计算机视觉CV 之 CMT跟踪算法分析二
1 前言
在上一篇文章中,我对CMT算法做了初步的介绍,并且初步分析了一下CppMT的代码,在本篇文章中,我将结合作者的论文更全面细致的分析CMT算法。
这里先说明一下,作者关于CMT算法写了两篇文章:
Consensus-based Matching and Tracking of Keypoints for Object Tracking (wacv2014 best paper reward)
Clustering of Static-Adaptive Correspondences for Deformable Object Tracking (cvpr 2015)
其中wacv的文章从更工程的角度来分析CMT的算法,写出来其详细的流程,比较推荐阅读。
2 CMT 算法流程

这里我直接截取了文章中的原图。
我把它翻译一下:
算法 CMT
输入: 视频帧,初始的物体框
输出:每一帧视频的物体框
要求:后继的物体框能够保持框住初始框框住的物体
步骤:
Step 1:检测初始视频帧的所有特征点和特征描述,不仅仅是框内的点而是整个图像的点,所以在代码中可以看到,初始的database数据库的特征描述包含了前景(框内)和背景(框外)的特征
Step 2:将初始框内的特征描述赋给K1
Step 3:从第二帧开始
Step 4:检测视频帧的特征点P
Step 5:将特征点P与O匹配,获取匹配的特征点M
Step 6:利用上一帧的特征点使用光流法跟踪得到这一帧的特征点的位置T
Step 7:融合特征点M和特征点T得到这一帧的总的特征点K’
Step 8:根据K’估计特征点相对初始帧特征的缩放比例
Step 9:根据K’估计特征点相对初始帧特征的旋转比例
Step 10:根据Step7,8,9得到的数据计算每一个特征点的Vote
Step 11:采用聚类的方法选取最大的类也就是最一致的VoteC
Step 12:将VoteC转换回特征点得到最后这一帧的有效特征点
Step 13:判断VoteC的长度是否大于最小阈值,如果是则计算最后新的旋转矩形框的参数,如果不是也就是框太小了则输出0
下面结合代码及论文分析每一步
Step 1,2 初始化
在CMT.cpp的代码中可以比较清晰的理解,就是使用openCV的Fast或者BRISK特征检测及特征描述。然后关键是存储有效的数据在数据库用于之后的匹配,主要在以下两个代码
//Initialize matcher 初始化匹配器
matcher.initialize(points_normalized, descs_fg, classes_fg, descs_bg, center);
//Initialize consensus 初始化一致器
consensus.initialize(points_normalized);进去看一下细节:
void Matcher::initialize(const vector<Point2f> & pts_fg_norm, const Mat desc_fg, const vector<int> & classes_fg,
const Mat desc_bg, const Point2f center)
{
//Copy normalized points 存储 正规化的点
this->pts_fg_norm = pts_fg_norm;
//Remember number of background points 存储背景的特征点的数量
this->num_bg_points = desc_bg.rows;
//Form database by stacking background and foreground features
// 合成前景和背景的特征到一个Mat文件中
if (desc_bg.rows > 0 && desc_fg.rows > 0)
vconcat(desc_bg, desc_fg, database);
else if (desc_bg.rows > 0)
database = desc_bg;
else
database = desc_fg;
//Extract descriptor length from features 根据特征抽取描述其长度
desc_length = database.cols*8;
// classes的作用就是为了对应找到的特征,从而可以知道上一帧的特征位置计算一致性
//Create background classes (-1) 创建背景索引
vector<int> classes_bg = vector<int>(desc_bg.rows,-1);
//Concatenate fg and bg classes 连接前景和背景的索引
classes = classes_bg;
classes.insert(classes.end(), classes_fg.begin(), classes_fg.end());
//Create descriptor matcher 创建描述匹配器BruteForce-Hamming
bfmatcher = DescriptorMatcher::create("BruteForce-Hamming");
}
void Consensus::initialize(const vector<Point2f> & points_normalized)
{
//Copy normalized points 复制正规化的点
this->points_normalized = points_normalized;
size_t num_points = points_normalized.size();
//Create matrices of pairwise distances/angles 创建矩阵用于计算任何两个点之间的距离和角度
distances_pairwise = Mat(num_points, num_points, CV_32FC1);
angles_pairwise = Mat(num_points, num_points, CV_32FC1);
for (size_t i = 0; i < num_points; i++)
{
for (size_t j = 0; j < num_points; j++)
{
Point2f v = points_normalized[i] - points_normalized[j];
float distance = norm(v);
float angle = atan2(v.y,v.x);
// 这里计算特征点两两相对距离和相对角度用于计算一致性
distances_pairwise.at<float>(i,j) = distance;
angles_pairwise.at<float>(i,j) = angle;
}
}
}
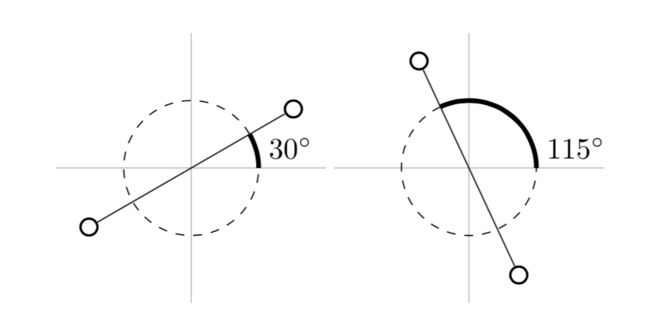
那么特征的角度距离是按下图意思计算的,我想对应一下代码还是很好理解的:
接下来分析Step 3,4,5,6.
Step 3,4,5,6 分析
关键是跟踪和匹配
在processFrame函数中可以看到。
跟踪使用:
//Track keypoints
vector<Point2f> points_tracked;
vector<unsigned char> status;
// 利用光流法计算关键点的当前位置。
tracker.track(im_prev, im_gray, points_active, points_tracked, status);深入查看代码发现作者使用了双向的跟踪:
void Tracker::track(const Mat im_prev, const Mat im_gray, const vector<Point2f> & points_prev,
vector<Point2f> & points_tracked, vector<unsigned char> & status)
{
if (points_prev.size() > 0)
{
vector<float> err; //Needs to be float
//Calculate forward optical flow for prev_location 计算前向位置的光流(即特征点的移动)
calcOpticalFlowPyrLK(im_prev, im_gray, points_prev, points_tracked, status, err);
vector<Point2f> points_back;
vector<unsigned char> status_back;
vector<float> err_back; //Needs to be float
//Calculate backward optical flow for prev_location 计算后向光流
calcOpticalFlowPyrLK(im_gray, im_prev, points_tracked, points_back, status_back, err_back);
//Traverse vector backward so we can remove points on the fly 删除掉飞掉的点
for (int i = points_prev.size()-1; i >= 0; i--)
{
float l2norm = norm(points_back[i] - points_prev[i]);
bool fb_err_is_large = l2norm > thr_fb;
if (fb_err_is_large || !status[i] || !status_back[i])
{
points_tracked.erase(points_tracked.begin() + i);
//Make sure the status flag is set to 0
status[i] = 0;
}
}
}
}
基本的思路就是先使用上一帧的特征点points_prev通过光流计算这一帧的对应位置points_tracked,然后反过来使用points_tracked计算对应的上一帧的位置points_back,然后对比points_prev和points_back之间的距离,按道理应该是接近0才对,但是因为光流计算有误差,因此,有的可能比较大,因此作者设置了一个阈值thr_fb 30,如果大于该阈值,表示得到的数据有误,删掉该点。
这么做的目的是为了使跟踪得到的结果更可靠。
由于时间关系,本文先分析到这。下一篇文章分析接下来的步骤。
本文为原创文章,转载请注明出处:https://blog.csdn.net/songrotek