高性能解决方案。你可以用它来建立web search engine,但是你需要自己编写网络蜘蛛程序。你的应用程序逻辑在上,Lucene在下。因此,Lucene不是一个直接交付给客户的产品。
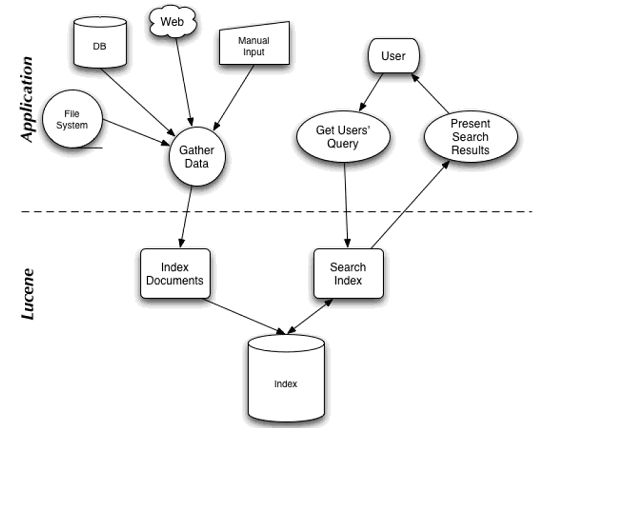
Lucene不关心数据格式或者语言类别,只要你能将各种各样的数据转换成文本即可。因此,我们可以为实时聊天纪录、office文档、PDF文档、数据库中的资料、网页等任何可转换成文本形式的数据建立索引,并进行查询。
Lucene两个基本概念是index和search.我们可以将index理解为一本书中快速查找的索引。实际上它是一个数据结构。Lucene将为各种需要查找的文本形式数据建立索引。
Lucene.net basic objects
Lucene类库中不提供Index类,但是Index仍然是核心的概念,Lucene中一个Index由一个索引文件夹代表。该文件夹里面包含了若干了segment文件,每个segment文件可以包含若干个Document对象。现在我们从基本的Document对象开始。
Document和Field主要用于存储索引和查询索引。Document可以包含若干个Fields.并且提供了一些方法访问Field.有四种Field可供选择,见下表:
|
Keyword
|
不分析内容,建立索引,保存内容在索引文件中
|
|
UnIndexed
|
不分析内容,不建立索引,只保存内容到索引文件中
|
|
UnStored
|
分析内容,建立索引,不保存内容
|
|
Text
|
分析内容,建立索引,如果是字符串则保存内容,否则不保存
|
示例代码:
public
void CreateDocument(IDataReader reader)
{
document = new Document();
int count = reader.FieldCount;
for (int i = 0; i < count; ++i)
{
string name = reader.GetName(i);
if (name != "IssueID")
{
document.Add(Field.UnStored(name, reader[i].ToString()));
}
else
{
document.Add(Field.Keyword(name, reader[i].ToString()));
}
}
writer.AddDocument(document);
}
在建立索引的时候,为了确定Field的类型,可以问自己四个问题:
1) 需要对这个Field进行搜索么?
如果要,则需要支持建立索引;如果不要,则不需要为该Field建立索引
2) 要对内容做部分搜索么?
如果是,则需要支持分析,否则不支持分析
3) 要保存内容么?
如果内容太大,还是不保存为好,否则随便。
4) 需要按照某个Field的值排序么?
如果需要,考虑用Keyword
在上面的代码中,我们让一个Document对象对应一条数据库记录,让每一个Field对应记录里面的每个字段值。
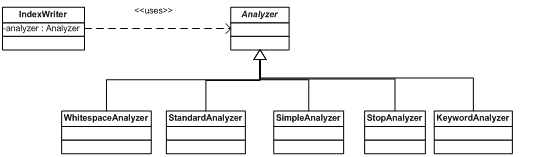
IndexWriter提供了对Index的写操作能力。如下面的代码:
public
void CreateIndexe()
{
writer = new IndexWriter(projectIndexPath, new StandardAnalyzer(), true);
using (IDataReader reader = LoadIssues(projectID))
{
while (reader.Read())
{
CreateDocument(reader);
}
}
writer.Optimize();
writer.Close();
}
CreateDocument函数内部将已经创建好的Document对象加入到writer对象中。参见上面的示例代码。
Analyzer是一个抽象类,他的主要作用是从字符串中抽取要作索引的标记。由于它的具体的实现类会将大写转换成小写,所以Lucene的搜索是大小写不敏感的。


IndexSearch类提供了search方法进行查询,它需要接受一个Query对象,Query对象封装了具体的查询要求和查询方式。QueryParser接受人类可辨别的查询表达式,并创建Query的子类对象。Hits对象包含了查询结果(document对象的引用),并且顺序已经按照Lucene的默认记分规则排序。
string
indexFilePath = String.Format(@"{0}/{1}", indexDirectory, projectID);
searcher = new IndexSearcher(indexFilePath);
List<int> issues = new List<int>();
using (IDataReader reader = LoadIssuesOfProject(projectID))
{
int count = reader.FieldCount;
for (int j = 0; j < count; ++j)
{
string name = reader.GetName(j);
Query query = QueryParser.Parse(keyword, name, new StandardAnalyzer());
Hits hits = searcher.Search(query);
for (int i = 0; i < hits.Length(); ++i)
{
Document doc = hits.Doc(i);
Field field = doc.GetField("IssueID");
int issueID = int.Parse(field.StringValue());
if (!issues.Contains(issueID))
{
issues.Add(issueID);//insert a issue id into issues;
}
}
}
}
查询表达式有些语法,见下表:
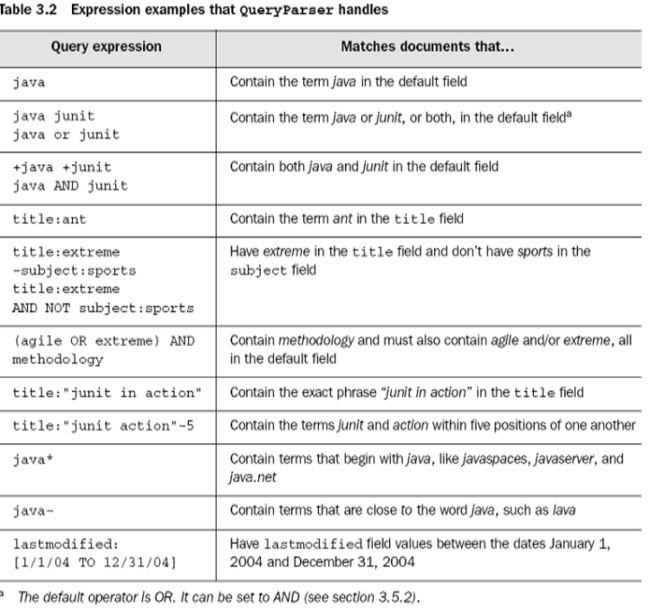
前面我们假定Document对象对应一条记录,每个Field对象对应一个字段,但是这容易让我们产生误解,以为一个索引下面的每个Document对象都必须一样的规整,实际上,Lucene给我们提供了很大的灵活性,我们可以这样建立索引对象。
我们看看上面的示例图,为了能够将比较多的信息存储到一个Field对象中,我将姓名、性别、会员类别 拼成一个字符串,然后保存到Field对象中,这样做固然可以,不过Lucene提供了一个更加优雅的方法:
document.Add(Field.Text(
“
王英
”
,
“
29
岁
”
);
document.Add(Field.Text(
“
王英
”
,
“
男
”
);
document.Add(Field.Text(
“
王英
”
,
“
普通会员
”
);
通过反复调用
Add方法,每次创建Field的时候,传递相同的名字,Lucene内部在建立索引的时候会将它们合并为一个Field。
我们可以用IndexReader打开一个索引,但是这个Reader类居然可以执行一些删除document对象的操作,这个设计并不符合它的名称。
maxDocs返回当前文档对象中的最大ID,numDocs返回没有被标记为删除的所有文档对象的数目,close函数内部将执行真正的删除操作。
我们没有办法直接修改一个
document对象,我们只能先删除,然后再插入一个新的document对象才行。因为IndexReader对象只能删除,不能插入新的document对象,所以这里还需要IndexWriter对象帮助才行。
我个人认为这个设计很不好,应该让
IndexWriter对象负责所有的写操作,IndexReader对象不应该有写操作的能力。IndexWriter也应该提供一个Update操作,虽然里面实现逻辑仍然可能是先删除,后插入,但是毕竟这是一个常用的操作,有必要提供。
Behind the scenes of indexing
索引是如何建立的呢?当我们添加
Document对象到IndexWriter中时,Lucene会检查mergeFactor变量的值n,如果我们添加的对象数目达到n,Lucene就会将其存成一个segment文件,如果索引中的segment文件数目也达到了n,Lucene就会将它们合并成一个更大的segment文件。但是一个segment文件中包含的Document对象是有上限的,由maxMergeDocs变量控制,默认值是int类型的最大值。minMergeDocs变量规定了每个segment文件中最小包含的Document对象数目。
public
void CreateIndexe()
{
writer = new IndexWriter(projectIndexPath, new StandardAnalyzer(), true);
writer.mergeFactor = 2000;
writer.minMergeDocs = 1000;
using (IDataReader reader = LoadIssues(projectID))
{
while (reader.Read())
{
CreateDocument(reader);
}
}
writer.Optimize();
writer.Close();
}
IndexWriter对象内部怎么写文件的呢?让我们看一下它的构造函数:
public
IndexWriter(System.IO.FileInfo path, Analyzer a, bool create) : this(FSDirectory.GetDirectory(path, create), a, create, true)
{
}
我们发现有一个
FSDirecotry对象,该对象代表了索引目录,并负责写操作。
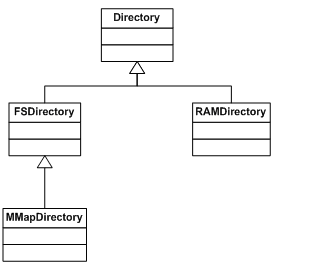
实际上,
IndexWriter类的构造函数接受的是Directory对象,如果我们创建RAMDirectory对象并传递给构造函数,这就意味着一切操作都会在内存里发生,我们可以把RAMDirectory对象看成内存里面的虚拟文件夹对象,显然这是速度最快的,因为没有发生任何的文件操作,通常我们在调试程序时使用它。如果我们只是传递一个文件夹路径给构造函数,构造函数内部会进行多次调用其他重载构造函数,并且创建FSDirectory对象,这就真正的去做文件写操作了。
RAMDirectory还有一种用法,先将所有的
Document对象都建立在使用RAMDirectory对象的IndexWriter对象上面,这时候速度很快,一切都在内存里面,在合适的时候,创建另一个IndexWriter对象,该对象使用FSDirectory对象进行文件操作,然后调用IndexWriter::AddIndexes将第一个IndexWriter中的索引转移过来。
这种方法可以让我们对于内存操作和文件操作进行比较精确的控制,我们要做的就是选择合适的时机,不要让内存太过膨胀。
还有更高级的应用,如果我们的服务器上有多个
cpu和较多内存(通常如此),我们可以让不同的线程在内存里面创建不同的索引,然后通过真正写文件的IndexWriter对象进行文件操作。如图:
如上所述,
mergeFactor、maxMergeDocs、minMergeDocs三个变量是我们可以提供建立索引的速度,但是他们会带了另一个副作用,就是产生了很多的segment文件。IndexWriter类提供了Optimize方法,该方法可以将很多小的segment文件合并成一个segment文件,这样会当我们查询时,Lucene将从一个文件中读取,大大提高了性能。
当然,
Optimize方法本身涉及很多文件的合并,所以会导致建立索引的时间变长。在这么多可供选择,又互相矛盾的选择中,我们应用开发人员必须做出仲裁,一个简单的办法是提供可以配置的管理程序,并且记录建立索引的时间,系统管理员可以根据系统运行的情况,数据的多少,服务器的硬件配置,进行适当的调整,寻找最优的建立索引的方案。
Concurrency rules of Lucene
1) 任何时候,只能有一个操作可以修改索引
IndexWriter和
IndexReader是线程安全的,如果我们尝试着在多个线程中使用一个IndexWriter或者IndexReader对象的方法进行索引修改,Lucene保证会对他们的修改操作进行同步。如下图:
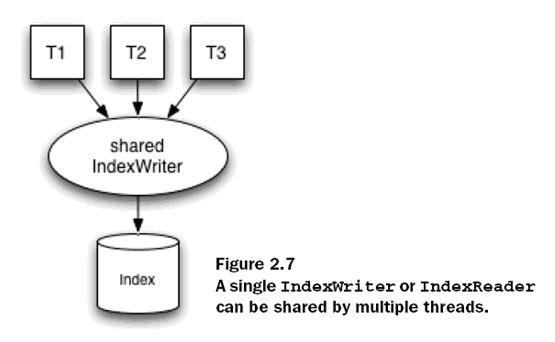
需要注意以下几点:
当
Optimize一个索引或者Merge一个索引的时候,不允许删除Document对象
当删除一个
Document对象的时候,不允许添加Document对象
IndexWriter和
IndexReader对象的修改操作不能同时发生
2) 当一个修改索引操作发生时,仍然可以对该索引做查询
3)支持多个查询动作
未完 待续
陈抒
2006-12-2