一个死锁的问题
问题是这样的,如下图所示:
1.有一个线程模型,其中,MainThread为主线程,他有一些资源,比如两个互斥器mutex1,mutex2,下面统称为锁。
2.这个主线程可以创建很多子线程thread1、thread2......threadn,主线程还有很多回调函数callback1、callback2......callbackn,这些回调函数在创建子线程时被挂到子线程上。
3.这些子线程会互斥的轮询一段代码C,C中会访问主线程中的一些资源。可想而知,在轮询时,他们需要加锁,于是每个线程就争抢mutex1这个锁。
4.代码C中做了一件事情,它会尝试调挂在它上面的回调函数(比如thread1执行代码段C时,就去调callback1),由于回调函数都在主线程,而触发回调是在各个子线程,因此这里就需要线程同步,于是,会有一个线程同步队列。各个子线程将触发回调的消息投递到这个用于线程同步的队列中(入队),可想而知,他们也是互斥的,因此在投递时,各个子线程需要争夺mutex2这个锁,因为是异步投递,所以投递后立刻释放mutex2,并返回到它自己的线程中继续执行代码C中后面的代码,代码C结束后,释放mutex1这个锁。
5.用于线程同步的队列会不断的取出队首的回调并触发它(出队),且入队和出队是多线程的,所以出队时也要争抢到mutex2这个锁才可以做。得到mutex2后,出队首元素,触发其回调,回调执行完后,释放mutex2。
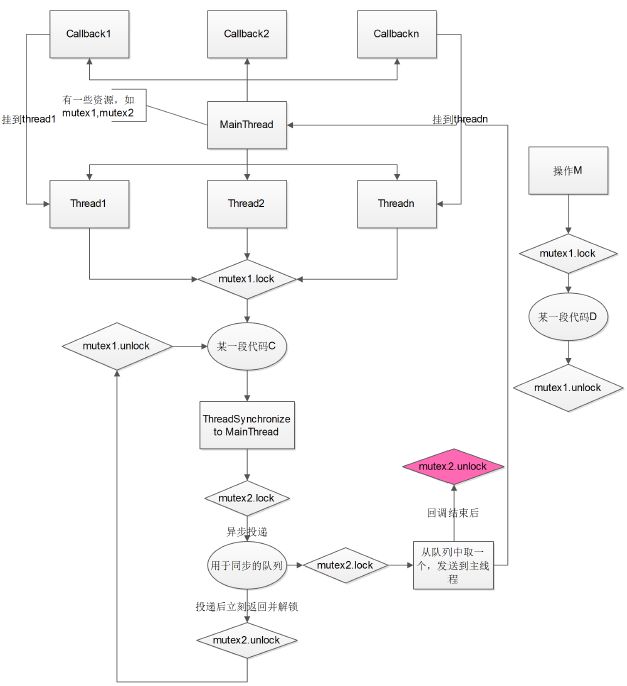
上述5点就描述了这个线程模型的基本运作情况,总结起来就是有两套独立的轮询:
第一套:
各个子线程先抢mutex1
-->持有mutex1后
-->再抢mutex2
->持有mutex2后
-->投递到线程同步队列
-->释放mutex2
-->释放mutex1
第二套:
线程同步队列抢mutex2锁
-->持有mutex2后
-->出队,触发回调
-->回调结束后释放mutex2
这种模型可以良好的工作不发生死锁。因为根据死锁产生的原因,必然是至少有两个操作在同时争抢至少两个锁,且各自占有一个锁时,会发生死锁,如下
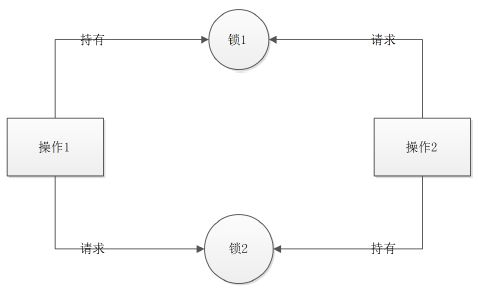
上面的模型中没有这种情况,所以不会死锁。
现在加一个操作M,可以认为它是一个函数,在主线程中执行,并会访问主线中的一些资源,所以,这段代码也需要加mutex1锁执行。当M单独被触发时,它与多个子线程争抢mutex1,并总有机会得到,所以不会死锁。
现在考虑将操作M放到各个回调函数中执行,则第二套轮询变为:
线程同步队列抢mutex2锁
-->持有mutex2后
-->出队,触发回调
-->回调中执行M,抢mutex1锁
-->持有mutex1后
-->执行代码段D
-->释放mutex1后
-->回调结束后释放mutex2
一开始查原因时,怀疑是代码段C重入的问题,于是将boost::mutex改为boost::recursive_mutex来允许重入,但是依然没有解决问题。后来发现线程同步时采用的是异步投递,及投递完就返回,代码C并不会因为投递后触发回调而被阻塞,那么就不会有重入的问题。
最后发现问题出现在从线程同步队列中出队并触发回调这里
伪代码如下:
mutex2.lock();//获得mutex2锁
pCallBack = queue.front()//出队
pCallBack();//触发回调,阻塞在这里,等待回调执行完
mutex2.unlock()//回调执行完后释放mutex2
那么当执行回调时,拿住了mutex2(即回调将mutex2被锁住的状态带了出去),回调中的M操作又去请求mutex1锁而这时,由于多个子线程还在不断轮询,则可以预料某一个子线程拿住了mutex1锁,在请求mutex2锁,于是发生死锁。
其实解决方案也很简单,由上面的第一张图中标红处和上面的伪代码可知,mutex2解锁如果提前的话,就不会有问题。及在出队后,先释放mutex2,再触发回调,这样回调就不会把mutex2被锁住的状态带出去)。伪代码如下:
mutex2.lock();//获得mutex2锁
pCallBack = queue.front()//出队
mutex2.unlock()//释放mutex2
pCallBack();//触发回调,阻塞在这里,等待回调执行完
从发现这个问题到解决花了将近两天时间,一开始以为是重入的问题,于是研究了boost::recursive_mutex和boost::mutex的区别,并替换为boost::recursive_mutex,但还是不行,中间花了很多时间学习boost的锁,并对自己的多线程基础知识产生了质疑。不过也暴露了在多线程调试经验上的不足,方法不多。后来尝试在代码C异步投递之后向文件打log查看异步投递是否返回的方式,发现只要是加上了这个打log的操作,就不会死锁,于是顺着这条线,终于查到了原因。现在回过头看打Log后不死锁这件事,我认为这是一个时间差的原因,及这种方式不是不会产生死锁,原来没打log时也不是必然产生死锁,只是一个时间差导致的概率问题,打Log后,可能因为线程操作所需时间改变,造成争抢mutex1的时间刚好合适到子线程不会拿到mutex1,所以M操作顺利拿到两个锁,于是没死锁。没死锁不代表逻辑没问题,只是死锁概率降低了,相信重复操作量达到一定程度时,死锁还是会出现。