Linux内存管理(二)
注:本文中提到的ICE为一Android工程,对应Linux内核版本为2.6.29。
2.6 slab分配器
从前面分析可知,内核对内存的管理都是以页为最小单位的,也就是说想从内核申请内存,必须是页的倍数。如果只想申请几十个字节,获取到的也至少是一页,而且这一页的剩余部分别人是不能使用的,因此明显造成浪费。Linux使用slab分配器对从内核获取到的页再次分配,以减少浪费。
slab分配器有三个目标:
I 减少系统分配小块内存时产生的碎片;
II 把经常使用的对象缓存起来,减少分配、初始化及释放对象的时间开销;
III 调整对象以更好的使用硬件高速缓存。
打个比方:slab就是高速列车上搞零售的列车员。从厂家整批货物,然后搬到列车上分拆成单件由乘客挑选购买。这里的关键是高速列车,对应我们的高速缓存(cache),而批进的货物即是通过页框分配器获取的大块内存,单件就是被slab拆分初始化后的对象(小段内存),而对象才是真正供给开发者(乘客)使用的。不同的是它是免费的,但注意这里是文明的世界,你不可以抢的。slab为了实现上面目标,做了如下操作:
I 获取一块内存;
II 科学划分成大小为2n或某个结构体长度的小块(称为对象);
III 将初始化好的slab放入高速缓存;
IV 利用slab着色及对象对齐提高访问速度。
slab与高速缓存密不可分,下面先来看看它们的描述符:
高速缓存描述符结构为kmem_cache。
| 类型 |
名字 |
说明 |
| struct array_cache * [] |
array |
每CPU指针数组,指向包含空闲对象的本地高速缓存 |
| unsigned int |
batchcount |
要移进/移出本地高速缓存的大批对象的数量 |
| unsigned int |
limit |
本地高速缓存中空闲对象的最大数目。可调 |
| unsigned int |
buffer_size |
单个对象的大小,即kmem_cache_alloc()每次可获得的内存的大小 |
| unsigned int |
reciprocal_buffer_size |
buffer_size的倒数,系统中没有使用该变量 |
| unsigned int |
flags |
描述高速缓存永久属性的一组标志 |
| unsigned int |
num |
封装在一个单独slab中的对象个数 |
| unsigned int |
gfporder |
一个单独slab中包含的连续页框数目的对数 |
| gfp_t |
gfpflags |
分配页框时传递给伙伴系统函数的一组标志 |
| size_t |
colour |
slab使用的颜色个数 |
| unsigned int |
colour_off |
slab中的基本对齐偏移 |
| struct kmem_cache * |
slabp_cache |
指向包含slab描述符的普通slab高速缓存,如果使用内部slab描述符,该字段为NULL |
| unsigned int |
slab_size |
单个slab的大小 |
| unsigned int |
dflags |
描述高速缓存动态属性的一组标志 |
| void (*ctor)(void *obj) |
ctor |
指向与高速缓存相关的构造/析构方法 |
| const char * |
name |
指向高速缓存的名字 |
| struct list_head |
next |
高速缓存描述符双向链表使用的指针 |
| struct kmem_list3 *[] |
nodelists |
每个节点上属于该高速缓存的所有slab链表,请看下表 |
表2-5:高速缓存描述符
kmem_list3结构。
| 类型 |
名字 |
说明 |
| struct list_head |
slabs_partial |
包含空闲和非空闲对象的slab描述符双向循环链表 |
| struct list_head |
slabs_full |
不包含空闲对象的slab描述符双向循环链表 |
| struct list_head |
slabs_free |
只包含空闲对象的slab描述符双向循环链表 |
| unsigned long |
free_objects |
高速缓存中空闲对象的个数 |
| spinlock_t |
list_lock |
本结构使用的自旋锁 |
| struct array_cache * |
shared |
指向所有CPU共享的一个本地高速缓存的指针 |
| unsigned long |
next_reap |
由slab分配器的页回收算法使用 |
| int |
free_touched |
由slab分配器的页回收算法使用 |
表2-6:kmem_list3结构
slab描述结构为struct slab。
| 类型 |
名字 |
说明 |
| struct list_head |
list |
slab描述符的三个双向循环链表中的一个(在高速缓存描述符的kmem_list3结构中的slabs_full、slabs_partial或slabs_free链表)使用的指针 |
| struct list_head |
colouroff |
slab中第一个对象的偏移 |
| void * |
s_mem |
slab中的第一个对象的地址 |
| unsigned int |
inuse |
当前正在使用的slab中的对象个数 |
| kmem_bufctl_t |
free |
slab中下一个空闲对象的下标 |
| unsigned short |
nodeid |
本slab所属节点的ID号 |
表2-7:slab描述符
下图(来自于《Linux虚拟内存管理》)展示了高速缓存与slab关系:
图2-4:高速缓存、slab及对象关系图
高速缓存分通用和专用,所谓通用就是系统初始化时实现准备了一组常用大小的内存对象组供内核开发者使用,比如使用kmalloc()获取。下图为ICE平台上使用的通用高速缓存。
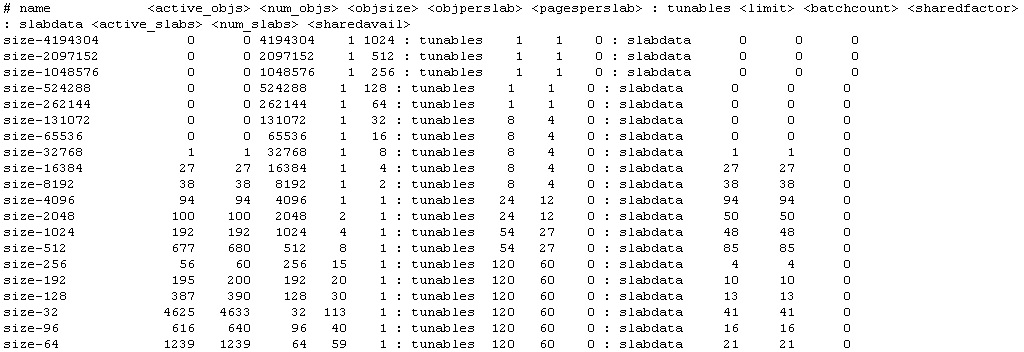
图2-5:ICE平台的通用高速缓存
专用高速缓存是指专为一个结构体创建的高速缓存。比如文件的inode结构,用的很多,但其大小在通用高速缓存中找不到,如果强行从通用高速缓存中申请空间势必会造成内存浪费。因此,系统专门为其创建一个专用高速缓存,使得对应对象的大小就是inode结构的大小(需要4字节对齐)。下图为ICE平台上使用的专用高速缓存。
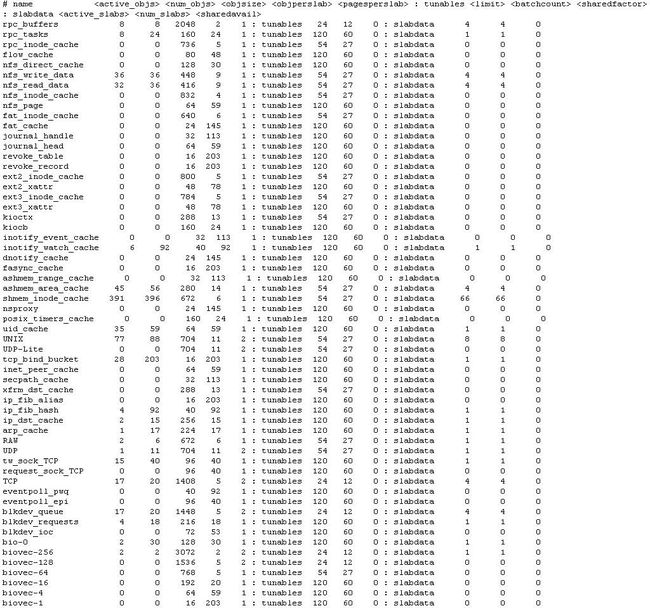
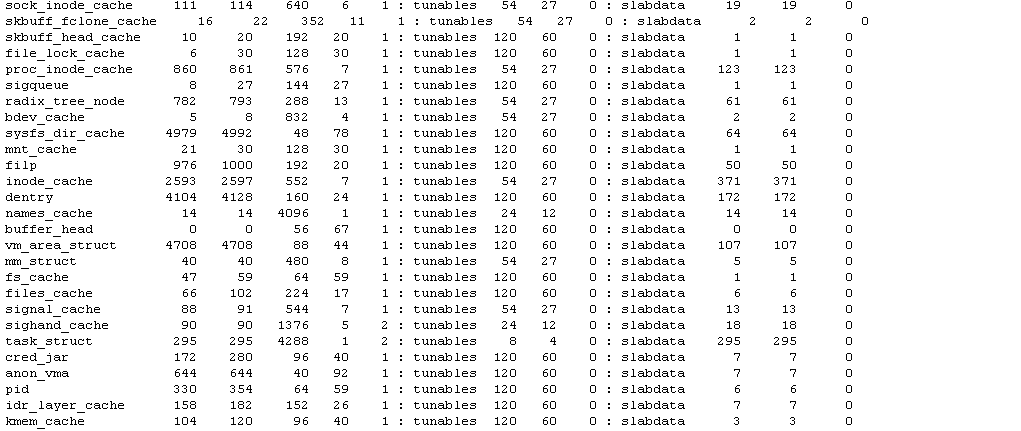
图2-6:ICE平台的专用高速缓存
无论是通用还是专用高速缓存都是通过kmem_cache_create()函数创建的。它们的区别是:通用是在系统初始化时(start_kernel()->kmem_cache_init())系统创建的,而专用则是由内核开发者根据需要创建的。这个函数只是获取一个高速缓存描述符并将其插入到高速环存链表中,如图2-4。
一个新创建的高速缓存没有包含任何slab,因此也没有空闲的对象。只有当以下两个条件都为真时,才给高速缓存分配slab:
I 已发出一个分配新对象的请求,即调用kmem_cache_alloc()请求对象;
II 高速缓存不包含任何空闲对象。
当上述两个条件都满足时,slab分配器调用cache_grow()函数来增加一个slab。这个函数又调用kmem_getpages()从页框分配器获得一组页框(由高速缓存描述符中的gfporder确定为2 gfporder个页框)。接着cache_grow()调用cache_init_objs(),将前一组页框分成n个对象(大小有高速缓存描述符中的obj_size指定),再调用描述符中的构造函数(由kmem_cache_create()指定)对各个对象进行初始化。然后将初始化好的slab插入到空闲slab链表中(slabs_free链表)。
2.7 kmalloc
如果slab分配器、伙伴系统算法弄明白了,kmalloc()就不用讲,它几乎完全等同于kmem_cache_alloc(),不同的是kmalloc()有自己选择通用高速缓存的机制,而后者需要申请者指定高速缓存。看下代码就全明白了:
第33行__builtin_constant_p(size)是gcc的内部函数,意思是说如果size是常量函数就返回true,否则返回false。但David Howells他们说了,该函数在kmalloc里恒为真,可参考android/kernel目录下的aa(内核开发者修改提交记录)文件:

图2-7:内核开发者提交记录片段
通过增加打印证明kmalloc()函数中无论是变量还是常量__builtin_constant_p()返回的值均为1。
39~46行的目的即是到通用高速缓存表中查找符合size的高速缓存,来看一下kmalloc_sizes.h,全部内容如下:

如果找到则调用kmem_cache_alloc()函数到找到的那个高速缓存中的slab链表上找一个未用的对象(内存块的首地址)给申请者,否则换回NULL。
从上面的分析及验证来看,第55行应该不会被调用到。但我们仍然来分析一下,函数体如下:
void *__kmalloc(size_t size, gfp_t flags)
{
return __do_kmalloc(size, flags, NULL);
}
再看__do_kmalloc()函数:
static __always_inline void *__do_kmalloc(size_t size, gfp_t flags,
void *caller)
{
struct kmem_cache *cachep;
/* If you want to save a few bytes .text space: replace
* __ with kmem_.
* Then kmalloc uses the uninlined functions instead of the inline
* functions.
*/
cachep = __find_general_cachep(size, flags);
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return cachep;
return __cache_alloc(cachep, flags, caller);
}
可以看出仍然是调用__find_general_cachep()从通用高速缓存总找到相应大小的高速缓存,然后再调用__cache_alloc()(事实上kmem_cache_alloc()中只有一行,就是调用__cache_alloc())从slab中找一个空闲对象(内存块的首地址)返回给申请者。
2.8 vmalloc
伙伴系统算法一节中讲到减少内存碎片的两种办法:一种是用伙伴系统有效管理内存;二是将不连续的内存映射到连续的线性地址,vmalloc()就是这种方法的实现。
vmalloc()映射到的连续线性地址不是随意的,内核专门为其划了一块空间,位于物理内存映射末端偏移8M的地方。请见图1-1,范围为0x9D800000~0xE0000000,请参考内核中VMALLOC_START及VMALLOC_END定义。也就是说映射在内核空间,用户态的程序是不能访问的,要访问得进入内核态。
来看一下该过程中的关键数据结构vm_struct,下表为其参数描述:
| 类型 |
名字 |
说明 |
| struct vm_struct * |
next |
指向下一个vm_struct结构的指针 |
| void * |
addr |
内存区内第一个内存单元的线性地址 |
| unsigned long |
size |
内存区的大小加上4096(一页的安全区,为了防止越界访问) |
| unsigned long |
flags |
映射的内存的类型,如:VM_ALLOC表示使用vmalloc()得到的页,VM_MAP表示使用vmap()映射的已经被分配的页,而VM_IOREMAP表示使用ioremap()映射的硬件设备的板上内存 |
| struct page ** |
pages |
该指针数组每个元素指向一个可获得的页描述符 |
| unsigned int |
nr_pages |
内存区填充的页的个数 |
| unsigned long |
phys_addr |
该字段一般不用,除非内存被创建来映射一个硬件设备的I/O共享内存 |
| void * |
caller |
指向该内存区的使用者 |
表2-8:不连续内存描述符
下面是vmalloc()源码:
void *vmalloc(unsigned long size)
{
return __vmalloc_node(size, GFP_KERNEL | __GFP_HIGHMEM, PAGE_KERNEL,
-1, __builtin_return_address(0));
}
再来看__vmalloc_node(),
static void *__vmalloc_node(unsigned long size, gfp_t gfp_mask, pgprot_t prot,
int node, void *caller)
{
struct vm_struct *area;
size = PAGE_ALIGN(size);
if (!size || (size >> PAGE_SHIFT) > num_physpages)
return NULL;
area = __get_vm_area_node(size, VM_ALLOC, VMALLOC_START, VMALLOC_END,
node, gfp_mask, caller);
if (!area)
return NULL;
return __vmalloc_area_node(area, gfp_mask, prot, node, caller);
}
该函数表明不可以传入一个比物理内存还大的size。接着调用__get_vm_area_node()获取一段连续的线性地址,并申请一个不连续内存区描述符,即vm_struct数据块,并初始化。__vmalloc_area_node()实现的是申请不连续内存,并将其映射到前面获取到的连续线性地址上。请看源码:
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node, void *caller)
{
struct page **pages;
unsigned int nr_pages, array_size, i;
nr_pages = (area->size - PAGE_SIZE) >> PAGE_SHIFT;
array_size = (nr_pages * sizeof(struct page *));
area->nr_pages = nr_pages;
/* Please note that the recursion is strictly bounded. */
if (array_size > PAGE_SIZE) {
pages = __vmalloc_node(array_size, gfp_mask | __GFP_ZERO,
PAGE_KERNEL, node, caller);
area->flags |= VM_VPAGES;
} else {
pages = kmalloc_node(array_size,
(gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO,
node);
}
area->pages = pages;
area->caller = caller;
if (!area->pages) {
remove_vm_area(area->addr);
kfree(area);
return NULL;
}
for (i = 0; i < area->nr_pages; i++) {
struct page *page;
if (node < 0)
page = alloc_page(gfp_mask);
else
page = alloc_pages_node(node, gfp_mask, 0);
if (unlikely(!page)) {
/* Successfully allocated i pages, free them in __vunmap() */
area->nr_pages = i;
goto fail;
}
area->pages[i] = page;
}
if (map_vm_area(area, prot, &pages))
goto fail;
return area->addr;
fail:
vfree(area->addr);
return NULL;
}
代码有点长,但确实很简单。先是申请一块空间用来保存不连续内存区描述中的pages数组;接着一页一页(这是至关重要的)的申请内存,并将申请到的内存的页描述符存放到pages数组中;最后调用map_vm_area()将pages中的各页映射到连续线性地址上。最后一步是难点,从代码中可知,其原理就是申请新的目录项和页表项,并通过线性地址段、页描述符里的信息重新设置它们。由于还不太了解arm硬件的这一块,此处代码略过。