上一篇文章中,我们介绍了ServerBootstrap的启动过程,在这个过程中引出了一个很重要的类ChannelPipeline。如果说内存池,线程模型是netty的基础,我们接触的相对来说并不是那么直接,那么ChannelPipeline则是我们开发中直接能够接触到的概念,如果对其不了解,很容易造成一些不正确的使用姿势或一些然并卵的优化。现在我们就来看看ChannelPipeline的作用到底是啥。
ChannelPipeline包含了一个ChannelHander形成的列表。其中ChannelHander是用于处理连接的Inbound或者Outbound事件,也是所有开发者都会直接接触到的一个类。ChannelPipeline实现了一个比较高级的拦截过滤模式,用户可以完全控制事件的处理,并且pipeline中的ChannelHandler可以相互交互。
不管是server还是client,每个连接都会对应一个pipeline,该pipeline在Channel被创建的时候创建(注意这里的Channel是指netty中封装的Channel,而不是jdk的底层连接)。先看看ChannelPipeline的官方注释,(比较懒,直接截了个图。。。),该注释直观的描述了IO事件在pipeline中的处理流程。
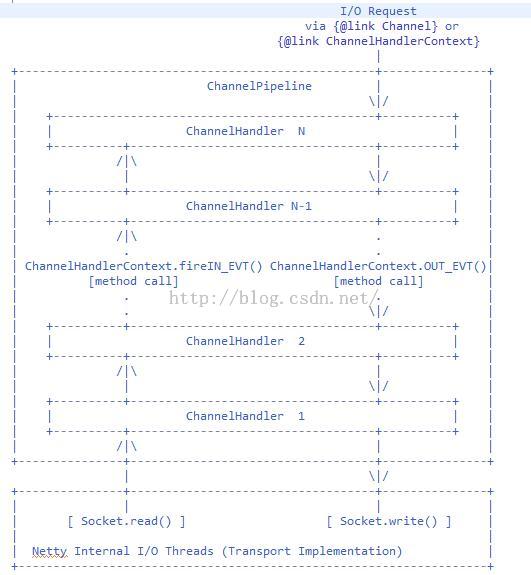
从图中可以看到inbound事件(read为代表)是从ChannelHandler1开始处理一直到最后一个ChannelHandler N,而outbound事件(write为代表)则是从ChannelHandler N开始处理,一直到ChannelHandler1。当然这个只是一个典型的处理流程,用户可以完全控制这个流程,改变事件的处理流程,如跳过其中一个ChannelHander,甚至在处理过程中动态的添加或者删除ChannelHandler。那么inbound和outbound各自有哪些事件呢?来看看下面两个表:
| ChannelHandlerContext#fireChannelRegistered() | 注册连接 |
| ChannelHandlerContext#fireChannelUnregistered() | 取消注册 |
| ChannelHandlerContext#fireChannelActive() | 连接激活 |
| ChannelHandlerContext#fireChannelRead(Object) | 读取数据 |
| ChannelHandlerContext#fireChannelReadComplete() | 读取完成 |
| ChannelHandlerContext#fireExceptionCaught(Throwable) | 发生异常 |
| ChannelHandlerContext#fireUserEventTriggered(Object) | 用户事件触发 |
| ChannelHandlerContext#fireChannelWritabilityChanged() | 可写状态改变 |
| ChannelHandlerContext#fireChannelInactive() | 检测到连接断开 |
| ChannelHandlerContext#bind(SocketAddress, ChannelPromise) | 绑定端口 |
| ChannelHandlerContext#connect(SocketAddress, SocketAddress, ChannelPromise) | 发起连接 |
| ChannelHandlerContext#write(Object, ChannelPromise) | 写数据 |
| ChannelHandlerContext#flush() | 将写的数据发送 |
| ChannelHandlerContext#read() | 触发读操作 |
| ChannelHandlerContext#disconnect(ChannelPromise) | 与对方的连接断开 |
| ChannelHandlerContext#close(ChannelPromise) | 关闭自己的连接 |
| ChannelHandlerContext#deregister() | 触发取消注册 |
需要注意的是不管是在inbound事件还是outbound事件处理的过程中发生异常,都会触发fireExceptionCaught方法的调用。当然fireExceptionCaught本身如果发生异常是不会再进行处理了,只是简单的记录一个异常日志,否则就死循环了。
ChannelPipeline提供了很多方法来方便对ChannelHandler进行操作,如addLast,addFirst,remove,replace等。最后强调一下,ChannelPipeline的所有方法都是线程安全的!
下面我们来看看ChannelPipeline的默认实现DefaultChannelPipeline。
final AbstractChannel channel; // pipeline对应的连接
// 通过context.next和context.prev形成一个双向链表
final AbstractChannelHandlerContext head; // pipeline中的第一个Context
final AbstractChannelHandlerContext tail; // pipeline中的最后一个Context
<pre name="code" class="java"> // 保存除head和tail外所有Context的map,由于ChannelPipeline中的操作都是线程安全的,所以这里是HashMap
private final Map<String, AbstractChannelHandlerContext> name2ctx =
new HashMap<String, AbstractChannelHandlerContext>(4);
private Map<EventExecutorGroup, ChannelHandlerInvoker> childInvokers;
这里引出了又一个重要的类ChannelHandlerContext,顾名思义ChannelHandlerContext就是一个拥有ChannelHandler的类,该类使ChannelHandler可以通过ChannelPipeline与其他的ChannelHandler交互,而ChannelPipeline也是通过该类对ChannelHandler进行操作,该类非常重要,我们一会会具体分析它。
DefaultChannelPipeline(AbstractChannel channel) {
if (channel == null) {
throw new NullPointerException("channel");
}
this.channel = channel;
tail = new TailContext(this);
head = new HeadContext(this);
head.next = tail;
tail.prev = head;
}
从构造方法可以看出在pipeline中head和tail是默认分配的。
TailContext是outbound事件的起点,inbound的终点,他的所有inbound方法都是空实现,而outbound方法则是简单的把控制权交给前面的handler。有了tail,我们能够保证inbound处理流最终能够优雅的结束掉(空实现,事件不会再往后传播),而不用在进行各种空判断;而对于outbound事件,它直接唤起下一个handler处理,充当了一个隐形的老好人。可以这么说,虽然它确实没什么太大的卵用,但是没有它,你会发现很多地方的代码将变得很难看。
HeadContext是inbound的起点,outbound的终点。作为inbound的起点,他也只是默默的把控制权交给后面的handler。而作为outbound的终点,他承担的责任则非常重要,他负责对outbound事件进行最终的底层调用(这里的底层是netty底层,而非jdk底层或操作系统底层),因此如果你暂时不关心编解码,而想了解write方法之类的最终实现,可以直接在HeadContext的对应方法上加断点,然后就可以直接了解这一部分知识了。
以下是HeadContext中outbound事件的部分方法:
public void read(ChannelHandlerContext ctx) {
unsafe.beginRead();
}
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
unsafe.write(msg, promise);
}
@Override
public void flush(ChannelHandlerContext ctx) throws Exception {
unsafe.flush();
}
有了头尾,我们来看看链表中间的部分是怎么生成/处理的。下面是将节点加到链表最前面的位置,注意,这里面的最前和最后是排除HeadContext、TailContext的。
public ChannelPipeline addFirst(ChannelHandlerInvoker invoker, String name, ChannelHandler handler) {
synchronized (this) {
name = filterName(name, handler);
addFirst0(name, new DefaultChannelHandlerContext(this, invoker, name, handler));
}
return this;
}
private void addFirst0(String name, AbstractChannelHandlerContext newCtx) {
// 检查该context中的hander是否重复添加了
checkMultiplicity(newCtx);
AbstractChannelHandlerContext nextCtx = head.next;
newCtx.prev = head;
newCtx.next = nextCtx;
head.next = newCtx;
nextCtx.prev = newCtx;
name2ctx.put(name, newCtx);
// 触发handler.handlerAdded(newCtx)
callHandlerAdded(newCtx);
}
// 检查是否有重复添加的情况
private static void checkMultiplicity(ChannelHandlerContext ctx) {
ChannelHandler handler = ctx.handler();
if (handler instanceof ChannelHandlerAdapter) {
ChannelHandlerAdapter h = (ChannelHandlerAdapter) handler;
// 如果Handler未添加Sharable注解,且added为true,则报错
if (!h.isSharable() && h.added) {
throw new ChannelPipelineException(
h.getClass().getName() +
" is not a @Sharable handler, so can't be added or removed multiple times.");
}
// added标记设置为true,表示handler已经被使用到context中
h.added = true;
}
}
ChannelHandlerInvoker是用来支持handler的线程访问模式的,正常情况下,pipeline中的所有方法使用启动时指定的EventLoop来处理handler中的方法,但如果你觉得netty的线程模型无法满足你的需求,你可以自己实现一个ChannelHandlerInvoker来使用自定义的线程模型。
注意,pipeline中的所有context都是私有的,针对context的所有操作都是线程安全的,但context对象包含的handler不一定是私有的。比如添加了Sharable注解的handler,表示该handler自身可以保证线程安全,这种handler只实例化一个就够了。而对于没有添加Sharable注解的handler,netty就默认该handler是有线程安全问题的,对应实例也不能被多个Context持有。
pipeline中还提供了很多方法来最大化的支持你控制pipleline,如addLast,addBefore,addAfter,replace,remove,removeFirst,removeLast等,从方法名就能看出其作用,这里不过多介绍。需要注意的是remove(Class handlerType)方法移除的是pipeline中第一个type为handlerType的handler,而不是移除所有type未handlerType的handler。
pipleline中定义了fireChannelInactive等一些列方法,该系列方法与ChannelHandlerContext中的方法名相同,然而他们的返回值并不同,方法也不是来自同样的接口。方法名相同估计是为了让开发者调用起来更加方便(记忆)。以下面两个方法为例,pipeline的fireChannelInactive直接调用了head.fireChannelInactive。
public ChannelPipeline fireChannelInactive() {
head.fireChannelInactive();
return this;
}
public ChannelFuture bind(SocketAddress localAddress, ChannelPromise promise) {
return tail.bind(localAddress, promise);
}
之前看文章有同学在困惑下面两种调用方式到底有何不同,这个其实就是被相同的方法名给欺骗了。本来就不是一样的东西。 调用方式1,表示从当前的前一个handler开始处理(outbound),而调用方式二则是从tail开始处理。
public void channelRead(ChannelHandlerContext ctx, Object msg) {
// 调用方式1
ctx.writeAndFlush(result);
// 调用方式2, 翻译过来就是tail.writeAndFlush(msg)
ctx.pipeline().writeAndFlush(result);
}
在这一堆outbound/inbound方法中有两个方法不是简单的调用ctx.xxx(), 这两个方法如下:
public ChannelPipeline fireChannelActive() {
head.fireChannelActive();
// 如果channel是自动开始读取,则此处会触发一次read,read方法最终会触发HeadContext的unsafe.beginRead();
// 对于一个ServerSocketChannel,beginRead就是向SelectKey注册OP_ACCEPT事件,而对于SocketChannel来说,则是向SelectKey注册OP_READ事件
if (channel.config().isAutoRead()) {
channel.read();
}
return this;
}
public ChannelPipeline fireChannelUnregistered() {
head.fireChannelUnregistered();
// 如果连接关闭并且取消了注册,则依次移除所有handler(从头tail -> head)
if (!channel.isOpen()) {
destroy();
}
return this;
}
这两个方法正是一个channel注册到EventLoop后的开始和结束方法。总的说来DefaultChannelPipleline不复杂。 现在我们整理一下连接在pipeline的整个生命周期是什么样子的。
Server端:
1、ServerSocketChannel : fireChannelRegistered(注册到EventLoop) -> bind(绑定端口)-> fireChannelActive(激活) ->【read(注册OP_ACCEPT到SelectorKey) -> fireChannelRead(接收到客户端连接,此时会将客户端连接注册到workerGroup) -> fireChannelReadComplete(读取客户端连接完成) -> 接收下一个连接】 -> 直到最终关闭触发fireChannelUnregistered(从EventLoop中取消注册);
2、SocketChannel: ServerSocketChannel接收到客户端请求后,将其注册到workerGroup -> fireChannelRegistered(注册) -> fireChannelActive (激活) ->【 read(注册OP_READ到SelectorKey)->fireChannelRead(读取到数据)-> (业务数据处理) -> (write(写数据到buffer)->flush(数据最终发送) / writeAndFlush(前两个操作的组合)) -> fireChannelReadComplete(读取过程结束)】-> fireChannelInactive(连接关闭) -> fireChannelUnregistered(从EventLoop中取消注册);
Client端:
SocketChannel: fireChannelRegistered(注册到EventLoop) -> connect(连接server) -> fireChannelActive(连接成功)->【 read(注册OP_READ)->(write(写数据到buffer)->flush(数据最终发送) / writeAndFlush(前两个操作的组合)) -> fireChannelRead(读取到server传回的数据)->(业务数据处理)->fireChannelReadComplete(读取完成) 】-> fireChannelInactive(接收关闭连接的请求)-> close(关闭连接) -> fireChannelUnregistered(从EventLoop中取消注册);
上面是一个简化的监听、连接、处理、关闭流程,实际的流程会更加复杂。
总结一下,每个连接对应一个ChannelPipeline,ChannelPipeline维护了一个处理链,并提供了丰富的操作处理链的api。 处理链维护了一些列ChannelContext,其中head和tail由ChannelPipeline自己维护,用户无法修改这两个节点。每个ChannelContext包含一个ChannelHandler,所有ChannelContext是私有的线程安全的,但handler可以通过添加注解Sharable的方式来共享。ChannelPipeline提供了一系列操作TailContext和HeadContext的方法来达到处理handler的目的,但操作是由ChannelContext触发ChannelHandler完成的,而非直接操作handler。
本篇文章里原本需要配图的(直观、形象),然而冬天来了太冷了,有时间再补吧。下一篇将介绍ChannelContext。