java IO流
java 输入输出流是一个比较特别的部分,因为我们无时无刻不在用到输入输出,但是我们却看不到明显的运行效果。接下来就了解一下输入和输出的概念。输入:使用输入机制来接收外部输入过来的数据,比如键盘上的打印的数据,磁盘,文件上输入过来的数据;
输出:顾名思义,就是我们把我们运行程序中的数据给输出到页面,或者输出到移动设备上。如果要把一个移动设备上的东西,输出到用户界面,就得先使用输入后使用输出。
Java的I/O建立在流上,不同的流类会读写某个特定的数据源,在Java.io包下有很多流类,但是不管哪种类,只要是输出流那么它必定会有输出流的基本方法来写入数据,所有输入流也使用相同的方法来读取数据;在我们读写的时候通常可以去忽略具体的实现细节;
而输入和输出流又分为了,字节流和字符流两种。字节流就是以字节为基本单位来处理数据,进行输入输出操作,而字符流则是以字符为基本单位来进行处理数据。另外Java io流里面还使用了一个经典的装饰器设计模式,他讲IO划分成了底层输入流,和上层处理流,即每个物理设备获取流的方式可能可能存在一定的差异,他通过底层输入流获取数据,再通过上层处理流转换成统一的处理对象,从而允许程序的统一输入,输出;
流是同步的,也就是说,当线程请求一个流读写数据的时候再做其他操作之前,他要等待所读写的数据,java也支持使用通道和非阻塞Io的,非阻塞Io有点复杂,但是允许效率要快的很大。
File类:
路径名字符串与抽象路径名之间的转换与系统有关。将抽象路径名转换为路径名字符串时,每个名称与下一个名称之间用一个默认分隔符 隔开。无论是抽象路径名,还是路径名字符串都可以使用相对路径,或者绝对路径。的,我们可以通过JDK文档提供的方法来操作文件和目录;
通过File类实现输出指定目录下包含的所有文件名,包含子目录;
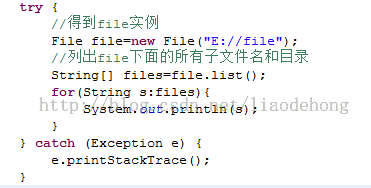
这样写看似没有问题,其实仍然不够严谨,因为,如果其子内文件夹里面还有文件的话,那么就会遍历不出来。这个时候就要使用
这个方法,通过递归去遍历所有的文件名和目录;
在我们读取文件目录的时候还可以设置文件过滤器,让一些文件能够被读出来,而一些文件直接被过滤掉,通过FilenameFilter来实现,里面有一个accept方法
第一个参数是用来比较File的名字的,只要符合规则就可以过滤,第二个参数用来对比,文件的名字的,比如我上面这一段就是只要后缀名不符合.java的就都给过滤掉
Java的流按照放向来划分是输入流和输出流两种,有时间也好把输入流和输出流搞混淆了,例如我们从从服务器端传送数据到客户端的页面,其实是从服务器端输出了内存数据到客户端,而客户端则从网络里读取数据再输入给后台;
按照方式来分的话我们可以分为字符流和字节流,一个是操作字符的,一个是操作字节的.字符流的基类是Reader(阅读器)和Writer(书写器),而字节流的基类是InputStream和OutStread;
如果按照流的角色来分的话又可以分为节点流和处理流。可以直接向一个Io设备,例如U盘,网络,进行读写操作的流,我们称之为节点流,节点流也称为低级流,
因为有可能每个设备使用的节点流方式不一样,这就需要我们去变动。而处理流则是对一个已经存在了的流进行封装,通过封装后的流来实现读写功能,处理流也称为高级流,使用高级流的好处就是,它不会直接去连接一个数据源进行读写操作,而是去把流类封装成相同的处理流,这样我们不用再随着访问的数据源不同而去更换我们的方法;
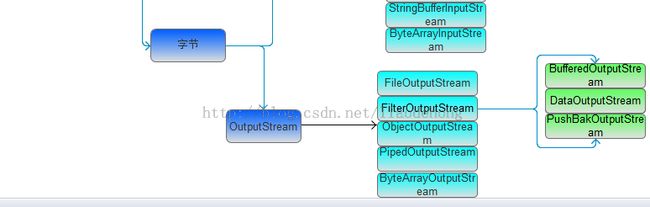
上图绘制了一些常用的Java Io类;接着来看一看输入流怎么使用的;
InputStream和Reader是所有输入流的抽象基类,本身不能够去实例化输入,但是他们可以成为一个模板,所有的输入流都可以使用他们的方法,
InputStream里面包含三个输入方法,
read()
从输入流中读取数据的下一个字节。
read(byte[] b)
从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
read(byte[] b, int off, int len)
将输入流中最多 len 个数据字节读入 byte 数组。
而Reader里面的三个输入方法其实和InputStream差不多,只不过输入的参数不一样。因为Java里面没有字节这个类型,所以InPustStream里面就用Byte来表示,
而Reader里面传入的则是char[]型数组;这两个数组其实就相当于一个容器,假如我们要把一个缸里的水给装到另外一个缸里,我们是一滴一滴的给他传输过去快,还是用一个桶给盛满了快啦,答案肯定是先用桶装,再倒入另外一个缸里要快了。而我们可以把数组理解为桶,数组的大小就相当于桶的容量了。那么当我们桶里的水完了之后就要用read(byte[] b)=-1去判断了。如果缸里的水也放完了,那就要去手动的关闭我们的流,用close;我们要使用流入方法,就要使用他们的子类,FileInputStream和FileRead。其实不管你使用哪中输入流都会使用到这三种输入方法,有时候你甚至不知道正在读取的流是哪种类型的,比如
TelnetInputStream从网络连接中读取数据,但是这个类被隐藏在sun.net包中,而且也没有响应的JPA文档。不过只要记住这些方法都是用来写入的,然后根据类型去选取适合我们的方法,这样就行了;
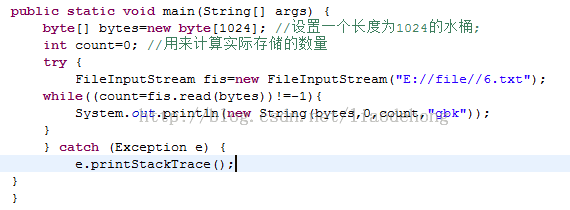
上图是FileInputStream的用法,FileRead用法与他大致一致,这里要注意的是,我们创建了一个1024的Byte字节数组,其实有可能我们用不到怎么多,但是如果我们创建一个小的字节,有可能就好出现乱码,因为一个中文是2个字节,如果字节不够会导致我一个中文只读取了一半;还有我们的字节数组最好是整数;
这里还有一个要注意的是,我们在读入到数组里面的时候,不一定会成功,因为可能会有一些硬件上的BUG,也有可能我们读取到一半的时候出现了问题,这些都属于不可预知的BUG,考虑到这一点,读取字节应当返回实际的读取输,比如我上面的写的代码,用一个count来接收实际读取的数量,当然也还有其他的写法;
输出流:
输出流主要是有OuputStream和Write两个基类,这两个类也非常的相似,只不过一个输出的是字节,一个输出的是字符而已;
write(int c)
写入单个字符。
write(char[] cbuf)
写入字符数组。
write(char[] cbuf, int off, int len)
写入字符数组的某一部分。
另外Write因为读取的是字符,所以可以用String 来替代字符数组
write(String str)
写入字符串。

上图中也是先进入读取文档中的数据,然后把他输出到另外一个文档中去;另外要注意在执行完毕之后一定要刷新一下输出流,flush()方法,然后再关闭一下,尽管很多流在关闭之前都会自动刷新的,但是还是建议在关闭前先刷新一下;
接下来再来看看Java的处理流,使用处理流的好处可以方便简化我们的操作,而且效率会更高;
Java的输入输出流很多个体系,而且也比较复杂,我们要根据自己的需求来选择相应的流,通常我们说字节流要比字符流强大,因为计算机里的东西都是二进制的,字节流可以帮我们处理所有的二进制文件,比如Map3啊,图片啊等等,但是如果我们去处理字符用字节流的话,需要去转换一下格式,这样又比较麻烦,所以我们如果读取的文件是文本文档的话,一定要优先考虑去用字符流,而其他类型的就要用字节流;
用的最多的PrintStream流,他是一个过滤器输出流,我估计我们程序员接触到的第一个输出流可能就是这个了,因为System.out.print就是一个PintStream;出了平常的Write(),还有10个重载的print和println方法,printIn与print的区别之处就在与一个换行,一个不换行,他里面可以打印出java的所有输出类型;

但是PrintStream是有害的,网络程序员应该像躲瘟疫一样的去躲避他;
第一个问题是,他是与平台有关的,取决于平台的机器,比如println里面的输出要换行,但是每个平台的换行符都会有些不一样,比如Unix下是(\n),在Macos 9下是
回车符(\r),在Windows下是回车\(\r\n);
第二个问题是,假设PrintStream使用的是所在平台的默认编码方式,不过这种方式可能不是服务器或者客户端所需要的,PrintStream不提供改变默认编码的格式;
第三个问题是PrintStream吞掉了所有的检查时异常,这使得PrintStream会适合初学者去打印一句"Hello World",因为他不需要去了解哪些异常。我们使用其他流的时候都需要显示的去做异常处理,而使用这个流却不需要;
另外PrintStream还有一个子类就是PrintWrite,他能正确的处理多字节字符集,和国际化文本,Sun最初技术使用这个类,来替代PrintStream的,但是这样会使原来很多代码失效,所以就放弃了这种打算。他的方法和PrintStream基本相同,除了4个Write写入的是字符以外;
转换流InputStreamReader,OutputStreamWrite:
顾名思义啊,InputStreamReader就是把一个输入的字节流转换为一个字符流,而OutputStreamWrite就是把一个输出字节流转换为字符流;
缓冲流
就是带有缓冲区的流,比如BufferedReader和BufferedWriter是基于字符的,还有BufferedInputStream和BufferedOutputStream是基于字节的。他们都会使用一个内部数组作为缓冲去。当程序从BuufferedReader读取时,文本会先从缓冲去得到,而不是直接从底层输入流或其他文本得到,当缓冲区清空时,用尽可能多的文本再次填充,尽管这些文本不是全部需要,这样做可以使得以后的读取速度更快;同样写入也是同理;他们的构造方法都可以串连到一个底层的读取流,并设置缓冲区的大小,入过没有设置的话,默认的就是8192个字节;
推回输入流
在所有的流中,有两个特殊的流与众不同,他们就是PushbackInputStream;PushbackReader
他们都提供了3个把字节\字符,数组推回到缓冲区的方法,从而允许重复读取刚才的内容;
unread(int b)
推回一个字节:将其复制到推回缓冲区之前。
unread(byte[] b, int off, int len)
推回 byte 数组的某一部分:将其复制到推回缓冲区之前。
unread(byte[] b)
推回一个 byte 数组:将其复制到推回缓冲区之前。
可能在重复读取或者一些特殊的情况才会用到这种方法吧;
重定向标准输入输出
Java程序的标准输入输出流分别出system.in和system.out,在默认情况下,他们分别代表键盘和显示器,当程序通过System.in来输入的时候,实际上是在从键盘上接收输入数据,在执行System.out的时候,就是把我们的数据输出到显示器上;
在System的这个类下他们都提供了三个重定向输入输出方法;
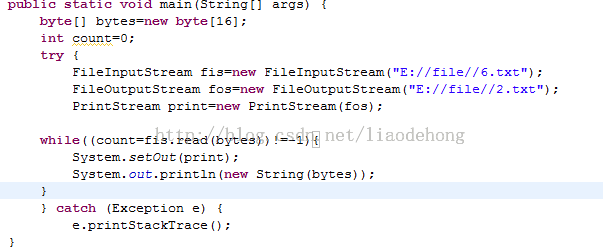
执行上面的代码将不会再打印内容,因为这里使用了重定向输出,把输出的内容给重定向到2.txt里面去了,打开我们的路径,可以看到那个文本内容;
RandomAccessFile:
它是Java流中最丰富的文件内容访问类,它提供了众多的方法来访问内容,它既可以读取内容,也可以向文件输出数据,与其他类不同,他可以访问任意的文件内容,也可以在任意位置写入数据,因为他会有一个指针,当我们刚创建一个文件的时候,指针就会指向0,每次写入一个数据的时候,指针就会向后移动;如果我们不需要完全读取某个文件的内容的时候可以使用这个流,另外好像很多网站上的继续下载功能也是使用的这个流类;当我们下载内容到了一半的时候,突然断电了,下次再上网的时候还可以继续下载,应该就是使用 的这个流;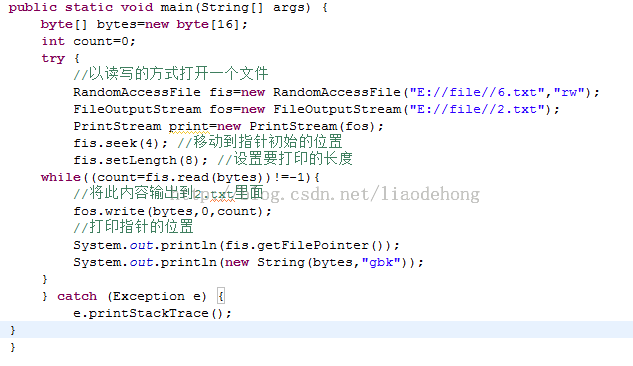
对象序列化
对象序列化的目的是将对象保存到磁盘中,或者允许再网络中,直接传输对象。对象序列化机制允许把java对象转换成与平台无关的,二进制流,从而允许将二进制流永久的保存到磁盘上或者数据库中,通过网络将这种二进制流传输到另一个网络节点,其他程序一旦获得了这种二进制流,都可以将这种二进制流转换为原来的对象;
序列化机制可以使得对象可以脱离程序而独立存在。
对象的序列化就是指,将一个java对象写入IO流,而反序列化就是将一个对象从Io流中恢复成Java代码;如果要让某个对象支持序列化,那么最好去实现两个序列化接口Serializable,或者Externalizable;实现Serializable接口不需要实现任何方法,只需要实现以下JVM就知道这个类可以被序列化。通常我们都建议Java中的每个javabean都应该实现这个接口;
下面创建一个很简单的类

然后序列化这个类
这里要注意几点,第一个是这里反序列化,只是把对象里面的数据给序列化了,如果我们要反序列化这个java类,那么必须提供相应的class;
第二点是如果这个类里面包含的有其他类,那么他的包含类,也要被声明为可序列化的;
第三点是如果一个类没有实现序列化接口,但是也能够被序列化的,只不过实现了序列化接口,序列化的效率可能会更高一点
第四点是如果你不想有些字段被序列化可以使用transient来修饰,要注意最好不好提供无参构造方法;
另外还有一种序列化接口可以实现自定义的序列化;我们平常的Java版本总是会不断的去升级的,那么随着项目的升级,系统的class文件也好升级,为了保持
版本的兼容性,我们可以使用一个serialVersionUID来标示我们的版本号;