我们知道,Storm保证发出的每条消息都能够得到完全处理,也就是说,对于从Spout发出的每个tuple,该tuple和其产生的所有tuple(整棵tuple树)都被成功处理。如果在应用设定的超时时间之内,这个tuple没有处理成功,则认为这个tuple处理失败了。tuple处理成功还是失败,Storm又是怎么知道的呢?
原来Storm中有一类叫Acker的task,它会对tuple树进行跟踪,并检测相应的spout tuple是否处理完成了。当一个tuple被创建时,不管是在Spout还是Bolt中创建,它都会被赋予一个tuple-id(随机生成的64位数字),这些tuple-id就是Acker用来跟踪每个spout tuple产生的tuple树的。如果一个spout tuple被完全处理了,它会给创建这个spout tuple的那个task发送一个成功消息,否则发送一个失败消息。
在Spout创建一个新tuple时,会生成一个root-id(也是随机的64位数字),并且这个root-id会传递给这个spout tuple所生成的tuple树中的每个tuple,因此有了这个root-id,我们就可以追踪这棵tuple树了。如果一个tuple被完全处理了,Storm就会调用Spout对应task的ack方法;否则调用Spout对应的fail方法。每个tuple都必须被ack或者fail,因为Storm追踪每个tuple需要占用内存,如果你不ack或fail每一个tuple, 那么最终会导致OOM(OutOfMemory)。
Acker跟踪算法的基本思想是:对于从Spout发射出来的每个spout tuple,Acker都保存了一个ack-val(校验值),初始值为0,每当tuple被创建或被ack,这些对应tuple的tuple-id(随机生成的64位整数)都会在某个时刻和保存的ack-val进行按位异或运算,并用异或运算的结果更新ack-val。如果每个spout tuple对应tuple树中的每个tuple都被成功处理,那最终的ack-val必然为0。为何呢?因为在这个过程中,同一个tuple-id都会被异或两次,而相同值的异或运算结果为0,且异或运算满足结合律,如a^a=0,a^b^a^b=(a^a)^(b^b)=0。
如图1所示,Acker为了实现自己的跟踪算法,它会维护这样一个数据结构:
{root-id {:spout-task task-id :val ack-val :failed bool-val …}}
其实就是一个Map,从上面这个Map中,我们知道,一个Acker存储了一个root-id到一对值的映射关系。这对值的第一个是创建这个tuple的task-id,当这个tuple处理完成进行ack的时候会用到。第二个是一个随机的64位的数字,即ack-val,ack-val表示整棵tuple树的状态,不管这棵tuple树多大,它只是简单地把这棵树上的相应的tuple-id做按位异或运算。因此即使一个spout tuple生成一棵有成千上万tuple的tuple树,Acker进行跟踪时也不会耗费太多的内存,对于每个spout tuple,Acker所需要的内存量都是恒定的20字节。这也是Storm的主要突破。
Acker跟踪算法需要不断更新ack-val,那ack-val又是怎么更新的呢?其实主要就是如下3个环节:
1)Spout创建新tuple的时候会给Acker发送消息。
2)Bolt中的tuple被ack的时候给Acker发送消息。
3)Acker根据接收到的消息做按位异或运算,更新自己的ack-val。
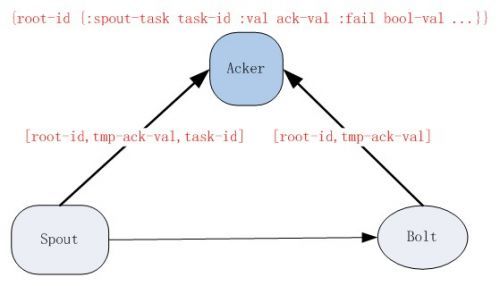
图1
当Spout创建了一个新的tuple时,会发送消息给Acker,消息的格式为[root-id,tmp-ack-val,task-id],Acker会根据这个tmp-ack-val更新自己维护的Map中的ack-val值。
在Storm中,当一个spout tuple被完全处理后,会调用Spout中的task的ack或者fail方法,而且这个task必须是创建这个tuple的task。也就是说,如果一个Spout中启动了多个task,消息处理成功还是失败,最终都会通知Spout中发出tuple的那个对应的task。但Acker是如何知道每个spout tuple是由哪个task创建的呢?
从上面Spout给Acker发送的消息格式即可知道,Spout中创建一个新tuple时,它会创建这个tuple的task的task-id告诉Acker,于是当Acker发现一棵tuple树完成处理时,它知道给Spout中的哪个task发送成功消息,或者在处理失败时发送失败消息。
当一个tuple在Bolt中被ack的时候,它也会给Acker发送一个消息,告诉它这棵tuple树发生了什么样的变化。具体来说就是,它告诉Acker,在这棵tuple树中,我这个tuple已经完成了, 但我生成了这些新的tuple,并让Acker去跟踪一下它们。tuple被ack时发送给Acker的消息格式为[root-id,tmp-ack-val],Acker会根据这个tmp-ack-val更新自己的ack-val值,当检测到ack-val为0时,就表示一个spout tuple被完全处理了。
在Topology中,Acker的个数我们是可以自己设置的。既然Acker可能有多个,那么当一个tuple需要被ack的时候,它怎么知道选择哪个Acker来发送这个消息呢?
Storm使用mod hashing将一个spout tuple的root-id映射到一个Acker,因为同一棵tuple树中的所有tuple都保存了相同的root-id,那么当一个tuple被ack的时候,它自然就知道应该给哪个Acker发送消息了。
下面我们结合一个具体的例子来揭开Acker实现机制的神秘面纱。这个例子的功能很简单,Spout从外界消息队列中获取句子,Bolt1接收从Spout中发送过来的句子并拆分成单词,其它Bolt(如下图中的Bolt2和Bolt3)会对相应的单词个数做统计。
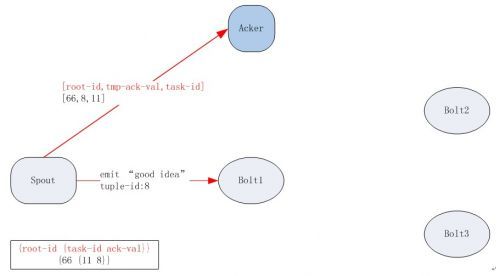
图2-1
在图2-1中,Spout创建了一个新的tuple,于是它发消息给Acker,消息内容为[66,8,11],其中66为这个tuple对应的root-id,8为这个tuple的tuple-id,11为创建这个tuple的task的task-id。Acker接收到这条消息后更新自己维护的数据结构,更新后为{66 {11 8}}(见图左下角),即root-id为66,task-id为11,ack-val为8。
Spout创建新tuple时给Acker发送消息对应的代码如下:
;;当Spout创建了一个新的tuple时,会发送消息给Acker,让Acker对这个新的tuple进行跟踪
;;创建这个tuple的task的id是task-id,后面会根据这个task-id通知task其创建的tuple处理成功还是失败
rooted? (and message-id has-ackers?)
;生成一个随机的64位root-id
root-id (if rooted? (MessageId/generateId rand))
;out-ids为对应同一个root-id的所有spout tuple的tuple-id集合
out-ids (fast-list-for [t out-tasks] (if rooted? (MessageId/generateId rand)))]
(fast-list-iter [out-task out-tasks id out-ids]
(let [tuple-id (if rooted?
(MessageId/makeRootId root-id id)
(MessageId/makeUnanchored))]
(transfer-fn out-task
(TupleImpl. worker-context
values
task-id
out-stream-id
tuple-id))))
;Spout创建一个新tuple时给Acker发送消息
(if rooted?
(do
;在pending这个RotatingMap中put一条对应的记录
(.put pending root-id [task-id
message-id
{:stream out-stream-id :values values}
(if (sampler) (System/currentTimeMillis))])
;将out-ids集合中所有tuple-id的异或值发送给Acker
(task/send-unanchored task-data
;spout tuple对应task发给Acker消息的stream-id为"__ack_init"
ACKER-INIT-STREAM-ID
;Spout发射这个新tuple时,给Acker发送消息的的格式为[root-id,tmp-ack-val,task-id]
[root-id (bit-xor-vals out-ids) task-id]))
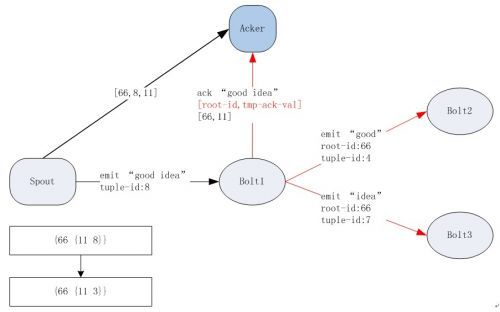
图2-2
在图2-2中,Bolt1将”good idea”这个输入tuple拆分成”good”和”idea”两个输出tuple,处理完后它给Acker发送消息[66,11]。我们知道66是root-id,但这个11是怎么计算出来的呢?在Storm的实现中,首先会将这个输入tuple生成的所有输出tuple的tuple-id进行异或运算,这里两个输出tuple的tuple-id分别为4和7,4 XOR 7 = 3;然后再将这个结果和输入tuple的tuple-id进行异或,输入tuple的tuple-id为8,即3 XOR 8 = 11。因此它发送Acker的消息为[66,11]。Acker接收到这个消息后更新自己的ack-val,8 XOR 11 = 3,更新后Acker维护的数据结构变为{66 {11 3}}。
tuple被ack时Bolt给Acker发送消息对应的代码如下:
;对tuple进行ack
(^void ack [this ^Tuple tuple]
;获取tuple的_outAckVal值(这个tuple的所有输出tuple的tuple-id的异或结果),赋给ack-val
;ack-val = out-tuple-id1 ^ out-tuple-id2 ^ out-tuple-id3 …
(let [^TupleImpl tuple tuple
ack-val (.getAckVal tuple)]
;调用tuple.getMessageId.getAnchorsToids()获取root-id到ack-val的映射关系{root-id ack-val}
;对这个tuple的每个spout tuple进行ack,将这个tuple的tuple-id与其所有输出tuple的tuple-id的异或结果发送给Acker
;tuple-id ^ ack-val,即 tuple-id ^ (out-tuple-id1 ^ out-tuple-id2 ^ out-tuple-id3 …)
(fast-map-iter [[root id] (.. tuple getMessageId getAnchorsToIds)]
(task/send-unanchored task-data
;Bolt中ack消息的stream-id为"__ack_ack"
ACKER-ACK-STREAM-ID
;这个tuple被ack时,给Acker发送消息的的格式为[root-id,tmp-ack-val]
[root (bit-xor id ack-val)])
从代码中我们知道一个输入tuple直接获取到其所有输出tuple的tuple-id的异或结果,然后和自己的tuple-id进行异或。那么这些输出tuple的tuple-id的异或结果计算逻辑又是怎么实现的呢?
从代码中我们可以得到答案:
;anchors-to-ids保存了root-id到tmp-ack-val的映射关系
;{root-id tmp-ack-val}
(let [anchors-to-ids (HashMap.)]
;;这里的计算是针对单个输出tuple,做一个两层的循环
;;1)遍历这个tuple的所有输入tuple(anchors),做如下两步操作:
;;a)更新这个tuple的输入tuple对应的输出tuple的tuple-id异或结果
;;b)遍历所有的root-id(root-ids),获取对应的tmp-ack-val,与输入tuple的tuple-id做XOR运算,
;; 并更新anchors-to-ids这个Map
;遍历这个tuple的所有输入tuple(anchors)
(fast-list-iter [^TupleImpl a anchors]
;调用tuple.getMessageId.getAnchorsToIds.keySet(),获取这个输入tuple对应的所有的root-id(root-ids)
(let [root-ids (-> a .getMessageId .getAnchorsToIds .keySet)]
;遍历所有的root-id(root-ids)
(when (pos? (count root-ids))
;生成一个随机的64位数字,赋给edge-id
(let [edge-id (MessageId/generateId rand)]
;更新输入tuple的_outAckVal值(_outAckVal ^ edge-id),_outAckVal的初始值为0
;最终该输入tuple的 _outAckVal = out-tuple-id1 ^ out-tuple-id2 ^ out-tuple-id3 …
(.updateAckVal a edge-id)
;遍历遍历所有的root-id(root-ids),将edge-id与对应的tmp-ack-val做XOR运算,并更新anchors-to-ids这个Map中对应的元素
(fast-list-iter [root-id root-ids]
;put-xor参考定义
(put-xor! anchors-to-ids root-id edge-id))
))))
代码中的两层循环是由于一个输出tuple可对应多个输入tuple,而一个输入tuple又可对应多个不同root-id的spout tuple,从而形成一个tuple DAG,而且从代码中可以看出,对于一个输出tuple可能会生成多个不同的tuple-id,分别对应不同的输入tuple,也对应不同的root-id。
put-xor定义:
;根据传进来的root-id和tuple-id,做XOR运算,更新pending中tmp-ack-val
;pending是{root-id tmp-ack-val}这样一个map
(defn put-xor! [^Map pending key id]
;获取root-id对应的tmp-ack-val,若pending中不存在对应的root-id,则将tmp-ack-val置为0
(let [curr (or (.get pending key) (long 0))]
;将tmp-ack-val和传进来的tuple-id进行XOR运算,并更新tmp-ack-val值,然后更新pending中对应的元素
(.put pending key (bit-xor curr id))))
Acker更新自己ack-val并根据结果给Spout对应的task发送消息,代码实现在acker.clj中:
(defn mk-acker-bolt []
(let [output-collector (MutableObject.)
pending (MutableObject.)]
(reify IBolt
(^void prepare [this ^Map storm-conf ^TopologyContext context ^OutputCollector collector]
(.setObject output-collector collector)
;创建一个numBuckets=2的RotatingMap对象
(.setObject pending (RotatingMap. 2))
)
;处理的Tuple对象包含它来自于哪个component/stream/task的元数据。
(^void execute [this ^Tuple tuple]
;pending为RotatingMap,key为root-id,value为一个Map
;{root-id {:spout-task task-id :val ack-val :failed bool-val …}}
(let [^RotatingMap pending (.getObject pending)
;获取这个tuple对应的stream-id
stream-id (.getSourceStreamId tuple)]
(if (= stream-id Constants/SYSTEM_TICK_STREAM_ID)
(.rotate pending)
;这里的id其实就是root-id
(let [id (.getValue tuple 0)
^OutputCollector output-collector (.getObject output-collector)
;curr为RotatingMap中的value,类型为Map
;{:spout-task task-id :val ack-val :failed bool-val …}
curr (.get pending id)
;对消息的stream-id类型进行判断,根据不同的类型做相应的处理
curr (condp = stream-id
;对Spout创建新的tuple时发送的消息给进行处理
ACKER-INIT-STREAM-ID (-> curr
(update-ack (.getValue tuple 1))
(assoc :spout-task (.getValue tuple 2)))
;处理Bolt中tuple被ack发送的消息,更新curr中ack-val的值
ACKER-ACK-STREAM-ID (update-ack curr (.getValue tuple 1))
;设置curr中:failed对应的value为true,即将对应的spout tuple状态标记为failed
ACKER-FAIL-STREAM-ID (assoc curr :failed true))]
;将记录put到pending这个RotatingMap中,更新ack-val或其它相关值
;{root-id {:spout-task task-id :val ack-val :failed bool-val …}}
(.put pending id curr)
;curr和其task-id必须都存在
(when (and curr (:spout-task curr))
;;Acker根据处理结果发消息通知spout tuple对应的task(指定task-id)
;若curr的ack-val最终为0,说明这个spout tuple被完全处理了,即对应的tuple树中的每个tuple都处理成功了,
;那么就给创建这个spout tuple的task发送消息,告诉它已成功处理了这个spout tuple
(cond (= 0 (:val curr))
(do
;从pending中移除root-id对应的记录
(.remove pending id)
(acker-emit-direct output-collector
(:spout-task curr)
;给spout tuple对应的task发送"__ack_ack"类型的消息
ACKER-ACK-STREAM-ID
[id]
))
;若curr中:failed对应的value为true,说明这个spout tuple处理失败了,
;那么就给创建这个spout tuple的task发送一个失败消息
(:failed curr)
(do
(.remove pending id)
(acker-emit-direct output-collector
(:spout-task curr)
;给spout tuple对应的task发送"__ack_fail"类型的消息
ACKER-FAIL-STREAM-ID
[id]
))
))
(.ack output-collector tuple)
))))
(^void cleanup [this]
)
)))
update-ack定义:
;做XOR运算,并更新tmp-ack-val。返回的是一个Map
;Param curr-entry为Map,val为传进来的tmp-ack-val
(defn- update-ack [curr-entry val]
;old为curr-entry中原来的tmp-ack-val,初始值为0
(let [old (get curr-entry :val 0)]
;对old和val做XOR运算,并更新curr-entry的tmp-ack-val
(assoc curr-entry :val (bit-xor old val))
))
acker-emit-direct定义:
;给Spout中对应的task发送消息 ;Param task Spout中task的task-id,根据这个task-id通知对应的task其处理的spout-tuple是成功还是失败 (defn- acker-emit-direct [^OutputCollector collector ^Integer task ^String stream ^List values] ;调用OutputCollector的emitDirect方法发送消息,(task stream values)为参数 (.emitDirect collector task stream values) )

图2-3
在图2-3中,Bolt2中不再生成新的tuple,处理完后它给Acker发送消息[66,4]。Acker接收到这个消息后更新自己的ack-val,3 XOR 4 = 7,更新后Acker维护的数据结构变为{66 {11 7}}。
图2-4
在图2-4中,同样,Bolt3中不再生成新的tuple,处理完后它给Acker发送消息[66,7]。Acker接收到这个消息后更新自己的ack-val,7 XOR 7 = 0,更新后Acker维护的数据结构变为{66 {11 0}},这个时候Acker发现ack-val变成0了,它就给Spout中对应的task发送一条成功消息,表明对应的spout tuple被完全处理了。
因为tuple-id是随机的64位数字,所以ack-val碰巧变成0(而不是因为所有创建的tuple都处理完成)的概率可以忽略不计。举个例子, 就算每秒发生10000个ack, 那么也需要50 000 000年才可能发生一个错误。并且就算发生了一个错误,也只有在这个tuple处理失败的时候才会造成数据丢失。