基于HTK的连续语音识别系统搭建学习笔记(四)
3.创建绑定状态的三音素HMM模型
目的是加入上下文依赖(context-dependent)三音素模型并得到稳健的训练。包括两步,先由单音素得到三音素并重估参数,第二步就是绑定三音素的状态以使输出更加稳健。
[step 9]得到三音素HMM
上下文依赖三音素模型可以用单音素作为初始,再进行重估。由于重估时要三音素级标注文本,就先生成标注文本。
创建文件:mktri.led
创建位置:根目录
文件内容:
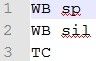
生成文件:wintri.mlf(由单音素标注文本文件aligned.mlf 转换成的等价三音素标注文本)triphones1(一个三音素的列表)
生成位置:lists labels
执行:
HLEd -n .\lists\triphones1 -l * -i .\labels\wintri.mlf mktri.led .\labels\aligned.mlf
下面利用HMM 编辑器初始化三音素模型。
执行:
perl .\scripts\maketrihed .\lists\monophones1 .\lists\triphones1
生成文件:mktri.hed
生成位置:根目录
注:修改mktri.hed 文件,把第一行的.\lists\triphones1 改成./lists/triphones1
执行:
HHEd -H .\hmms\hmm9\macros -H .\hmms\hmm9\hmmdefs -M .\hmms\hmm10 mktri.hed .\lists\monophones1
运行HHEd 得到如下警告,没有大碍的:
重估两次:
HERest -C .\config\config1 -I .\labels\wintri.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm10\macros -H .\hmms\hmm10\hmmdefs -M .\hmms\hmm11 .\lists\triphones1
HERest -C .\config\config1 -I .\labels\wintri.mlf -t 250.0 150.0 1000.0 -s stats -S train.scp -H .\hmms\hmm11\macros -H .\hmms\hmm11\hmmdefs -M .\hmms\hmm12 .\lists\triphones1
两次均会有如下警告,不用理会:
试着执行一下识别任务,看看如何:
HVite -H .\hmms\hmm12\macros -H .\hmms\hmm12\hmmdefs -S test.scp -l * -i recout_step9.mlf -w wdnet -p 0.0 -s 5.0 .\dict\dict2 .\lists\triphones1
这时会报错:
![]()
通过分析将dict2中SUE的第二种发音注释掉就可以了
再运行:
新错误:
然后分析之后把FOUR的第二种发音注释掉
将dict2改成dict4
执行:
HVite -H .\hmms\hmm12\macros -H .\hmms\hmm12\hmmdefs -S test.scp -l * -i .\results\recout_step9.mlf -w wdnet -p 0.0 -s 5.0 .\dict\dict4 .\lists\triphones1
进行识别验证:
执行:
HResults -I .\labels\testwords.mlf .\lists\monophones1 .\results\recout_step9.mlf
所得结果如下:

可以看出,基于三音素的HMM 比基于单音素的 HMM 有较大的性能提升。
我们进一步进行讨论dict4 的由来。由于在 step 8 中对标记文本和语音数据进行了校准,对于象FOUR ,SUE 这样有多个发音的单词,在 Vitebi 算法的作用下,会选择最大化似然率的单词,而不是象step 4 那样选择第一种读音。结果使 dict2 中的发音在扩展成三音素时在音素级真值文本中没有实例,当然也就找不到该三音素的 HMM 模型。这时会报错。根据这个原理,可以编一个Perl 脚本自动对字典中没用到的单词注释掉。我把这个脚本命名为
makedict.pl,包含在 scripts 文件夹里。它可以代替上面的手工注释工作,使用下面的命令可以得到dict4:
perl .\scripts\makedict.pl .\dict\dict2 .\dict\dict4 .\lists\triphones1
[step 10]绑定三音素
在上一步估计模型时,因数据不足导致很多分布的方差只好用截至方差vFloors。这一步就是通过绑定状态来共享数据,使输出分布更加的稳健。HHEd 提供两种聚类状态的机制,这里采用的是决策树:
执行:
perl .\scripts\mkclscript.prl TB350.0 .\lists\monophones0>tree.hed
生成tree.hed文件,内容如下:
还要往tree.hed 中插入问题集(在HTK DEMO里面有参考qusts.hed(在HTKDEMO里)和 trace 等信息。最终形式如下:

在tree.hed 中,tiedlist 是绑定后的不同三音素列表。fulllist 是输入参数,代表绑定前的
所有三音素列表,所以要事先制作。HTK book的制作方法:
HDMan -b sp -n .\lists\fulllist -g global2.ded -l flog .\dict\beep-tri .\dict\beep
其中,文件global2.ded 是在 global.ded基础上加入了TC命令:
执行:
HHEd -H .\hmms\hmm12\macros -H .\hmms\hmm12\hmmdefs -M .\hmms\hmm13 tree.hed .\lists\triphones1 > log
HDMan这里所做的工作包括 1 )按照global.ded的配置把 beep 字典中的发音扩展成(词内)三音素形式,保存到beep-tri字典;2)提取beep-tri中出现的所有不同三音素保存到 fulllist列表中。但是你会发现,按照上述方式制作的fulllist 在执行 HHEd 时会引发错误:
解决办法:
对dict2 进行修改,另存为 dict5,其中去掉了下述两项:
SENT-END [] sil
SENT-START [] sil
执行HDMan生成fulllist :
HDMan -b sp -n .\lists\fulllist -g global3.ded -l flog .\dict\dict5-tri .\dict\dict5
上面的global3.ded 是在 global2.ded 基础上去掉了 AS sp一行,因为 dict5 中的每一单词
发音后已经存在sp 了。文件 global3.ded 的内容如下:

重新执行一遍则不会报错。
生成文件:tiedlist log stats
重估两次:
HERest -C .\config\config1 -I .\labels\wintri.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm13\macros -H .\hmms\hmm13\hmmdefs -M .\hmms\hmm14 .\lists\tiedlist
这时候会报错:

解决办法:
在fulllist中加入sil
在重复一遍,这次仅有一个警告:

再重估一次:
HERest -C .\config\config1 -I .\labels\wintri.mlf -t 250.0 150.0 1000.0 -S train.scp -H .\hmms\hmm14\macros -H .\hmms\hmm14\hmmdefs -M .\hmms\hmm15 .\lists\tiedlist
这次的警告与上次相同,没有关系的。
4.识别器评估
[step 11]验证识别结果
用Viterbi 算法进行识别已经在前文多处涉及,执行如下命令:
HVite -C .\config\config1 -H .\hmms\hmm15\macros -H .\hmms\hmm15\hmmdefs -S test.scp -l * -i .\results\recout_step11.mlf -w wdnet -p 0.0 -s 5.0 .\dict\dict4 .\lists\tiedlist
HResults -I .\labels\testwords.mlf .\lists\tiedlist .\results\recout_step11.mlf
所得结果:

以上包括之前的三篇博文就是基于HTK的连续语音识别系统搭建学习笔记!