我的高性能计算之旅
考完试后,开始接触一些高性能计算方面的东西,学校也给分配了一个小集群(8计算结点,4cpu/结点,centOS6.0)帐号提供实验环境。
27号开始玩超级计算机到今天刚好是第五天,收获颇丰。特别是28号安装配置好paramon后,成功的调好了pbs脚本在单结点4cpu上运行NAMD。
用paramon监测到了自己提交的作业运行情况,如下图所示。
其中5号结点显示的就是自己提交的任务的运行情况,浅绿色部分表示的是cpu可用计算,亮绿色部分则表示实际cpu计算情况,两者之比即为cpu效率。cpu效率越高越好,可以看出自己的compute-0-5是效率最高的。
第一次使用paramon实时监控,看到自己程序运行的效率最高,太尼马开心了。瞬间有种超级计算机太好玩了,~^_^~,有没有!……之前都还只能在命令行下查看提交作业情况,还TM不知道运行效率,做什么优化显然都只是一头雾水啊。现在可以不仅能观测到自己程序运行情况还能看到其他人,还能进行比较。不得不说,paramon这个软件实在是太好用了,有种相见恨晚的赶脚。
大型应用的优化主要有以下几个方面:
- 源码级优化(大量修改代码甚至改算法)
- 编译时优化(编译器选择,编译参数选择)
- 运行时优化(MPI通信多结点运行)
第一次玩超算,纯新手啊(摔!),刚开始连ssh是什么都不知道。
任务:本次任务有两个(二选一),优化Griding和namd,时间12天。听报告时留意到,Griding要读懂代码,理解算法,听老师很轻飘的说:才300行嘛(跪了,才!300!);而namd只用安装运行算例就行。简单思考了下,并行程序啥都不懂还想去读懂代码,优化算法,这不找死么。果断拿namd开刀,先熟悉linux与并行计算环境,把必要的工具掌握好。
思路:自己的思路还算清晰,想先用编译好的程序,在单机上运行,再扩展到多节点并行,最后解决比较苦难的从头编译安装。
到官网曲下载NAMD分子动力模拟软件时,稀里糊涂的就下载了一个单机版(巨坑,后来想扩展到多节点运行时,浪费了大半天找错误,最后才发现当初下的是单机版的(;´༎ຶД༎ຶ`))。
核心问题:(自己归纳问题能力立马上升一个档次)
问题 耗费时间
- namd运行算例时间如何测定? (1天左右吧。后来发现,居然在输出文件里有cpu时间(。◕‿◕。))
- namd多核心运行? (一个小时。看完文档立马理解,加个参数OK搞定!ლ(╹◡╹ლ))
- namd源码编译运行? (一夜。打印官方文档,流程反复看几遍,按着文档操作,不仅解决了源码编译问题,连下一个多节点运行问题都解决了,激动!刺激!(ง •̀_•́)ง)
- 如何多节点跑namd? (三天。这个坑到最后放弃。查错误原因时连官方mali list都翻了个遍。中途为了深入理解,只要是遇到没见过的概念事物就搜一遍,结果是连写5篇博客记录问题和学到知识_(:з」∠)_)
- 单机:看官网给的说明文档后一下子就理解了单机上的运行流程。单线程400s可以跑完算例,四线程200s就够了,算得上自己首次优化成功案例吧。
- 多节点:好不容易发现下载的是单机版,改下多节点版的吧,又遇到rsh连通不到计算结点,节点间无法通信。还给管理员发了份邮件让他改配置文件。不给改。跪了,只好放弃,从源码编译起,哪知柳暗花明又一村,顺带解决了。7结点28线程仅用36s。

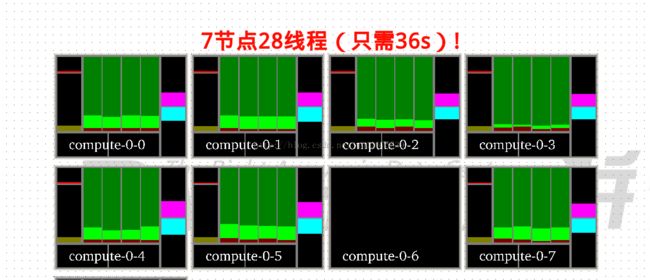
子问题:
- time(qusb my.pbs)统计qsub命令执行时间,一般都是瞬间完成,二time (./exe)则会在登录节点跑程序。不允许在登录结点跑,而又需要知道程序运行时间,如何解决?(尚未解决)
- NAND跨节点并行时,没有消息的发送和接受?(原因尚未知,重新编译源码后解决)