HBase数据导入(一)importtsv工具导入文本文件到Hbase
转载请注明出处:季义钦的技术博客
刚安装好Hbase,如果不知道怎么安装,请参见我这篇博文,首先想到的就是能够导入大量数据,然后查询玩玩。
怎么导入呢,了解到可以从文本文件导入,那就先测试一下吧,在这之前先要配置一下Hadoop。
配置步骤:
1 首先要修改Hadoop的配置文件hadoop-env.sh:
vim /usr/hadoop/hadoop/conf/hadoop-env.sh,增加下面的Hbase的配置项
#jiyiqin add for Hbase data import
export HBASE_HOME=/usr/HBase/hbase
export HADOOP_CLASSPATH=$HBASE_HOME/hbase-0.94.20.jar:$HBASE_HOME/hbase-0.94.20-tests.jar:$HBASE_HOME/conf:${HBASE_HOME}/lib/zookeeper-3.4.5.jar:${HBASE_HOME}/lib/guava-11.0.2.jar
自己打开自己的Hbase的目录看看你的这些jar文件是不是这些版本,如果不是就自己改一下。
2 然后就是将Hbase下面相关的jar文件拷贝到Hadoop对应的目录下面:
257 cp /usr/HBase/hbase/hbase-0.94.20.jar /usr/hadoop/hadoop/lib/ 258 cp /usr/HBase/hbase/hbase-0.94.20-tests.jar /usr/hadoop/hadoop/lib/ 259 cp /usr/HBase/hbase/conf/hbase-site.xml /usr/hadoop/hadoop/conf/
还有一个文件也要拷贝,如果不拷贝,一会执行importtsv命令导入数据的时候会报异常:
13/05/23 09:41:05 INFO zookeeper.ClientCnxn: Opening socket connection to server /192.168.1.137:2181
13/05/23 09:41:06 WARN client.ZooKeeperSaslClient: SecurityException: java.lang.SecurityException: 无法定位登录配置 occurred when trying to find JAAS configuration.
13/05/23 09:41:06 INFO client.ZooKeeperSaslClient: Client will not SASL-authenticate because the default JAAS configuration section 'Client' could not be found. If you are not using SASL, you may ignore this. On the other hand, if you expected SASL to work, please fix your JAAS configuration.
13/05/23 09:41:06 INFO zookeeper.RecoverableZooKeeper: The identifier of this process is 8953@localhost
13/05/23 09:41:06 INFO zookeeper.ClientCnxn: Socket connection established to master/192.168.1.137:2181, initiating session
13/05/23 09:41:06 INFO zookeeper.ClientCnxn: Session establishment complete on server master/192.168.1.137:2181, sessionid = 0x13ecf0b470c0004, negotiated timeout = 180000
Exception in thread "main" java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.hbase.mapreduce.Driver.main(Driver.java:51)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.util.RunJar.main(RunJar.java:156)
Caused by: java.lang.NoClassDefFoundError: com/google/protobuf/Message
at org.apache.hadoop.hbase.io.HbaseObjectWritable.<clinit>(HbaseObjectWritable.java:263)
at org.apache.hadoop.hbase.ipc.Invocation.write(Invocation.java:139)
at org.apache.hadoop.hbase.ipc.HBaseClient$Connection.sendParam(HBaseClient.java:638)
at org.apache.hadoop.hbase.ipc.HBaseClient.call(HBaseClient.java:1001)
at org.apache.hadoop.hbase.ipc.WritableRpcEngine$Invoker.invoke(WritableRpcEngine.java:150)
at $Proxy5.getProtocolVersion(Unknown Source)
at org.apache.hadoop.hbase.ipc.WritableRpcEngine.getProxy(WritableRpcEngine.java:183)
at org.apache.hadoop.hbase.ipc.HBaseRPC.getProxy(HBaseRPC.java:335)
at org.apache.hadoop.hbase.ipc.HBaseRPC.getProxy(HBaseRPC.java:312)
at org.apache.hadoop.hbase.ipc.HBaseRPC.getProxy(HBaseRPC.java:364)
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.getMaster(HConnectionManager.java:682)
at org.apache.hadoop.hbase.client.HBaseAdmin.<init>(HBaseAdmin.java:110)
at org.apache.hadoop.hbase.mapreduce.ImportTsv.main(ImportTsv.java:352)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:68)
at org.apache.hadoop.util.ProgramDriver.driver(ProgramDriver.java:139)
... 10 more
Caused by: java.lang.ClassNotFoundException: com.google.protobuf.Message
at java.net.URLClassLoader$1.run(URLClassLoader.java:202)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:190)
at java.lang.ClassLoader.loadClass(ClassLoader.java:306)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:301)
at java.lang.ClassLoader.loadClass(ClassLoader.java:247)
... 29 morecp /usr/HBase/hbase/lib/protobuf-java-2.4.0a.jar /usr/hadoop/hadoop/lib/
其实在这之前我把zookeeper的一个文件也拷贝过去了,我不知道这个是不是必须的,也没有再去掉试试,你可以也拷贝过去:
cp /usr/HBase/hbase/lib/zookeeper-3.4.5.jar /usr/hadoop/hadoop/lib/
好了,准备工作做好了。
3 启动hadoop: start-all.sh
4 启动hbase:start-hbase.sh
5 在Hbase上新建一个只有一个列族的表:
hbase shell create 'table2','CF'
6 准备要导入的文本文件,并上传到HDFS:
文本文件是这样的(以逗号分割,导入命令中会指定分割符):
1,jiyiqin,jiangsu 2,wanglihong,taiwan 3,zhoujielun,taiwan 4,liudehua,hongkong 5,liangchaowei,hongkong 6,xijingping,beijing
上传到HDFS是这样:
hadoop fs -mkdir /test
hadoop fs -put test.txt /test
hadoop fs -ls /test
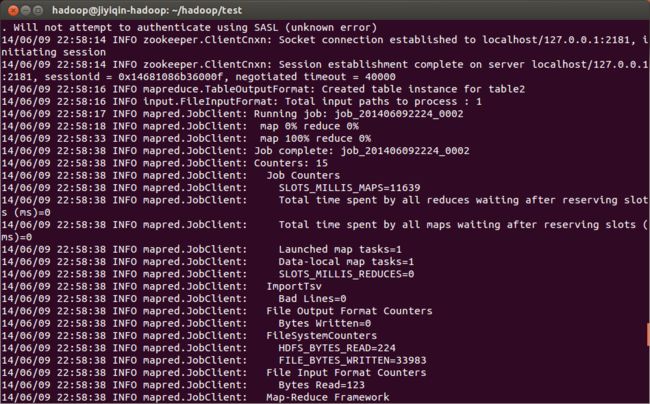
7 使用importtsv命令导入,下面是完整的导入命令:
hadoop@jiyiqin-hadoop:~/hadoop/test$ hadoop jar /usr/hadoop/hadoop/lib/hbase-0.94.20.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,CF:col1,CF:col2 -Dimporttsv.separator=, table2 /test1/test.txt如果出现下面的mapreduceu作业执行信息,并且bad lines=0,就说明正确导入了:
然后就可以登陆Hbase查看导入的数据了:
> hbase shell
> scan 'table2'
其实importtsv导入数据还有一种方式,分为两步,第一步要先生成临时的HFile文件,当数据量较大时,我上面将的方式会比较慢,而两步走的方式会快一些,下面是我转载来的关于这个的说明:
第一步,生成hfile
Script代码

- hadoop jar hbase-version.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,c1,c2 -Dimporttsv.bulk.output=tmp hbase_table hdfs_file
-Dimporttsv.bulk.output=tmp, tmp生成后会在hdfs的/user/hadoop/tmp中
第二步,导入hbase表,这一步其实是mv的过程,即利用生成好的hfile移到hbase中
Script代码
- hadoop jar hbase-version.jar completebulkload /user/hadoop/tmp/cf hbase_table
当不需要生成临时文件,直接bulk load时,
Script代码
- hadoop jar hbase-version.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,c1,c2 hbase_table hdfs_file
值得注意的是,经过测试,在数据量较大时,两步处理方式比一步导入方式有效率和稳定性上的优势:
1. 两步导入时,由于是先生成文件,再复制文件进入HBase表,对于HBase读取的性能影响较小,不会出现较大的读取时间波动;
2. 两步导入时,时间上要节约三分之二,等于效率提高60%~70%,map的处理时间较短,只有一个reduce, 一步导入时,map处理时间较长,没有reduce. 由于hadoop集群在配置时,一般会有较多的最大map数设置,较少的最大reduce数设置,那么这种两步导入方式也在一定程度上提升了hadoop集群并发能力。