浅谈并行编程语言 Unified Parallel C
胡国威,软件工程师, IBM
简介: 随着多核技术的发展,为了提高硬件的利用率和满足超级计算日益增长的需求,并行编程语言应运而生,UPC就是其中之一。越来越多的程序开发人员面临到并行编程的问题,因此学习一门并行编程语言必要性变得愈发迫切。UPC并行编程语言在国外已经得到重用,但是在国内介绍该语言的材料还比较匮乏。因此,本文通过重点介绍 UPC并行编程语言对 C 语言所进行的扩展,使读者对 UPC 并行编程语言具有初步的认识,有利于读者进一步对 UPC并行编程语言的学习。
发布日期: 2011年 1 月 06日
级别: 初级
访问情况: 21486次浏览
评论: 0 (查看 | 添加评论 -登录)
平均分 (18个评分)
为本文评分
并行编程和 Unified Parallel C语言概述
并行编程介绍
并行编程是通过同步执行计算机指令的方式来取得比串行编程更快速度的一种编程方法。并行编程是相对于传统的串行编程而提出的概念。在串行编程中,一个程序的指令在单一的 CPU上按照先后顺序依次执行,而在并行编程则将一个程序分成独立的若干部分在一个或多个 CPU上进行同步执行以取得更高的运算效率和性能。
根据底层的内存结构,并行编程可以分为以下三种程序设计类型:
- 共享内存模型:多个线程或进程同时运行。它们共享同一内存资源,每个线程或进程都可以访问该内存的任何地方。例如 openMP 就是采用共享内存模型。
- 分布式内存模型:多个独立处理结点同时工作,每个处理结点都有一个本地的私有内存空间。执行程序的进程可以直接访问其私有内存空间。 若一个进程需要访问另一个处理结点处的私有空间,则此进程需要以发送信息给该进程来进行访问。MPI 就是采用分布式内存模型。
- 分布式共享内存模型:整个内存空间被分为共有空间和私有空间。每个线程可以访问所有的共有空间,并且每个线程都有自己独立的私有空间。Unified Parallel C 就是采用分割全局地址空间模型。
Unified Parallel C语言概述
Unified Parallel C (UPC)是基于分布式共享内存程序设计模型,应用于超级计算机上进行高效能计算的并行编程语言。它提取了 AC, Split C, Parallel C Preprocessor这三种并行语言的优点,对 C 语言(ISO C99 标准)进行扩展,增加了一些特性和概念使之既保留了原来 C语言的简洁高效的优点,同时又可以支持并行编程。可以说 , UPC并行编程语言是 C 语言的超集,任何语法正确的 C 语言在 UPC 中都是正确的。
为了支持并行编程,UPC对 C 语言作了以下的扩充:
- 显式并行执行模型
- 共享内存空间
- 同步原语与存储一致性模型
- 内存管理原语
回页首
UPC程序设计模型
UPC是基于图 1 所示的分布式共享内存程序设计模型的并行程序语言。

图 1.分布式共享内存程序设计模型
分布式共享内存程序设计模型将全局的内存空间分为共享内存空间和私有内存空间。共享内存空间又在逻辑上被分为一个个的分区。每一个线程对应着一个共享内存分区,我们称这个线程与其对应的共享内存分区之间的逻辑关系为亲缘关系(affinity)。我们称和某线程具有亲缘关系的共享内存为本地共享内存。每个线程对应着何其具有亲缘关系的共享内存分区和自己独有的私有空间。
每个线程可以访问所有的共享空间和自己的私有内存空间。如图所示,数据 x位于进程 0 所对应的共享空间分区,数据 y位于线程 0 的私有内存空间。线程 0可以访问所有的黄色的共享区间和它自己的私有内存空间。线程 0可以访问数据 y, 却不可访问数据 z, 因为数据 y位于线程 0 的私有内存空间,而数据 z在线程 1 的私有内存空间。线程 1和线程 0 都可以访问数据 x,但是由于线程 0 和数据 x 具有亲缘关系,所以线程 0要比线程 1 访问数据 x速度要快得多。
亲缘关系在 UPC中是一个非常重要的概念。用线程来访问与其具有亲缘关系的数据可以显著地提高程序的效率。
回页首
术语解释
线程:指运行中的程序的调度单位
THREADS: UPC中的关键字。它是一个值为整型的表达式,代表参与目前程序参与执行的线程总数。在每个线程中,THREADS具有相同的值。在静态执行环境中,THREADS是一个整型常量。
MYTHREADS:UPC中的关键字。它是一个值为整型的表达式,代表目前正在执行的某一个线程。
亲缘关系:一个线程与共享数据之间的逻辑关系
私有数据:位于一个线程是私有内存空间的数据,这个数据只能为该线程所访问。
共享数据:位于一个线程的共享内存空间的数据,这个数据可以为所有线程所访问。
共享数组:一个数组其所有的元素均为共享类型
共享指针:一个位于共享内存空间的指针,它可以指向共享数据或者私有数据。
私有指针:一个位于私有内存空间的指针,它可以指向共享数据或者私有数据。
指向共享数据指针:一个指向共享数据的指针,它可以是共享指针,也可以是私有指针。
指向私有数据指针:一个指向私有数据的指针,它可以是共享指针,也可以是私有指针。
指向共享数据私有指针:一个位于私有内存空间,指向共享数据的指针。
指向共享数据共享指针:一个位于共享内存空间,指向私有数据的指针。
指向私有数据私有指针:一个位于私有内存空间,指向私有数据的指针。
指向私有数据共享指针:一个位于共享内存空间,指向共享数据的指针。
回页首
数据与指针
共享和私有数据
UPC将数据分为私有和共享两种类型。UPC对 C 语言扩展了一个新的数据类型限定词 shared.类型限定词 shared声明数据为共享类型。如果数据声明中没有用到 shared数据类型限定词,则所声明的数据位私有数据。可以说在 C语言中的数据类型在 UPC 中都是私有数据类型。
当声明一个共享数据类型的时候,该数据会被分配到共享内存空间中。若该共享数据是标量数据,则该数据会被分配到线程 0的共享内存空间中。若该共享数据为数组,则该数据将根据该数组中的布局限定词来分配到共享内存空间中,关于共享限定词,将在 4.2中详细阐述。若该当你声明一个私有数据类型的时候,该数据会被分配到每一个线程的私有内存空间中。
清单 1.数据声明例子
|
int x; // 声明了一个私有数据类型
shared int y; // 声明了一个共享整型数据
shared int z[11] // 声明了一个共享整型类型数组 , 数组中包含 11个共享整型类型元素
图 2 显示了以上所声明的数据在内存中的视图 |
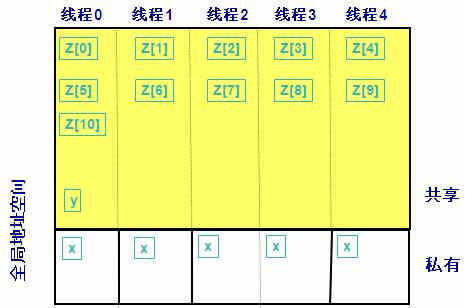
图 2.数据声明内存视图
如图 2所示声明语句“int x;”声明了一个私有整型数据,这个数据被分配到每一个线程的私有空间中。声明语句“shared int y”声明了一个共享整型数据,这个数据被分配到线程 0的共享内存空间中。声明语句“shared int z[11]”声明了一个共享整型数组,该数组的元素如图依次被分配到每一个线程的共享内存空间。
数组
UPC的数组声明引入了一个布局类型限定词。布局类型限定词决定多少个连续的共享元素被分配到同一个线程的共享内存空间中。例如 ,下面的声明了一个共享浮点型的数组 A:
shared [block_size] int A[number_of_elements]
[block_size]是布局类型限定词,block_size是一个非负的数值,代表区块的大小。例如,当布局类型限定词是 [3]时,则每三个连续的元素为一个区块分配到一个线程的共享内存空间中。假若局类型限定词是下列的情形,区块大小有所不同:
- 如果布局类型限定词不存在的情况下,则所声明的共享数组按照区块大小为 1 进行分配。
- 如果布局类型限定词为 [ ] 或者 [0], 说明区块大小为无穷大,则所声明的共享数组将所有元素分配到线程 0 的共享内存空间中。
- 如果布局类型限定词为 [*], 则所声明的共享数组将按照区块大小为 ( sizeof(array) / upc_elemsizeof(array) + THREADS - 1 ) / THREADS 进行分配。
清单 2.数组声明例子
|
int A[3]; // 声明了一个私有整型数组 A,有 3个元素。
shared float B[5] // 声明一个共享浮点型数组 B,有 5个元素,按照区块大小为 1 进行分配。
shared [2] int C[11] // 声明一个共享整型数组 C, 有 11个元素,按照区块大小为 3 进行分配
shared [] float D[5] // 声明一个共享浮点型数组 D, 有 5个元素,所有元素分配到线程 0的共享内存空间中。 |
以上的例子中所声明的数组元素在内存中的分配视图下面图 3所示。

图 3.数组元素内存分配视图
如图 3所示,语句“int A[3]; ”声明了一个私有整型数组 A,每一个线程都被分配了相同的数组元素。语句“shared float B[5]; ”声明一个共享浮点型数组 B,因为没有布局类型限定词,所有默认按照区块大小为 1进行元素的一次分配。语句“shared [2] int C[11]”声明了一个共享整型数组 C,区块大小为 2,即每 2 个连续的元素会被一次分配到每个线程之中,直至元素分配完毕为止。语句“shared [] float D[5]”声明了一个共享浮点型数组 D,区块大小为无穷大,D数组的所有元素全被分配到线程 0的共享内存空间中。
指针
因为 UPC中具有共享和私有两种数据类型,所以一个指针所指向的数据可能是共享或者私有数据类型,并且指针的本身可能是共享或者私有数据类型,因此 UPC中共有 4 种指针类型如下面图 4所示。红色箭头代表的是 指向共享数据共享指针,黑色箭头代表的是指向私有数据共享指针,蓝色箭头代表的是 指向共享数据私有指针,绿色箭头代表的是 指向私有数据私有指针。
图 4. UPC四种指针种类
UPC的四种指针在内存中的视图如下面图 5所示。

图 5. UPC指针内存视图
- p1 是指向私有数据私有指针。所有 C 语言中的指针都是这种类型指针,特点是速度快。如果一个指向共享数据指针和所指的数据有亲缘关系,您可以将该指针转化为 p1 类型指针来提高访问速度。
- p2 是指向共享数据私有指针。这个指针可以用来访问共享数据。p2 速度要比 p1 慢。p2 访问和它有亲缘关系的共享数据速度比访问和它没有亲缘关系的共享数据的速度快。
- p3 是指向私有数据共享指针。这种指针会是线程访问其他线程的私有数据,不建议使用。
- p4 是指向共享数据共享指针。
清单 3.指向私有数据私有指针声明
|
int *p1; // 声明了一个指向私有整型数据的私有指针。这个指针将被分配到每一个线程的私有内存中 shared int *p2 // 声明一个指向共享数据私有指针,这个指针将被分配到每一个线程的私有内存中 int * shared p3// 声明一个指向私有数据共享指针,不建议使用,这个指针被分配到线程 0 的共享内存中 shared int * shared p4// 声明了一个指向共享数据共享指针,这个指针被分配到线程 0 的共享内存中 |
操作符
UPC在 C 的基础上扩展了以下的 5个一元运算符。这些运算符的操作数可以是一个类型或者是一元表达式。
- & 返回指向某一个操作数的指针。如果这个操作数是一个 T 类型的共享数据,则返回值具有 shared [] *T 的类型。
- sizeof 返回一个操作数字节大小。
- upc_blocksizeof 返回一个操作数的区块大小,这个值即是在类型声明中的布局类型限定词中的值。
- upc_elemsizeof 返回非数组的最左边类型的字节大小。
- upc_localsizeof 返回一个共享类型或者共享数据内和当前执行的线程有亲缘关系的字节大小。
回页首
upc_forall语句
多线程的并行编程中,任务在不同线程之间的分配是通过 upc_forall语句实现的。upc_forall语句的原型是 upc_forall (表达式 1;表达式 2;表达式 3;亲缘关系表达式 )。upc_forall语句与 C 语言中的 for语句的区别就是增加了第四个参数亲缘关系表达式。upc_forall语句中的前三个表达式在语法上与 C语言中的 for 语句一样。
| 亲缘关系表达式根据以下的规则来给线程分配任务: |
- 如果亲缘关系表达式是一个整型表达式,则由线程 MYTHREAD == affinity % THREADS 来执行当前的循环体。
- 如果亲缘关系表达式是一个指向共享数据指针类型的表达式,则由线程 MYTHREAD == upc_threadof(affinity) 来执行当前的循环体。
- 若亲缘关系表达式不存在或者为关键字 continue,则每个线程执行当前的循环体。
清单 4. upc_forall语句例子
|
// 假定 THREADS=5 upc_forall(i=0;i<9;i++;i) // 当 i=5的时候,MYTHREAD=7%5=2,则由线程 2 来执行以下循环体。 { … }
upc_forall(i=0;i<9;i++;&A[i]) //A 是一个共享类型数组,则由线程 MYTHREAD=upc_threadof(affinity),即 // 和 A[i]这个共享类型元素有亲缘关系的线程,来执行当前的循环体。 { … }
upc_forall(i=0;i<9;i++;continue) //每个线程执行当前的循环体。 { … } |
回页首
存储一致性模型
在一个多线程的程序中,一个线程对共享类型数据的访问顺序在其他线程看来可能是不同的。多个线程同时对于同一块共享内存空间的读和写,可能会导致其他线程读取过期的,半更新的,或者已经更新的数据。存储一致性模型则定义了读操作将以什么样的顺序看到写操作的结果。通过指定存储一致性模型,编程人员可以决定一个线程对共有数据的更新什么时候对其他线程可见。
数据的存储一致性模型被分为 strict和 shared 两种类型:
- strict 存储一致性模型
一个线程对共享数据的更新对其他线程立即可见。任何对共享数据的操作只有在先前对该共享数据的操作完成之后才能进行。编译器不可以改变独立的对共享数据访问的顺序来进行程序性能优化。运用这种存储一致性模型将延长程序的执行时间。
- relaxed 存储一致性模型
一个线程可以在任何时间对一个共享数据进行操作,无论其他线程对此共享数据进行任何的操作。编译器可以通过改变独立的对共享数据访问的顺序来实现程序性能的优化。
程序员可以对三种不同层次来定义存储一致性模型 ,这些不同定义方式的优先级由高到底排列如下:
- 用关键词 strict 或者 shared 来对一个变量进行定义存储一致性模型。
- 用 UPC 指令 #pragma upc strict 或者 #pragma upc relaxed 对一个程序区块进行定义存储一致性模型。
- 用头文件 include <upc_strict.h> 或者 include <upc_relaxed.h> 来对整个程序的范围进行定义存储一致性模型。
回页首
同步
UPC提供了障碍,篱笆和锁这三种同步原语来控制线程之间的交互作用。
障碍(barrier)是用来实现线程之间同步的原语。障碍又分为阻挡障碍(blocking barrier)和非阻挡障碍(non-blocking barrier)。
阻挡障碍如图 6所示,线程 1 和线程 2 以不同的速度在执行程序,当线程 1遇到阻挡障碍语句 upc_barrier的时候会停下来等待线程 2。当线程 2也执行到该阻挡障碍语句 upc_barrier的时候,线程 1 才会继续向前执行。
图 6.阻挡障碍示意图
非阻挡障碍由 upc_notify和 upc_wait 组成。如图 7 所示,线程 1和线程 2 以不同的速度在执行程序,当线程 1遇到非阻挡障碍语句 upc_notify的时候会通知线程 2 它已经执行到 upc_notify 的这个程序点了,然后线程 1 会继续执行,当执行到 upc_wait 才停下来等待线程 2,一直等到线程 2也执行到该 upc_notify的程序点发出到达报告,这时候线程 1才继续向前执行。一般在 upc_notify和 upc_wait 之间,程序员可以让线程进行无关其他线程的运算,这样充分地利用了线程 1的等待时间,提高了程序的性能。

图 7.非阻挡障碍示意图
篱笆(upc_fence)是用来实现线程内的同步的原语。当一个线程执行遇到篱笆的时候,它会确保所有在篱笆之前对共享数据的访问全部完成之后,再执行在篱笆之后对共享数据的访问。
锁(lock)在多线程的环境中,多个线程同时对一个共享数据的操作,会造成竞争状态。一个线程对一个共享数据的修改可能会使得其他线程读到不正确的数据。锁用来确保在同一的时间内只能有一个线程进行访问某一共享数据。锁是以牺牲程序性能来保证程序的正确性,因为它阻止了多线程的同步执行,所以在保证程序的正确性的基础上,尽量避免锁的使用。请参见使用库函数中的锁
回页首
UPC库函数
UPC语言中有实用函数和集体函数两类库函数。所谓集体函数就是由所有线程调用,有同样的返回值。所谓非集体函数就是由一个线程调用的函数,如果被多线程调用,则有不同的返回值。实用函数可以分为以下 5类:
程序终止
|
upc_global_exit 释放内存,结束所有线程的程序运行。 |
动态内存分配
- upc_all_alloc 是集体函数,给每一个的线程分配共享内存空间 .\
- upc_global_alloc 是非集体函数,给每一个的线程分配共享内存空间 .
- upc_alloc 给调用该函数的线程分配和其有亲缘关系的共享内存空间。
- upc_free 释放动态分配的共享内存空间。
指向共享数据指针操作
- upc_addrfiled 返回参数所指向的数据的本地地址
- upc_affinitysize 返回在一个共享类型数据中和给定的某一个线程有亲缘关系的共享内存空间大小。
- upc_phaseof 返回一个参数所指定的共享数据在其所在的区块中的位置。
- upc_resetphase 返回一个与所给参数指针相同的新指针,并且这个新的指针的相恒为 0。
- upc_threadof 返回一个与参数所指定的共享数据有亲缘关系的线程指数。
锁
- upc_all_lock_alloc 集体函数,给所有调用该函数的线程分配同一个锁,初始状态为解除锁定状态,并返回一个指向该锁的指针到每个线程。
- upc_global_lock_allock 非集体函数,给调用该函数的线程分配以个锁,初始状态为解除锁定状态,并返回指向该锁的指针。
- upc_lock 将参数所指向的锁的状态设定为锁定状态。
- upc_lock_attepmt 试图将参数所指向的锁的状态设定为锁定状态,成功则返回 1,失败则返回 0。
- upc_unlock 将参数所指定的锁的状态设定为解除锁定状态。
- upc_lock_free 释放参数所指向的锁占用的内存空间。
内存转储
- upc_memcpy 把数据从一个共享内存空间复制到另外一个共享内存空间。
- upc_memget 把和某个线程本地的共享数据复制到调用该函数的一个私有内存空间中
- upc_memput 把调用该函数的线程内的私有数据复制到和另一个线程的本地共享内存空间中。
- upc_memset 将一个字符复制到指定的共享内存空间中。
集体函数可以分为以下两类:
数据移动函数
- upc_all_broadcast 将某个线程上的一块共享内存空间复制到每一个线程的共享内存空间。
- upc_all_scatter 将某个线程上的第 i 块共享内存空间复制到第 i 个线程上的本地共享内存空间。
- upc_all_gather 将第 i 个线程上的一块本地共享内存空间复制到某一个线程的第 i 块共享内存空间。
- upc_all_gather_all 将第 i 个线程上的一块本地共享内存空间复制到每一个线程的第 i 块共享内存空间。
- upc_all_exchange 将线程 j 上第 i 块本地共享内存空间复制到线程 i 上第 j 块本地共享内存空间。
- upc_all_permute
计算操作函数
下面的这两个库函数都是用来对所有元素进行用户定义的操作(加减乘除等等),然后将所得结果返回到一个线程。
- upc_all_reduce
- up_all_prefix_reduce
回页首
UPC应用程序实例
下面通过一个具体的 UPC程序的例子来更好地理解 UPC语言 . 这个例子是通过 upc_forall语句对线程进行分工,计算出所给数组 A所有元素之和。程序输出如图 8所示。
清单 5. UPC程序例子
|
#include <upc.h> // 假定设定 4 个线程来执行这个程序
# define N 10000
shared int A[N]; shared int sum=0; shared int partialsum[THREADS]={0}; /* 声明一个共享整型数组,具有 THREADS个元素,因为我们假定四个线程来运行该程序, 所以 THREADS的值为 4。这个数组用来记录各个线程所算出来的元素和。 */
upc_lock_t *lock; // 声明一个类型为 upc_lock_t 的指针
int main() { lock=upc_all_lock_alloc(); // 给每一个线程分配一个共同的锁,并将其地址分配给 lock 指针 upc_forall(int i=0;i<N;i++;&A[i]) //upc_forall 语句根据亲缘关系表达式给线程分工 { A[i]=i; // 将数组 A 的元素初始化 } upc_barrier; // 阻挡障碍确保每个线程都完成对数组 A 的元素初始化
if(lock != NULL) // 如果成功地分配了这个锁 { upc_forall(int i=0;i<N;i++;&A[i]) // 各个线程计算自己本地分配的数组元素的和 { partialsum[MYTHREAD] +=A[i]; } upc_barrier; // 阻挡障碍确保每个线程完成计算,再向前执行。
upc_lock(lock); /* 这里到了程序的关键部分,因为 sum 是一个共享数据,可以被所有线程同时操作, 所以这里加个锁,只允许同一个时间内一个线程来操作 sum变量,从而避免了竞争状态, 保证了程序的正确性 */ sum +=partialsum[MYTHREAD]; // 将所有线程的分别计算出来的和加起来就是数组 A 所有元素的和 upc_unlock(lock); // 开锁
upc_barrier; // 阻挡障碍确保每个线程计算出来的和都加到 sum 上,再向前执行
if(MYTHREAD == 0) // 如果执行该语句的是线程 0 的话,则输出计算结果 { upc_lock_free(lock); //释放分配的锁 printf("Th:%d, result=%d \n",MYTHREAD,sum); return 1; } } return 0; } |
图 8.程序输出结果
![]()
回页首
IBM XL Unified Parallel C编译器简介
IBM® XL Unified Parallel C编译器支持 Unified Parallel C语言标准 1.2,可以应用在运行 AIX®和 Linux® 操作系统的 IBM power 系类服务器上。该编译器是继承了 IBM XL系列的编译器的优越性能,提供了详尽的语义和句法的检查,并对程序进行多种 UPC语言特有的优化。
回页首
结语
本文旨在介绍 UPC的入门基础,让读者对并行编程语言有初步的认识。对于 UPC语言的细节上的语法和使用方法请参阅 UPC标准 1.2.
参考资料
学习
- 参考 “UPC Language Specifications V1.2”, 了解更多关于 UPC 语言的细节规定和用法介绍。
- 参考“UPC Manual”,了解更多关于 UPC 入门的知识。
- 参考“UPC相关文档”,了解关于 UPC 方面的内容。
- 参考“IBM XL Unified Parallel C编译器”,了解或者下载安装试用 IBM XL Unified Parallel C 编译器。
- 在 developerWorks Linux专区寻找为 Linux 开发人员(包括 Linux新手入门)准备的更多参考资料,查阅我们 最受欢迎的文章和教程。
- 在 developerWorks 上查阅所有 Linux技巧和 Linux教程。
- 随时关注 developerWorks 技术活动和 网络广播。
讨论
- 欢迎加入 My developerWorks中文社区。
关于作者
胡国威,IBM CDL软件工程师,所在团队目前从事 Rational compiler产品相关用户文档写作。他拥有计算机本科学位和英语专业硕士学位,是 XL Unified Parallel C User ’ s Guide的主要作者,对并行编程语言 UPC有着浓厚的兴趣。
来源: http://www.ibm.com/developerworks/cn/linux/l-cn-upc/