FAQ:What is a document partition?(什么是文档的分区)
Eclipse官方FAQ翻译系列
原始文档地址:http://wiki.eclipse.org/FAQ_What_is_a_document_partition%3F
每个document被分割为一个或多个非重叠的partition,文本框架(text-framework)的大部分功能可以被配置成对不同的partition提供独立的操作。因此,一个编辑器在不同的partition中可以拥有不同的语法高亮,格式化或者内容辅助。例如,Eclipse的Java编辑器针对字符串,字符和注释拥有不同的partition(译者注:一个典型的例子,当处于注释partition中,代码提示会无效)
如果没有明确定义partition,则默认使用一个单独的partition,类型是IDocument.DEFAULT_CONTENT_TYPE。如果显示定义的partition没有扩展到整个document,document所有剩余的部分隐示的属于默认partition。换句话说,document中的每个字符肯定属于某个partition。多数editor对document中需要自动义行为的小部分显示定义partition。而其他的大部分仍然属于默认partition。
通过连接Document到org.eclipse.jface.text.IDocumentPartitioner类的一个实例来实现对文档的分区(partition)。在编辑器的情况,这通常在document被创建后,通过document的provider来添加。你可以直接实现partitioner接口来实现完全的控制,但大多数情况下你只需简单的使用默认实现-DefaultPartitioner。这个来自HTML编辑器的例子定义了一个partitioner并且把它连接到document:
IDocumentPartitioner partitioner
=
new
DefaultPartitioner(
createScanner(),
new
String[] {
HTMLConfiguration.HTML_TAG,
HTMLConfiguration.HTML_COMMENT });
partitioner.connect(document);
document.setDocumentPartitioner(partitioner);
默认partitioner的构造方法的参数是一个分区扫描器(scanner)和一个document的分区类型数组(String类型)。分区扫描器(partition scanner)负责计算分区,当document的一个区域(region)被传递给scanner,它就产生一个token集合来描述那个区域的各个分区(每个分区对应一个定义好的token)。当一个Document被创建,scanner用于计算整个document区域的分区。当一个document发生改变,scanner被请求来对document改变的区域进行重新分区。
<img src=../images/editor-scanner.png>
Figure 15.2 Partitioning a document using the Eclipse text-editing framework
(译者注:不能怪我,网站上就没图,应该是路径错了,或者img标签没有结束)
文本框架(text framework)提供了一个功能强大的基于规则的基础扫描器来创建一个基于一组谓词规则(predicate rule)的扫描器。你可以创建该扫描器的一个实例,然后向其中插入定义了document区域的规则。每个规则的输入是一个字符流,如果字符流满足匹配规则,则返回一个Token来表示该区域属于某个特定分区。查看IPredicateRule的类型结构以了解哪些默认规则可用。下面的片段描述了为HTML编辑器例子创建scanner。

 IPartitionTokenScanner createScanner()
...
{
IPartitionTokenScanner createScanner()
...
{
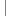 IToken cmt = new Token(HTMLConfiguration.HTML_COMMENT);
IToken cmt = new Token(HTMLConfiguration.HTML_COMMENT);
IToken tag = new Token(HTMLConfiguration.HTML_TAG);
IPredicateRule[] rules = new IPredicateRule[2];
rules[0] = new MultiLineRule("", cmt);
rules[1] = new TagRule(tag);
RuleBasedPartitionScanner scanner = new RuleBasedPartitionScanner();
scanner.setPredicateRules(rules);
return sc;
 }
}