<深入浅出> linux内核 RCU (二)分级RCU
在前一篇文章里,分析过经典RCU的来历和实现:
http://blog.csdn.net/chenyu105/article/details/7910269
经典RCU看完后,作为读者的你,有没有发觉经典RCU有一些瓶颈?(不管你发现没有,反正我是没有意识到,不过在网上文章的提示下,感受到了)
虽然RCU号称无锁,但是每个CPU在经历了一次queis stat后,都需要操作一个全局的cpumask,把自己的那一位从掩码中去掉。
如果cpu少,还好说,在超级计算机里,cpu个数成千上万,这个性能就非常低下了。
这就引入了数据结构与算法里的分而治之的思想。
中心思想就是类似淘汰赛。把这些cpu,分成多个组,每个组给一个cpumask,组内的cpu只对所属组的cpumask进行竞争,
优胜者再进行组与组之间的mask进行竞争。不过和淘汰赛有点不同,每个组内选出代表的时候,
需要其他cpu都将自己的标志位置0,也就是说,谁最后一个修改cpumask,谁就是优胜者,进入下一轮组间竞争。
这样可以降低锁的粒度。这个就是分级RCU(tree rcu)的设计思路。
从上面的介绍可以推测出,为了引入组的概念,应需要一个rcu_node的结构,该结构可能类似于:
struct rcu_node {
unsigned long qsmask;
struct rcu_node *parent;
}其中,qsmask就是组的cpumask掩码,parent用来指向父节点组,也就是下一轮竞争所在的组。
以rcu作者提出的例子,http://lwn.net/Articles/305782/
假设系统中有6个cpu,假设cpu0、cpu1属于一个组,cpu2、cpu3同属一组,cpu4、cpu5同属一组
假设某个时刻,6个cpu同时告诉RCU,都经过了queis stat,那么每组内只有一个cpu能清空组内的cpumask对应该cpu的bit位,
待该组的cpumask被最后一个cpu清0后,再转移到父节点组,继续尝试置0。
下图是一个场景,如果CPU 0、3、5比较幸运,则第二图显示了其结果,标识为绿色块。
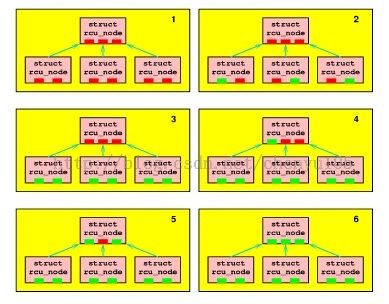
一旦这些幸运的CPU完成了,那么其他CPU将获得锁,如图3所示(CPU1、2、4)。
这些CPU将会发现它们是组内最后一个CPU,因此所有3个CPU尝试移到上层rcu_node。
仅仅其中一个能获得上层rcu_node 锁。从图4开始,假设CPU 1、4、2依次获得了锁,
第4、5、6图显示了相应的状态。最后第6图显示了所有CPUs已经经过一次静止状态,因此grace period 结束。
·讲完tree rcu的设计思想,我们可以看出,实际上他和经典rcu没有本质区别。我们再次提出rcu的主题:
当写者被挂起后,
1)重置每cpu变量,值为1。
2)当某个cpu经历一次进程切换后,就将自己的变量设为0。
3)当所有的cpu变量都为0后,就可以唤醒写者了。
我们看看tree rcu具体是如何实现这个逻辑的。之前说过,标准RCU里有一个全局的结构,rcu_ctrlblk,
其成员cur,completed用来指示全局的rcu周期,一般情况下,complete追着curr走,
当相等的时候,说明一次rcugrace period结束了。在tree rcu里,rcu_ctrlblk演变成了rcu_state:
struct rcu_state {
struct rcu_node node[NUM_RCU_NODES];
unsigned long gpnum;
unsigned long completed;
}也就是说,curr换成了gpnum,complete不变,多了一个rcu_node,就是上面提到的cpu组。
其实具体分成多少个组,是可以调整NUM_RCU_NODES来得到的,这个可以通过内核的CONFIG_RCU_FANOUT来调节,具体算法就不关心了。
这3个结构体的包含关系是:rcu_state>rcu_node>rcu_data,说白了,分级RCU就是在全局rcu和每cpu的rcu之间插了一个分组的概念。
虽然RCU的作者拼命的想把RCU搞的高大上,还堆砌了一大堆编程技巧,但万变不离其宗,我们要学会从繁复的内核实现中,抽取作者的中心思想。
有了之前分析经典RCU的方法,我们来模拟一下RCU的流程,特别是这几个gpnum、 completed变量的变化是考察重点:
1. 写者被加入到等待队列nxtlist,来了时钟硬中断,rcu_check_callbacks里会检查当前
CPU的nxttail是否为空,每cpu的参数对应数据结构struct rcu_data rdp,rdp->nxttail[RCU_NEXT_READY_TAIL]不为空的话则唤醒RCU软中断;
2. RCU软中断进入rcu_process_callbacks,再次确认nxttail[RCU_NEXT_READY_TAIL]有东西,于是就新开启一个grace period等待周期,rcu_start_gp即把全局的rsp(rcu state pointer)->gpnum加1。不过,这里有个小改动,所有涉及到全局rcu_state的操作,都放在了一个内核线程里完成->通过schedule_work将唤醒工作交给keventd,再由kevend唤醒rcu_gp_kthread内核线程。看到这里,你觉得这么搞有什么好处?为什么不直接要放到内核线程去完成?为什么要由keventd来唤醒?把全局rcu_state的操作,放到一个内核线程,好处是简化了rcu软中断处理的逻辑,你也看到了,之前的经典RCU,在软中断里维护各个变量时,逻辑是多么的复杂。至于为什么先唤醒keventd,再由keventd去唤醒rcu_gp_kthread,大概是因为,系统首先要保证keventd完成各种关键(如tty),而不应该让rcu_gp_kthread过多的占用资源;
3.rcu_gp_kthread被唤醒后,发现是要求新开一个grace period的请求,就调用rcu_gp_init,将当前rcu的时间戳前推,rsp->gpnum++; 还没完,接着,还要把所有rsp里的节点,cpu掩码初始化为全置1,即rnp->qsmask = rnp->qsmaskinit(注意,是所有rcu_node,不止是叶节点); 接着,再把节点的其他字段,与rsp同步, rnp->gpnum = rsp->gpnum,rnp->completed = rsp->completed;
4. 第3步rcu_process_callbacks结束后,本次软中断就结束了。下次再来软中断,系统又来到rcu_process_callbacks,开始检测本次grace period是否结束,这个是由rcu_check_quiescent_state函数完成。该函数和经典RCU一样,都是核心的RCU判断处理逻辑。首先,当check_for_new_grace_period发现rdp与rnp不同步了(rdp->gpnum != rsp->gpnum),则说明已经开启了一个新的grace period,则需要把本cpu的进程切换标志置0,即rdp->passed_quiesce = 0;等待经历一次进程切换。 并更新本cpu的grace period时戳,rdp->gpnum = rnp->gpnum; 这一点和经典RCU的3.2节是一个道理;
5.第4步rcu_process_callbacks到此再次结束,下一次软中断又进来后,还是会进到rcu_check_quiescent_state,
这次就不是检查是不是新开了一个grace period了,而是检查是否该cpu经历另一个进程切换,如果经历了的话,将会调用rcu_report_qs_rdp层层上报。这点就是与经典RCU的不同之处。经典RCU会置当前全局cpumask相应位为0后,看是否所有cpu都经历了一次进程切换,即满足rdp->passed_quiesce为1,是的话就调用后面的rcu回调。而分级rcu则是个树形上报的过程,如果是你,会如何实现rcu_report_qs_rdp呢?请读者思考1分钟,再继续看下一步的说明;
6.rcu_report_qs_rdp,软中断进到这个函数,就说明该cpu已经历了一次进程切换。我们推断这个函数要操作的对象应该就是本cpu所在的节点rcu_data,确切的讲,就是rcu_data.qsmask。当本节点的qsmask为0后,需要上报给父节点,上报的方式是把父节点rcu_node里的qsmask的某个bit位置0,具体是哪个bit,用rcu_data.grpmask来表示,且后者是系统初始化时就赋值了,不会再变化。从这两个mask都是unsigned long可以看出,分组的最大cpu个数是系统字长。另外既然是多个cpu可能操作同一个rcu_data里的qsmask,那么就应该有一把小粒度的锁,因此结构应该是:
struct rcu_node {
unsigned long qsmask;
unsigned long grpmask;
struct rcu_node *parent;
spinlock_t lock;
}按照前面的图示,我们来自己写一下rcu_report_qs_rdp函数。
既然该函数负责层层上报,很明显,实现可以是个循环,或者是个递归。
void
rcu_report_qs_rdp(struct rcu_data *rdp)
{
struct rcu_node *rnp= rdp->mynode;
struct rcu_node *rnp_parent= rnp;
unsigned long mask = rdp->grpmask;
for(;;) {
spinlock(&rnp_parent->lock);
rnp_parent->qsmask & = ~mask;
if(rnp_parent->qsmask) { /*some cpus in this node didn't pass a ques state*/
spin_unlock(&rnp_parent->lock);
return;
}
spin_unlock(&rnp_parent->lock);
rnp_parent = rnp_parent->parent;
}
wakeup(rcu_gp_kthread);
}如果循环到根节点,说明所有的cpu都经历了一次quies state,也就是系统经历了一次grace period,
就需要把全局的grace period完成时戳更新为当前运行grace period,也就是rcu_gp_kthread线程里做的事,rsp->completed = rsp->gpnum,
同时遍历所有的rcu_node节点,将node节点的complete时戳推进,即
rnp->completed = rsp->gpnum
7. 假如rcu_gp_kthread线程得到了及时调度,下一次软中断再次来到,进入__rcu_process_callbacks后,通过
rcu_process_gp_end(rsp, rdp);检查是否rsp表示的grace period周期已经领先于当前CPU的周期,即 rnp->completed是否 大于 rdp->completed。
我们说过,rcu_gp_kthread已经更新了rnp的completed字段,因此将nxtlist指针推进,把rdp->nxttail[RCU_DONE_TAIL]填充上回调,
并让rdp的completed追上rnp,rdp->completed = rnp->completed;最后返回到__rcu_process_callbacks后,
发现rdp->nxttail[RCU_DONE_TAIL] 不为空,因此去调用本cpu上的回调函数。
注意,在高版本里,如3.10,这个回调其实并不在软中断里完成,而是去唤醒了一个专门的线程调用rcu_do_batch来做。
补充一下,tree rcu里的批处理队列合并为了一个,由各指针指示:
nxtlist保存的是指向rcu_head对象,rcu_head的定义如下:
struct callback_head {
struct callback_head *next;
void (*func)(struct callback_head *head);
};
#define rcu_head callback_head
rcu_head的结构并不复杂,它包含一个回调函数指针。而next可以把rcu_head连成一个列表。
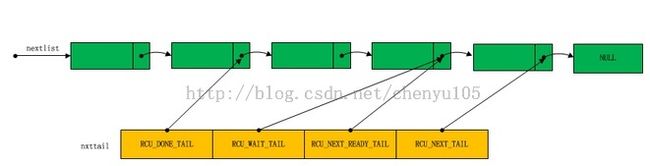
。RCU_DONE_TAIL指向的rcu_head对象之前的对象是可以销毁的对象。
RCU_WAIT_TAIL指向的正在等待宽限期的元素,RCU_NEXT_READ_TAIL指向的是等待下次宽限期的元素,
RCU_NEXT_TAIL指向最后一个元素,这个元素总是指向NULL。
分级RCU的流程大概分析清楚了,我们来分析几个内核配置选项:
CONFIG_NO_HZ:
如果系统配置了CONFIG_NO_HZ,那么某些空闲的cpu将会处于休眠状态,没有中断也没有切换,
减少了能源消耗。那么一次grace period怎么才能结束?
经典RCU是这么做的:当cpu A进入时钟中断rcu检测流程后,会检查是否grace period的检测时间超时,
如果超时,则会向其他所有cpu,发送一次resched ipi强制调度。
但这就带来一个问题,处于休眠状态的cpu B被ipi唤醒,会有大量状态切换的能源消耗。
于是RCU做了改进,cpu A监控其他cpu是否长时间没有经过静止状态,如果发现cpu B超时的话,
cpu A就检查cpu B是否是处于no hz状态下的休眠,如果cpu B确实是休眠,就给cpu B设置一个扩展静止状态,
表示经历了一次静止状态,从而cpu A能成功完成一次grace period的判断。这样就不用再给cpu B发送ipi唤醒了。
这些设置idle状态下的cpu,叫做dyntick-idle mode。
超时检测的代码在:
/* If time for quiescent-state forcing, do it. */
if (ret == 0 || (rsp->gp_flags & RCU_GP_FLAG_FQS)) {
fqs_state = rcu_gp_fqs(rsp, fqs_state);
cond_resched();根据RCU_GP_FLAG_FQS的变化可以知道,rsp只有一次机会可以检查其他cpu的运行状态
检查的核心是看rsp内所有rdp的rdp->dynticks->dynticks字段,如果加1后是偶数则属于扩展静止,否则奇数
则说明非扩展静止。
atomic_t dynticks; /* Even value for idle, else odd. */
static int dyntick_save_progress_counter(struct rcu_data *rdp)
{
rdp->dynticks_snap = atomic_add_return(0, &rdp->dynticks->dynticks);
return (rdp->dynticks_snap & 0x1) == 0;
}在某些情况下,rdp->dynticks->dynticks会被加1,成为奇数。比如:
1.进用户态
user_enter ->rcu_user_enter ->rcu_eqs_enter ->rcu_eqs_enter_common ->atomic_inc(&rdtp->dynticks);以及,进idle
cpu_idle_loop ->rcu_idle_enter ->rcu_eqs_enter ->rcu_eqs_enter ->rcu_eqs_enter_common ->atomic_inc(&rdtp->dynticks)
CONFIG_NO_HZ_FULL:
很多时候,某些cpu并不处于休眠idle状态,而是一直循环跑一个高优先级线程(如媒体面)。
我们也不想给这些媒体面cpu发送过多的中断(时钟,ipi等),以免影响媒体面性能,这就是CONFIG_NO_HZ_FULL。
原理就和CONFIG_NO_HZ一样,只是条件从判断idle改为判断是否有处于R状态的进程。
在配置CONFIG_NO_HZ_FULL时,rcu如何等待该cpu经历了一次静止状态?
原理一样,超时后如果该cpu上处于R状态的进程只有一个,那么认为已经经历了一次扩展静止状态。
这些媒体面cpu,叫做adaptive-tick mode。
下面是这三种配置的概要说明:
CONFIG_HZ=1000 - No Tickless support - Ticks 1000/sec on every CPU no matter what CONFIG_HZ=1000, CONFIG_NO_HZ=y - Tickless when nr_running = 0 - Ticks 1000/sec when nr_running > 0 CONFIG_HZ=1000, CONFIG_NO_HZ=y, CONFIG_NO_HZ_FULL=y, etc. - Opt-in support for nohz_full - Tickless when nr_running <= 1 - Ticks 1000/s when nr_running > 1
CONFIG_RCU_NOCB_CPU:
如果在dyntick-idle 或者adaptive-tick的cpu上,内核态不小心调用了call_rcu,导致有待处理的rcu回调怎么办?
这样会导致cpu退出adaptive或者idle状态,影响功能。
为了解决这种情况,又引入了CONFIG_RCU_NOCB_CPU选项。
该选项将这些被孤立的cpu上面的rcu回调函数,都弄到专门的内核线程里去完成。
如cpu1就对应着rcuos/1、rcuob/1,这些线程初始掩码是全f,需要用户来手工将其绑定到非孤立cpu上。这样被孤立的cpu,就没有pending的rcu回调了,也就可以进入idle(dyntick-idle)或(adaptive-tick)。
当然,如果这样做了,那么设置为nocb的cpu,其nxtlist链表里也没回调了。因为call_rcu的时候,
设置了nocb的cpu,是把回调放到rdp->nocb_tail里,而不是rdp->nxttail[RCU_NEXT_TAIL] 上,
当达到一定条件后会唤醒该cpu上的rdp->nocb_kthread,即rcu_nocb_kthread,由后者将待处理回调挨个处理。这个一定条件,指的是什么?主要是__call_rcu_nocb_enqueue(struct rcu_head *rhp,struct rcu_head **rhtp),该函数的参数,前一个rhp是要插入的回调元素,后一个rhtp是&rhp->next。该函数就是将rhp插入
到每cpu队列的尾部,即rdp->nocb_tail指向的地方。回调插完了,那什么时候会唤醒该cpu上的回调线程呢?接下来的代码判断本次插入的队列是不是空队列
(即rdp->nocb_head是否等于rdp->nocb_tail)
如果是的话,则说明是第一次挂回调,就唤醒回调线程。
结论:
为了避免媒体面rcu死锁,除了配置CONFIG_NO_HZ_FULL和CONFIG_RCU_NOCB_CPU,以及启动参数
nohz_full和rcu_nocbs,还需要保证rcu回调处理线程,手工绑定到控制面,并且,还要保证rcu状态维护线程rsp,也绑到控制面。