Python源码剖析读书笔记
目录结构:
Include: 包含Python所有头文件
Lib: Python自带的所有标准库
Modules: 所有C语言编写的模块
Paser: Python解释器中Scanner和Parser部分(词法分析和语法分析)
Objects: Python所有内建对象及运行时需要的所有内部使用对象的实现
Python: Python解释器的Compiler和执行引擎(核心)
PCBuild: 工程文件
编译
$ ./configure --prefix=./GitClone/cpython/Build
$ make
$ make install
1.Python内建对象
Python世界中一切都是对象
/* PyObject_HEAD defines the initial segment of every PyObject. */
#define PyObject_HEAD \
_PyObject_HEAD_EXTRA \
Py_ssize_t ob_refcnt; \
struct _typeobject *ob_type;
/* PyObject_VAR_HEAD defines the initial segment of all variable-sizecontainer objects */
#define PyObject_VAR_HEAD \
PyObject_HEAD \
Py_ssize_t ob_size; /* Number of items in variable part 指明变长对象中容纳元素的个数*/
1.1 Python内的对象
Python中所有的内建的类型对象(int, str等对象)都是被静态初始化的对象一旦创建, 内存大小就是不变的(变长的对象内部维护一个指向可变内存的指针)
#object.h
typedef struct _object {
PyObject_HEAD
} PyObject;
#实际是一个整型引用计数, 一个类型结构体指针
typedef struct _object {
Py_ssize_t ob_refcnt; #int引用计数
struct _typeobject *ob_type;
} PyObject;
typedef struct _typeobject {
PyObject_VAR_HEAD
const char *tp_name; /* For printing, in format "<module>.<name>" */
Py_ssize_t tp_basicsize, tp_itemsize; /* For allocation 对象分配内存空间大小信息*/
/* Methods to implement standard operations */
destructor tp_dealloc;
printfunc tp_print;
getattrfunc tp_getattr;
setattrfunc tp_setattr;
cmpfunc tp_compare;
reprfunc tp_repr;
/* Method suites for standard classes */
PyNumberMethods *tp_as_number; #数值对象支持操作
PySequenceMethods *tp_as_sequence; #序列对象支持操作
PyMappingMethods *tp_as_mapping; #关联对象支持操作
/* More standard operations (here for binary compatibility) */
...
} PyTypeObject;
#通过PyType_Type(对应<type 'type'>, 被称为metaclass)来确定PyTypeObject
#用户自定义class所对应的PyTypeObject就是通过PyType_Type创建
#typeobject.c
PyTypeObject PyType_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"type", /* tp_name */
sizeof(PyHeapTypeObject), /* tp_basicsize */
sizeof(PyMemberDef), /* tp_itemsize */
(destructor)type_dealloc, /* tp_dealloc */
...
};
Python每个对象除了PyObject还保存了属于自己的特殊的信息
#变长对象
#define PyObject_VAR_HEAD \
PyObject_HEAD \
Py_ssize_t ob_size; /* Number of items in variable part 指明变长对象中容纳元素的个数*/
typedef struct {
PyObject_VAR_HEAD
} PyVarObject;
int对象类型PyInt__Type
object对象类型PyBaseObject__Type
对象创建int为例, 调用PyInt_Type中的tp_new, 若为NULL则找到基类的tp_new, 知道找到不为NULL的tp_new, tp_new指向object_new, object_new访问PyInt_Type中的tp_basicsize完成内存申请.PyInt_Type继续执行tp_init初始化
对象
多态的核心: 通过传入对象的ob_type类型确定对象的类型, 从来调用对象对应的操作.
1.1.1 引用计数
python每个对象都有一个ob_refcnt对象, 用来维持变量的引用计数.当引用计数减少到0, 调用对象对应的tp_dealloc析构.Python使用内存对象池计数, 避免频繁申请和释放内存.
#define _Py_NewReference(op) ( #初始化引用计数为1 \
_Py_INC_TPALLOCS(op) _Py_COUNT_ALLOCS_COMMA \
_Py_INC_REFTOTAL _Py_REF_DEBUG_COMMA \
Py_REFCNT(op) = 1)
#define _Py_ForgetReference(op) _Py_INC_TPFREES(op)
#define _Py_Dealloc(op) (#为0时销毁对象 \
_Py_INC_TPFREES(op) _Py_COUNT_ALLOCS_COMMA \
(*Py_TYPE(op)->tp_dealloc)((PyObject *)(op)))
#endif /* !Py_TRACE_REFS */
#define Py_INCREF(op) ( #增加对象引用计数 \
_Py_INC_REFTOTAL _Py_REF_DEBUG_COMMA \
((PyObject*)(op))->ob_refcnt++)
#define Py_DECREF(op) #减少对象引用计数, 为0时调用dealloc销毁 \
do { \
if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA \
--((PyObject*)(op))->ob_refcnt != 0) \
_Py_CHECK_REFCNT(op) \
else \
_Py_Dealloc((PyObject *)(op)); \
} while (0)
1.1.2 Python中五大对象
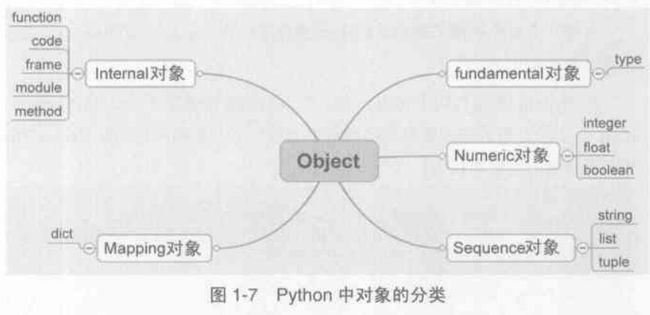
2. Python中的整数对象
2.1. PyIntOject对象
Python中的整型对象就是对C原生类型long的简单封装#intobject.h #PyIntOject创建方式 PyAPI_FUNC(PyObject *) PyInt_FromString(char*, char**, int); #ifdef Py_USING_UNICODE PyAPI_FUNC(PyObject *) PyInt_FromUnicode(Py_UNICODE*, Py_ssize_t, int); #endif PyAPI_FUNC(PyObject *) PyInt_FromLong(long); PyAPI_FUNC(PyObject *) PyInt_FromSize_t(size_t); PyAPI_FUNC(PyObject *) PyInt_FromSsize_t(Py_ssize_t);
从字符串和Py_UNICODE生成整型对象, 都是先转换为浮点数在调用PyInt_FromLong
对于小整数, 在小整数对象池中缓存PyIntOjects对象, 范围[-5, 257)
对于大整数, 提供一块内存空间供大整数轮流使用
#intoject.c
#小整数
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif
#if NSMALLNEGINTS + NSMALLPOSINTS > 0
/* References to small integers are saved in this array so that they
can be shared.
The integers that are saved are those in the range
-NSMALLNEGINTS (inclusive) to NSMALLPOSINTS (not inclusive).
*/
#大整数
#define BLOCK_SIZE 1000 /* 1K less typical malloc overhead */
#define BHEAD_SIZE 8 /* Enough for a 64-bit pointer */
#define N_INTOBJECTS ((BLOCK_SIZE - BHEAD_SIZE) / sizeof(PyIntObject))
struct _intblock {
struct _intblock *next;
PyIntObject objects[N_INTOBJECTS];
};
typedef struct _intblock PyIntBlock;
static PyIntBlock *block_list = NULL;
static PyIntObject *free_list = NULL;
PyIntBlock单项列表通过block_list维护, 每个block中维护一个PyIntObject数组objects, 通过单项链表指针free_list指向空闲内存头部
2.1.1. 添加和删除
如果小整数对象池被激活, 则尝试使用小整数对象池否则, 使用通用的整数对象池
#intojects.c
PyObject * PyInt_FromLong(long ival)
{
register PyIntObject *v; #尝试使用小整数对象池
#if NSMALLNEGINTS + NSMALLPOSINTS > 0
if (-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS) {
v = small_ints[ival + NSMALLNEGINTS];
Py_INCREF(v); #引用计数加一
#ifdef COUNT_ALLOCS
if (ival >= 0)
quick_int_allocs++;
else
quick_neg_int_allocs++;
#endif
return (PyObject *) v;
}
#endif #为通用整数对象池申请新的内存空间
if (free_list == NULL) {
if ((free_list = fill_free_list()) == NULL)
return NULL;
}
/* Inline PyObject_New */
v = free_list; #通过free_list找到空闲的内存
free_list = (PyIntObject *)Py_TYPE(v);
PyObject_INIT(v, &PyInt_Type);
v->ob_ival = ival;
return (PyObject *) v;
}
总结: 对于小整数, 会直接使用固定的小整数对象池, 对使用的对象引用计数加一, 对于非小整数, 通过free_list获得空闲内存来创建对象, 若为NULL表示用完或者初次创建, 会调用fill_free_list函数来创建新的空闲内存, 并且在引用计数为零时, 将对象销毁, 这块内存会重新加入到free_list中被使用.
3. Python中的字符串对象
定长对象和变长对象区别在于数据的长度是否在对象创建时就已经确定(内存长度). 简单的判断方式结构体是否有PyObject_VAR_HEAD宏(其中ob_size表示内存长度)可变对象和不可变对象的区别在于对象被创建后是否还能够变化
PyStringObject是对字符串对象的实现, 是拥有可变长度内存的对象, PyStringObject是一个变长对象且是不可变对象
3.1. PyStringObject和PyString_Type
PyStringObject对象定义#stringobject.h
typedef struct {
PyObject_VAR_HEAD
long ob_shash; #缓存对象的hash值, 初始-1, string_hash计算哈希
int ob_sstate;
char ob_sval[1]; #实际作为一个字符指针指向一段内存, 这段内存保存着字符串所维护的实际字符串
} PyStringObject;
PyStringObject对一个的类型对象PyString_Type
#stringobject.c
PyTypeObject PyString_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"str",
PyStringObject_SIZE,
sizeof(char), #指明变长对象保存的元素的单位长度
string_dealloc, /* tp_dealloc */
(printfunc)string_print, /* tp_print */
...
string_repr, /* tp_repr */
&string_as_number, /* tp_as_number */
&string_as_sequence, /* tp_as_sequence */
&string_as_mapping, /* tp_as_mapping */
(hashfunc)string_hash, /* tp_hash */
...
};
3.2. 创建PyStringOject对象
#stringobject.c
PyObject *
PyString_FromString(const char *str)
{
register size_t size;
register PyStringObject *op;
assert(str != NULL);
size = strlen(str); #获得字符串长度
if (size > PY_SSIZE_T_MAX - PyStringObject_SIZE) {
PyErr_SetString(PyExc_OverflowError,
"string is too long for a Python string");
return NULL;
}
if (size == 0 && (op = nullstring) != NULL) { #处理null string
#ifdef COUNT_ALLOCS
null_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
if (size == 1 && (op = characters[*str & UCHAR_MAX]) != NULL) { #处理字符
#ifdef COUNT_ALLOCS
one_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
/* Inline PyObject_NewVar 创建新的对象, 并初始化 */
op = (PyStringObject *)PyObject_MALLOC(PyStringObject_SIZE + size);
if (op == NULL)
return PyErr_NoMemory();
PyObject_INIT_VAR(op, &PyString_Type, size);
op->ob_shash = -1;
op->ob_sstate = SSTATE_NOT_INTERNED;
Py_MEMCPY(op->ob_sval, str, size+1);
/* share short strings */
if (size == 0) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
nullstring = op;
Py_INCREF(op);
} else if (size == 1) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
characters[*str & UCHAR_MAX] = op;
Py_INCREF(op);
}
return (PyObject *) op;
}
还有一种创建方法PyString_FromStringAndSize, 两者区别在于前者要求字符串以\0结尾, 后者要传入size长度
3.3. 字符串对象的intern机制
PyString_InternInPlace(&t);表示intern机制一个被intern后的字符串, 在python运行期中, 只有唯一一个对应的字符串, 在判断两个字符喘对象是否相同时, 如果都被intern了, 值需要检查对应的PyObject *是否相同, 这个机制节省空间, 并简化了字符串对象的比较
也就是说, intern机制对相同的字符串只会占用一块内存, 每次创建字符串会先查找相同字符串是否已经存在, 存在就返回对象的引用, 重要的是一点, 字符串对象是先被创建, 然后才调用intern机制, 创建的对象相当于临时对象, 在intern机制成功时, 马上因引用计数为0被销毁
intern机制(pystring_interninplace):
检查是否为PyStringObject对象
检查对象是否被intern机制处理过
系统使用一个字典保存映射关系
当对象a应用intern机制, 检查字典是否有符合条件的对象b, 若有, a的PyObject *指针指向b, a的引用计数减一
没有符合的则将a记录到interned中
3.4. 字符缓冲池
对于字符对象:创建PyStringObject对象
对对象进行intern操作
将对象缓存到字符串缓冲池中
由于字符串对象是不可变对象, 不推荐使用+操作(会不断创建新的中间对象, 不断申请内存), 推荐将字符串存入list或tuple, 使用join方法(只申请一次内存)
4. Python中的list对象
python中的list(vector<PyOject *>)与STL中的vector类似list是一个变长对象(结构体包含PyObject_VAR_HEAD)和可变对象
4.1. PyListObject对象
typedef struct {
PyObject_VAR_HEAD #ob_size表示使用中的内存
/* Vector of pointers to list elements. list[0] is ob_item[0], etc.
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
*/
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number currently in use is ob_size. */
Py_ssize_t allocated; #记录申请的总内存大小
} PyListObject;
4.2. PyListObject对象的创建与维护
#listobject.c
#define PyList_MAXFREELIST 80
PyObject *
PyList_New(Py_ssize_t size) #指定元素个数, 不是内存大小
{
PyListObject *op;
size_t nbytes;
#ifdef SHOW_ALLOC_COUNT
static int initialized = 0;
if (!initialized) {
Py_AtExit(show_alloc);
initialized = 1;
}
#endif
if (size < 0) {
PyErr_BadInternalCall();
return NULL;
}
/* Check for overflow without an actual overflow,
* which can cause compiler to optimise out 内存数量计算, 溢出检查*/
if ((size_t)size > PY_SIZE_MAX / sizeof(PyObject *))
return PyErr_NoMemory();
nbytes = size * sizeof(PyObject *);
if (numfree) { #缓冲池可用
numfree--;
op = free_list[numfree];
_Py_NewReference((PyObject *)op);
#ifdef SHOW_ALLOC_COUNT
count_reuse++;
#endif
} else { #缓冲池不可用
op = PyObject_GC_New(PyListObject, &PyList_Type);
if (op == NULL)
return NULL;
#ifdef SHOW_ALLOC_COUNT
count_alloc++;
#endif
}
if (size <= 0) #为PyListObject对象中维护的元素列表申请空间
op->ob_item = NULL;
else {
op->ob_item = (PyObject **) PyMem_MALLOC(nbytes);
if (op->ob_item == NULL) {
Py_DECREF(op);
return PyErr_NoMemory();
}
memset(op->ob_item, 0, nbytes);
}
Py_SIZE(op) = size;
op->allocated = size;
_PyObject_GC_TRACK(op);
return (PyObject *) op;
}
PyListObject对象创建分为两部分, 对象本身和对象维护的元素列表,他们通过ob_item建立联系.完成两者创建会调用对象用于维护ob_size和allocated变量, 创建对象时, 如果numfree为0, 会绕过对象缓冲池在堆上创建新的对象
设置元素调用PyList_SetItem不会导致内存变量, 插入元素调用PyList_Insert可能导致ob_item指向的内存变量, 附加元素调用PyList_Append, 删除元素调用listremove(实际内部执行了list_ass_slice函数)会触发内存搬移的工作
static int ins1(PyListObject *self, Py_ssize_t where, PyObject *v)
{
Py_ssize_t i, n = Py_SIZE(self);
PyObject **items;
if (v == NULL) {
PyErr_BadInternalCall();
return -1;
}
if (n == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"cannot add more objects to list");
return -1;
}
if (list_resize(self, n+1) == -1) #调整列表容量realloc
return -1;
if (where < 0) { #确定插入点 为负的时候
where += n;
if (where < 0)
where = 0;
}
if (where > n) #大于容量时
where = n;
items = self->ob_item;
for (i = n; --i >= where; ) #元素后移
items[i+1] = items[i];
Py_INCREF(v);
items[where] = v; #插入元素
return 0;
}
4.3. PyListObject对象缓冲池
static void list_dealloc(PyListObject *op)
{
Py_ssize_t i;
PyObject_GC_UnTrack(op);
Py_TRASHCAN_SAFE_BEGIN(op)
if (op->ob_item != NULL) { #销毁元素列表
/* Do it backwards, for Christian Tismer.
There's a simple test case where somehow this reduces
thrashing when a *very* large list is created and
immediately deleted. */
i = Py_SIZE(op);
while (--i >= 0) {
Py_XDECREF(op->ob_item[i]); #减少引用计数
}
PyMem_FREE(op->ob_item);
}
if (numfree < PyList_MAXFREELIST && PyList_CheckExact(op)) #销毁list对象自身, 先查看缓冲池是否满了, 没满就放入缓冲池
free_list[numfree++] = op;
else
Py_TYPE(op)->tp_free((PyObject *)op);
Py_TRASHCAN_SAFE_END(op)
}
缓冲的仅仅是PyListObject对象, 不包含维护的元素列表
5. Python中Dict对象
关联式容器元素通常以key-value形式存在,PyDictObject采用了散列表(hash table),5.1. PyDictObject
Python中哈希表使用开放定址法处理冲突, 删除时使用伪删除操作#dictobject.h
typedef struct {
/* Cached hash code of me_key. Note that hash codes are C longs.
* We have to use Py_ssize_t instead because dict_popitem() abuses
* me_hash to hold a search finger.
*/
Py_ssize_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictEntry;
python中dict什么都能装下, 是因为Pyobject *相当于void *.
dict中entry三态:
Unused: 未存储key-value, 每个entry的初始状态, me_key和me_value为NULL
Active: 存储了key-value,me_key和me_valu都不能为NULL,me_key不能为dummy对象
Dummy: 当entry中存储的key-value被删除后, me_key指向dummy对象, entry进入Dummy
关联容器的实现
5.2. PyDictObject的创建和维护
PyObject *PyDict_New(void)
{
register PyDictObject *mp;
if (dummy == NULL) { /* Auto-initialize dummy, 是一个字符串对象PyString_FromString */
dummy = PyString_FromString("<dummy key>");
if (dummy == NULL)
return NULL;
#ifdef SHOW_CONVERSION_COUNTS
Py_AtExit(show_counts);
#endif
#ifdef SHOW_ALLOC_COUNT
Py_AtExit(show_alloc);
#endif
#ifdef SHOW_TRACK_COUNT
Py_AtExit(show_track);
#endif
}
if (numfree) { #使用缓冲池
mp = free_list[--numfree];
assert (mp != NULL);
assert (Py_TYPE(mp) == &PyDict_Type);
_Py_NewReference((PyObject *)mp);
if (mp->ma_fill) {
EMPTY_TO_MINSIZE(mp);
} else {
/* At least set ma_table and ma_mask; these are wrong
if an empty but presized dict is added to freelist */
INIT_NONZERO_DICT_SLOTS(mp);
}
assert (mp->ma_used == 0);
assert (mp->ma_table == mp->ma_smalltable);
assert (mp->ma_mask == PyDict_MINSIZE - 1);
#ifdef SHOW_ALLOC_COUNT
count_reuse++;
#endif
} else { #创建新的PyDictObject对象
mp = PyObject_GC_New(PyDictObject, &PyDict_Type);
if (mp == NULL)
return NULL;
EMPTY_TO_MINSIZE(mp);
#ifdef SHOW_ALLOC_COUNT
count_alloc++;
#endif
}
mp->ma_lookup = lookdict_string; #包含了哈希函数和冲突函数的实现
#ifdef SHOW_TRACK_COUNT
count_untracked++;
#endif
#ifdef SHOW_CONVERSION_COUNTS
++created;
#endif
return (PyObject *)mp;
}
/*将ma_smalltable清零, 同时设置ma_used和ma_fill*/
#define EMPTY_TO_MINSIZE(mp) do { \
memset((mp)->ma_smalltable, 0, sizeof((mp)->ma_smalltable)); \
(mp)->ma_used = (mp)->ma_fill = 0; \
INIT_NONZERO_DICT_SLOTS(mp); \
} while(0)
/*将ma_table指向ma_samlltable, 并设置ma_mask为7*/
#define INIT_NONZERO_DICT_SLOTS(mp) do { \
(mp)->ma_table = (mp)->ma_smalltable; \
(mp)->ma_mask = PyDict_MINSIZE - 1; \
} while(0)
python中提供了lookdict和lookdict_string(key多为字符串, 所以作为默认搜索方法, 两者使用相同的算法)
static PyDictEntry *lookdict(PyDictObject *mp, PyObject *key, register long hash)
{
register size_t i;
register size_t perturb;
register PyDictEntry *freeslot;
register size_t mask = (size_t)mp->ma_mask;
PyDictEntry *ep0 = mp->ma_table;
register PyDictEntry *ep;
register int cmp;
PyObject *startkey;
i = (size_t)hash & mask; #哈希, 定位第一个entry
ep = &ep0[i]; #entry处理Unused或者entry中key匹配
if (ep->me_key == NULL || ep->me_key == key)
return ep;
if (ep->me_key == dummy) #第一个entry的key为dummy状态
freeslot = ep; #freeslot指向第一个处于Dummy的entry
else { #检查Active的entry
if (ep->me_hash == hash) {
startkey = ep->me_key;
Py_INCREF(startkey);
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
if (cmp < 0)
return NULL;
if (ep0 == mp->ma_table && ep->me_key == startkey) {
if (cmp > 0)
return ep;
}
else {
/* The compare did major nasty stuff to the
* dict: start over.
* XXX A clever adversary could prevent this
* XXX from terminating.
*/
return lookdict(mp, key, hash);
}
}
freeslot = NULL;
}
/* In the loop, me_key == dummy is by far (factor of 100s) the
least likely outcome, so test for that last. */
for (perturb = hash; ; perturb >>= PERTURB_SHIFT) {
i = (i << 2) + i + perturb + 1;
ep = &ep0[i & mask];
if (ep->me_key == NULL) #到达Unused状态entry,搜索失败
return freeslot == NULL ? ep : freeslot;
if (ep->me_key == key) #检查是否引用相同
return ep;
if (ep->me_hash == hash && ep->me_key != dummy) { #检查值是否相同
startkey = ep->me_key;
Py_INCREF(startkey);
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
if (cmp < 0)
return NULL;
if (ep0 == mp->ma_table && ep->me_key == startkey) {
if (cmp > 0)
return ep;
}
else {
/* The compare did major nasty stuff to the
* dict: start over.
* XXX A clever adversary could prevent this
* XXX from terminating.
*/
return lookdict(mp, key, hash);
}
}
else if (ep->me_key == dummy && freeslot == NULL) #设置freeslot
freeslot = ep;
}
assert(0); /* NOT REACHED */
return 0;
}
For both, when the key isn’t found a PyDictEntry* is returned for which the me_value field is NULL
第一阶段: 判断冲突探测链上第一个entry的key与待查找key是否匹配
第二阶段: 若不匹配, 再一次比较探测脸上的entry与带查找key
插入函数insertdict
先调用PyDict_SetItem获得hash只(必要时会调整dict的内存空间)
搜索成功, 返回Active的entry, 然后替换me_value
搜索失败, 返回Unused或者Dummy的entry, 完整设置key-value
改变ma_table大小由dictresize完成
/*
Restructure the table by allocating a new table and reinserting all
items again. When entries have been deleted, the new table may
actually be smaller than the old one.
*/
static int dictresize(PyDictObject *mp, Py_ssize_t minused)
{
Py_ssize_t newsize;
PyDictEntry *oldtable, *newtable, *ep;
Py_ssize_t i;
int is_oldtable_malloced;
PyDictEntry small_copy[PyDict_MINSIZE];
assert(minused >= 0);
/* Find the smallest table size > minused. 确定新table的大小 */
for (newsize = PyDict_MINSIZE;
newsize <= minused && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
/* Get space for a new table. */
oldtable = mp->ma_table;
assert(oldtable != NULL);
is_oldtable_malloced = oldtable != mp->ma_smalltable;
if (newsize == PyDict_MINSIZE) { #新table可以使用mp->ma_smalltable
/* A large table is shrinking, or we can't get any smaller. */
newtable = mp->ma_smalltable;
if (newtable == oldtable) {
if (mp->ma_fill == mp->ma_used) {
/* No dummies, so no point doing anything. */
return 0;
}
/* We're not going to resize it, but rebuild the
table anyway to purge old dummy entries.
Subtle: This is *necessary* if fill==size,
as lookdict needs at least one virgin slot to
terminate failing searches. If fill < size, it's
merely desirable, as dummies slow searches. */
assert(mp->ma_fill > mp->ma_used);
memcpy(small_copy, oldtable, sizeof(small_copy)); #将旧table拷贝, 进行备份
oldtable = small_copy;
}
}
else { #新table需要在系统堆上申请
newtable = PyMem_NEW(PyDictEntry, newsize);
if (newtable == NULL) {
PyErr_NoMemory();
return -1;
}
}
/* Make the dict empty, using the new table. */
assert(newtable != oldtable);
mp->ma_table = newtable;
mp->ma_mask = newsize - 1;
memset(newtable, 0, sizeof(PyDictEntry) * newsize);
mp->ma_used = 0;
i = mp->ma_fill;
mp->ma_fill = 0;
/* Copy the data over; this is refcount-neutral for active entries;
dummy entries aren't copied over, of course */
for (ep = oldtable; i > 0; ep++) {
if (ep->me_value != NULL) { /* active entry */
--i;
insertdict_clean(mp, ep->me_key, (long)ep->me_hash,
ep->me_value);
}
else if (ep->me_key != NULL) { /* dummy entry */
--i;
assert(ep->me_key == dummy);
Py_DECREF(ep->me_key);
}
/* else key == value == NULL: nothing to do */
}
if (is_oldtable_malloced)
PyMem_DEL(oldtable);
return 0;
}
确定新table的大小
如果新table大小为8, 不需要在堆上分配空间, 使用ma_smalltabel, 否则在堆上分配空间
新table初始化
对非Unused处理, Active插入到新表,Dummy丢弃
如果旧table指向系统堆内存, 需要释放内存
删除流程PyDict_DelItem
计算hash
搜索entry
删除entry中的元素, 并将Active置为Dummy态
调整维护table使用情况的变量
5.3. PyDictObject对象缓冲池
类似于PyListObject缓冲池机制, 初始缓冲池空, 直到第一个PyDictObject销毁, 缓冲池才开始接纳被缓冲的PydictObject对象#ifndef PyDict_MAXFREELIST
#define PyDict_MAXFREELIST 80
#endif
static PyDictObject *free_list[PyDict_MAXFREELIST];
static int numfree = 0;
static void dict_dealloc(register PyDictObject *mp)
{
register PyDictEntry *ep;
Py_ssize_t fill = mp->ma_fill;
PyObject_GC_UnTrack(mp);
Py_TRASHCAN_SAFE_BEGIN(mp)
#调整dict中对象引用计数
for (ep = mp->ma_table; fill > 0; ep++) {
if (ep->me_key) {
--fill;
Py_DECREF(ep->me_key);
Py_XDECREF(ep->me_value);
}
}
if (mp->ma_table != mp->ma_smalltable)
PyMem_DEL(mp->ma_table); #释放table指向的堆内存
if (numfree < PyDict_MAXFREELIST && Py_TYPE(mp) == &PyDict_Type)
free_list[numfree++] = mp; #销毁的对象放入缓冲池
else
Py_TYPE(mp)->tp_free((PyObject *)mp);
Py_TRASHCAN_SAFE_END(mp)
}