NETDEV 协议 六
Linux协议栈中处理重复地址检测报文的是arp_process()中的一段代码,RFC2131是DHCP的草案,相应的sip==0是DHCP服务器用来检测它所分发的地址是否重复的。
杂谈2:NUD状态转移的实际理解
根据NUD的状态转移,实际测试两种情况:NUD_INCOMPLETE和NUD_PROBE。
NUD_INCOMPLETE
Linux Host随便telnet一个没有使用的IP1,协议栈会为会IP1创建一个邻居表项,状态由NUD_NONE迁移到NUD_INCOMPLETE,具体的协议栈流程在上篇ARP[http://blog.csdn.net/qy532846454/article/details/6806197]中分析的。
在Linux Host上telnet XX.XX.86.198,捕获到的发包状况如下:
NUD_PROBE
NUD_PROBE测试复杂一点,先由一台Host1(IP2)向Linux Host发送arp request请求,协议栈会为IP2创建一个邻居表项,状态由NUD_NONE -> NUD_STALE,然后Linux Host会响应request,状态由NUD_STALE -> NUD_DELAY -> NUD_PROBE,具体的协议栈流程在上篇ARP[http://blog.csdn.net/qy532846454/article/details/6806197]中分析的。
由Host1构造假arp request(sip=未被使用IP, tip=Linux Host IP)给Linux Host,捕获到的发包状况如下:

每一个包是Host1发出的request,每二个包是Linux Host的回复,后三个包是3次ARP单播尝试,此时处于NUD_PROBE状态要尝试对方是否存活,由于sip使用的是虚假址,因此没有响应,在尝试了最大次数3次,对应arp_tbl中的参数ucast_probe=3次数,每次尝试的间隔时间近似1s,对应arp_tbl中的参数retrans_time=1HZ。
对比下windows这方面的处理可以发现,两者在这方面的行为相差很大:比如windows的网络协议栈会处理RFC826所规定的gratuitous arp报文;windows的arp尝试只会进行一次。
ICMP模块比较简单,要注意的是icmp的速率限制策略,向IP层传输数据ip_append_data()和ip_push_pending_frames()。
在net/ipv4/af_inet.c中的inet_init()注册icmp协议,从这里也可以看出,ICMP模块是绑定在IP模块之上的。inet_add_protocol()会将icmp_protocol加入到全局量inet_protos中。
除了注册icmp协议,还要对icmp模块初始化,这部分由icmp_init()完成。
icmp_init()函数做的事很简单,register_pernet_subsys(&icmp_sk_ops),而注册icmp网络子系统过程中会调用icmp_sk_ops.init(即icmp_sk_init函数)来完成它的初始化,下面具体看icmp_sk_init()函数。
首先为net为配CPU数目(nr_cpu_ids)个struct sock结构体空间,这里的net是全局的网络名,一般是init_inet。
net->ipv4.icmp_sk = kzalloc(nr_cpu_ids * sizeof(struct sock *), GFP_KERNEL);
每个CPU i,它的sock结构体位于net中的icmp_sk[i]。于每个CPU i,初始化刚刚分配的icmp_sk[i]:
-第一步,inet_ctl_sock_create()创建sk,并在net->ipv4.icmp_sk[i] = sk中将其赋值给icmp_sk[i]。
-第二步:ICMP发送缓存区大小sk_sndbuf设置为128K
忽略发往广播地址的icmp echo报文;忽略发往广播地址的错误的响应报文;
设置icmp处理速率,这里的ratelimit和ratemask参数在后面限速处理时会具体用到。
初始化工作完成后,还是从icmp的接收开始,icmp_rcv完成icmp报文的处理。
取得icmp报头,此时skb->transport_header是在IP模块处理中的ip_local_deliver_finish()将其设置为了指向icmp报头的位置。
根据icmp的类型type交由不同的处理函数去完成。
icmp_pointers是在icmp.c中定义的全局量,部分如下:
比如对于收到的icmp报文type为0或1(响应答复或目的不可达),协议栈要做的就是丢弃掉它 – icmp_discard()。下面以icmp echo和icmp timestamp为例说明。
收到icmp echo报文执行icmp_echo()
icmp_param是回复时信息,它直接拷贝了echo的ICMP报头icmp_hdr(skb),仅仅改变了报头的type = ICMP_ECHO_REPLY,然后调用icmp_reply()处理发送。
收到icmp timestamp报文后执行icmp_timestamp()
经过IP层处理,skb->data指向icmp报头的位置,而报头最小为4字节,所以这里判断skb->len < 4,是则丢弃该报文。从这里也可以看出,时间戳请求报文可以只有4节字头部,而没有时间戳信息。
这段代码设置时间戳响应的时间戳信息,包括接收时间戳和发送时间戳,两者分别代表主机收到报文的时间,发送响应报文的时间,而从这部分代码也可以看出icmp_param.data.times[2] = icmp_param.data.times[1]协议栈简单的将接收和发送时间戳置为相同的。时间戳的计算很简单,格林尼治时间的当天时间的微秒数。最后skb_copy_bits()从skb的ICMP报文内容拷贝4节字的时间到icmp_param_data.times[0],即发起时间戳,所以最后情形如下:
icmp_param_data.times[0] 发起时间戳,从请求报文中拷贝
icmp_param_data.times[0] 接收时间戳,处理ICMP报头时的时间
icmp_param_data.times[0] 发送时间戳,设置为与接收时间戳相同
前面已经说过,icmp_param就是要发送ICMP报文的内容,上面设置了内容,接下来设置报头,同样是直接拷贝了ICMP请求的报头,改变type为ICMP_TIMESTAMPREPLY。注意这里的data_len设置为0,因为它与icmp echo不同,一定是没有分片的,即没有paged_data部分。head_len设置为icmphdrlen+12,这里是为了调用icmp_reply()回复时的统一,实现表示ICMP部分的长度,主要是有分片时会根据head_len来跳过报头而只拷贝每个分片的内容。
icmp_param.data.icmph = *icmp_hdr(skb); icmp_param.data.icmph.type = ICMP_TIMESTAMPREPLY; icmp_param.data.icmph.code = 0; icmp_param.skb = skb; icmp_param.offset = 0; icmp_param.data_len = 0; icmp_param.head_len = sizeof(struct icmphdr) + 12;
最后调用icmp_reply()回复,这与icmp_echo()是相同的。
注意两者设置icmp_param参数时的区别:
icmp_echo()中icmp_param.data_len=skb->len;
icmp_param.head_len=sizeof(struct icmphdr);
icmp_timestamp()中icmp_param.data_len=0。
icmp_param.head_len=sizeof(struct icmphdr)+12;
icmp_reply()
通过ip_route_output_key()查找路由信息,存放在rt中。路由项在这里有两个作用:一是限速是针对每个路由项的,在icmpv4_xrlim_allow()中会用到;二是将报文传递给IP层需要用到rt。仔细观察流程可以发现,报文在协议栈传递过程中,在IP层会 查找一次路由表获取到了rt,而在这里又查找了一次路由表,似乎是重复了。其实不是,IP层查找是在报文接收阶段,这里的查找是在报文的发送阶段。
协议栈对于部分ICMP报文进行了限速,但这种限速不是整体的,而是针对每个路由项的,即限制每个地址发送ICMP报文的限率。icmpv4_xrlim_allow()判断该icmp报文是否需要被限速,如果能接收,则调用icmp_puash_reply()发送响应。
icmpv4_xrlim_allow() -> xrlim_allow() 限速处理
速率有关的参数是在icmp_init() -> icmp_sk_init()创建ICMP的sock时设置的,ratelimit是限制的速率,即TBF代码段中的timeout,可以理解成一个令牌;ratemask是被限制速率的ICMP的报文类型,(1 << type & retemask) == 1判断是否限速,type即ICMP类型,可见默认情况下[3]dest unreachable, [4]source quench, [11]time exceeded, [12]parameter problem才会被限速。
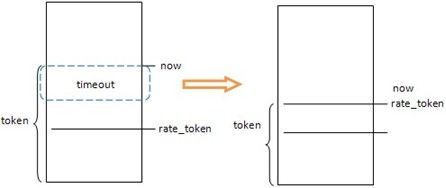
限速使用了Token Bucket Filter(令牌环过滤器)思想,大致是每个到来的令牌从数据队列中收集一个数据包,然后从桶中删除。令牌被耗尽时,数据包将停止发送一段时间。
ICMP的限速使用的就是这种思想,不过时间作为令牌,它的增长是连续的;每来一个报文,拿走一个令牌,则是一个时间段timeout,令牌也限定了最大数目是XRLIM_BURST_FACTOR为6;简单来讲就是每过timeout时间,令牌数就加1,当令牌数达到6时不再增加;而来一个报文,令牌数就减一,当令牌数为空时,不再减少,该报文也被丢弃;在这种情况下,在过timeout时间,才会处理下一个报文。实现的代码段如下:
dst->rate_tokens记录上一次的令牌,dst->rate_last记录上一次访问时间,now – dst->rate_last为经过的时间即增加的令牌数;当token>=timeout时即至少还有一个令牌,反回rc=1表示仍有令牌,不用限速;否则返回rc=0,限速。
icmp_push_reply() 发送回复报文
取出icmp使用的sock sk
if中的ip_append_data()函数表示把数据添加到sk->sk_write_queue,这个函数是用于上层向IP层传输报文,它会进行分片的操作,实际是帮IP层做了分片。具体函数调用参见后面的ip_append_data()函数分析。正常情况ip_append_data()返回0,即if的执行语句不会被触发。
else if进入条件是sk->sk_write_queue中已有数据,显然在if的判断语句中已经将报文添加到了sk->sk_write_queue中,所以会进入else if执行语句调用ip_push_pending_frames()将报文传递给IP层。而在ip_append_data()函数中可以看到,它只是拷贝了报文内容,并没有生成ICMP报头,ICMP报头生成当然也是在通过ip_push_pending_frames()将报文发给IP层前生成的。取出skb,计算所有分片一起的校验和,然过通过csum_partial_copy_nocheck()生成新的icmp报头,最后调用ip_push_pending_frames()发送数据到IP层。函数ip_push_pending_frames()函数分析也参见后文。
ip_append_data() 添加要传递到IP层的数据
传入参数的解释:
getfrag() – 复制数据,这里使用函数指针隐藏了复制细节,因为针对icmp, udp的复制是不同的;
from – 被复制的数据,在icmp模块中该参数传入的是struct icmp_bxm;
length – IP报文内容长度
transhdrlen – 传输报头长度,尽管ICMP归为网络层协议,但这里的transhdrlen也是包括它的,所以更好的解释是表示IP上一层的报头,比如ICMP报头,IGMP报头,UDP报头等长度

ip_append_data()函数比较复杂,这里以两个例子来解释这个函数:发送50 Byte的echo报文,发送600 Byte的echo报文。56字节echo报文在IP层不需要分片;600字节echo报文在IP层需要分片。ip_append_data()还可以多次调用来收集数据,而在ICMP模块中这点并不能体现出来,在以后UDP或TCP时再以解释多次调用的情况。
example 1:50 Byte echo报文 [假设MTU=520]
如果sk_write_queue为空,则证明是第一个分片,50字节的报文只需要一个分片。这里会设置exthdrlen,表示链路层额外的报头长,一般情况下是0,所以此时length和transhdrlen值仍是传入的值。而sk->sk_sndmsg_page和sk->sk_sndmsg_off与发散/聚合IO有关,这里先不考虑。
设置各种参数的值,hh_len表示以太网报头的长度,16字节对齐;fragheaderlen表示分片报头长度,即IP报头;maxfraglen表示最大分片长度。各参数值:hh_len = 16, fragheaderlen = 20, maxfraglen = 516,注意要求的节字对齐。

此时sk->sk_write_queue还为空,跳转至alloc_new_skb执行分配新的skb。
fraggap在上一个skb没有8字节对齐时设置为多余的字节数,否则的话fraggap=0;datalen表示IP报文长度(不包括IP报头),fraglen表示以太网帧报文长度(不包括以太网头),alloclen表示要分配的内容长度,下面代码省略了一些内容。各参数值: fraggap=0, datalen=50, fraglen=70, alloclen=70。
fraggap = 0; datalen = length + fraggap; fraglen = datalen + fragheaderlen; alloclen = datalen + fragheaderlen;
分配报文skb空间,大小为alloclen+hh_len+15,alloclen + hh_len就是报文的长度,15个字节为预留部分。
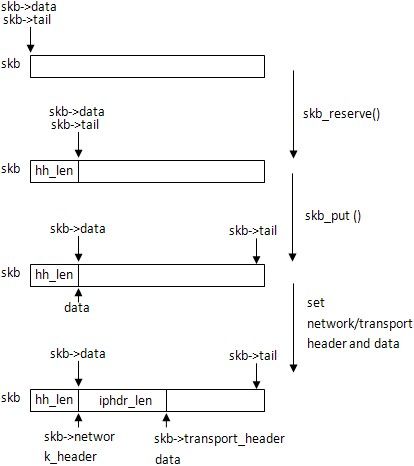
skb_reserve()保留skb头的hh_len大小,skb_put()扩展skb大小到fraglen,然后设置network_header和transport_header指向skb的正确位置,data指向ICMP报头的位置,具体可以看下面的图示:
skb_reserve(skb, hh_len); …… data = skb_put(skb, fraglen); skb_set_network_header(skb, exthdrlen); skb->transport_header = (skb->network_header + fragheaderlen); data += fragheaderlen;
copy是要拷贝的长度,为传输层报头后的内容大小。getfrag()函数实现数据的拷贝,在icmp模块中,getfrag()指向icmp_glue_bits()函数,它从[from] + offset处拷贝copy个字节到data + transhdrlen处。
偏移offset加上已经拷贝的字节数copy,fraggap=0,length减去的就是IP报文内容长度,由于报文才56字节,一个分片足够,所以length=0,然后把新生成的skb放入sk->sk_write_queue中,然后执行下次while循环。各参数值:copy=42, offset=42, length=0, 更新transhdrlen=0。
offset += copy; length -= datalen - fraggap; transhdrlen = 0; …… __skb_queue_tail(&sk->sk_write_queue, skb); continue;
while循环判断条件是length > 0,因此跳出循环,完成了向IP层发送的数据生成,结果如下,注意,ICMP报头还是没有填写的:

example 2:600 Byte echo 报文[假设MTU=520]
同样,开始时sk->sk_write_queue()为空,初始的设置与上述例子完全相同,不同处在于datalen此时比最大分片还要大,因此要设置datalen=maxfraglen-fragheaderlen。
if (datalen > mtu - fragheaderlen) datalen = maxfraglen - fragheaderlen;
在完全第一个分片后,同样会将分片skb放入sk_write_queue队列,并进入下一次while循环。此时各参数的值:datalen=496, fraglen=516, alloclen=516, skb->len=516,
copy=488, offset=488, length=600-496=104, 更新transhdrlen=0。 __skb_queue_tail(&sk->sk_write_queue, skb); continue;
再次进入while循环,此时不同的是length=104,证明还有数据需要拷贝,此时会对待拷贝的数据进行判断,下面所指的填充满是针对maxfraglen而言的。
@copy > 0,表示上个报文未被填充满,这种情况在多次调用ip_append_data()时会发生,这里都是一次调用ip_append_data()的情况,所以不会出现,此时会填充数据到上个skb中
@copy = 0,表示上个报文被填充满,这个例子现在就是这种情况,此时会分配新的skb
@copy < 0,表示上个报文多填充了数据,这时因为maxfraglen是mtu8字节对齐后的值,所以maxfraglen范围是[mtu-7, mtu],而在某些特殊情况下,比如上个报文已被填满(实际还可能有[1, 7]字节的空间),待填充字节数n < 8,这时会把这n个节字补在最后一个报文的尾部。
对这个例子而言,上个skb刚好被填充满,copy=0,此时分配新的skb。
分配新skb的流程与上个skb的分配过程相同,变化的只是偏移量offset,另外,icmp报头只存在于第一个分片中,因为它也属于IP内容的一部分,在这次拷贝完成后length=0,函数返回,最后结果如下:

ip_push_pending_frames() 将待发送的报文传递给网络层
待发送的报文分片都在sk->sk_write_queue上,这里要做的就是从sk_write_queue上取出所有分片,合并成一个报文,添加IP报头信息,使用ip_local_out()传递给网络层处理。
要注意的是这里的合并并不是真正的合并,只有第一个分片形成了skb,剩下的分片都放到了skb_shinfo(skb)->frag_list上,虽然最后向下传递的只是一个skb,并实际上分片工作已经完成了,网络层并不需要再次分片,由网络的上层完成分片是出于效率的考虑,虽然与协议标准有所出入。
首先从sk_write_queue上取出第一个分片,skb是最终向下传递的报文,tail_skb指向skb的frag_list链表尾,即最后一个分片。
if ((skb = __skb_dequeue(&sk->sk_write_queue)) == NULL) goto out; tail_skb = &(skb_shinfo(skb)->frag_list);
将skb->data指向ip报头的位置
tmp_skb表示现在要插入skb的分片,首先通过__skb_pull()除去这些分片的IP报头,因为分片共用skb的IP报头。然后通过tail_skb处理将tmp_skb链入frag_list中;最后增加报文长度计数,以前说明过,skb->len代表linear buffer + paged buffer,skb->data_len代表paged_buffer,这里插入的分片是增加了paged buffer大小,所以对skb->len和skb->data_len都增加分片的长度。
这里是生成skb的IP报头,设置其中的值
最终通过ip_local_out()传递给IP层