Viola人脸检测方法是一种基于积分图、 级联检测器和AdaBoost 算法的方法,方法框架可以分为以下三大部分:
第一部分,使用Harr-like特征表示人脸,使用“ 积分图”实现特征数值的快速计算;
第二部分, 使用Adaboost算法挑选出一些最能代表人脸的矩形特征( 弱分类器),按照加权投票的方式将弱分类器构造为一个强分类器;
第三部分, 将训练得到的若干强分类器串联组成一个级联结构的层叠分类器,级联结构能有效地提高分类器的检测速度。
Adaboost 算法是一种用来分类的方法,它的基本原理就是“三个臭皮匠,顶个诸葛亮”。它把一些比较弱的分类方法合在一起,组合出新的很强的分类方法。
例如下图中

需要用一些线段把红色的球与深蓝色的球分开,然而如果仅仅画一条线的话,是分不开的。
 |
 |
 |
 |
|
a
|
b
|
c
|
d
|
使用Adaboost算法来进行划分的话,先画出一条错误率最小的线段如图 1 ,但是左下脚的深蓝色球被错误划分到红色区域,因此加重被错误球的权重,再下一次划分时,将更加考虑那些权重大的球,如 c 所示,最终得到了一个准确的划分,如下图所示。

人脸检测的目的就是从图片中找出所有包含人脸的子窗口,将人脸的子窗口与非人脸的子窗口分开。
大致步骤如下:
(1)在一个 20*20 的图片提取一些简单的特征(称为Harr特征),如下图所示。
它的计算方法就是将白色区域内的像素和减去黑色区域,因此在人脸与非人脸图片的相同位置上,值的大小是不一样的,这些特征可以用来区分人脸和分人脸。

(2)目前的方法是使用数千张切割好的人脸图片,和上万张背景图片作为训练样本。训练图片一般归一化到 20*20 的大小。在这样大小的图片中,可供使用的 haar 特征数在 1 万个左右,然后通过机器学习算法 —adaboost 算法挑选数千个有效的 haar 特征来组成人脸检测器。

(3)学习算法训练出一个人脸检测器后,便可以在各个场合使用了。使用时,将图像按比例依次缩放,然后在缩放后的图片的 20*20 的子窗口依次判别是人脸还是非人脸。
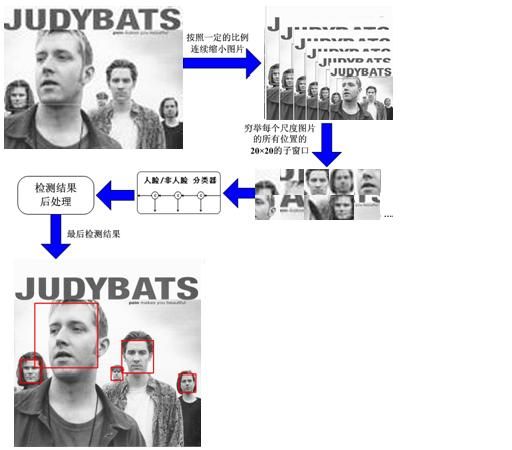
人脸检测的流程
人脸检测在实际中主要用于人脸识别的预处理,即在图像中准确标定出人脸的位置和大小。
目前人脸检测技术在门禁系统、智能监控系统中已得到了很好的应用。另外,目前的笔记本电脑中也陆续开始使用人脸识别技术作为计算机登录的凭证。近年来,在数码相机和手机中也集成了人脸检测算法,作为一个新的功能提供用户使用。在这些应用中,人脸检测都是发挥着至关重要的作用