显著性论文学习阶段总结(二)
1) 系统框架:

2) 算法思路:
① 图像表示:本文通过1500张图像中,在各通道提取出的8*8的patch,学到了一个自然图像的字典。使用这个字典以及一系列的系数α就可以重组任何一个patch。各通道分别进行。因此,在学习了字典,并且使用Matlab中的LARS算法进行了稀疏编码系数α的估计之后,每个patch通过系数表示成一个矢量。
② 显著度计算:在这些矢量上进行局部和全局显著度的计算。局部显著度为两个图像块系数向量在特征空间里的欧几里得距离,用空间距离进行加权,距离远权重小;全局显著度为图像块矢量进行直方图计算后的概率分布函数的倒数。最终RGBLAB每个通道会得到局部和全局两个显著图。
③ 显著度融合:分三步:a. 每一个通道内,局部和全局显著图进行归一化并相乘;b. 每一种颜色空间内,三个显著图归一化并相加;c. 两个颜色空间的显著图归一化并相加。相乘表示目标必须同时满足局部和全局的孤立性条件。相加表示各个通道之间是互补,或者竞争关系。并且这个竞争是现在各个颜色空间内部几个通道之间进行,优胜者再和另一个颜色通道的比较。
④ 结果优化:尺度空间扩展,对图像进行降采样,计算每个尺度下的显著性图,归一化后计算这些显著性图的均值,再用高斯核进行卷积得到平滑结果;
3) 论文评价:文章采用多通道显著性融合的方法,并进行了多尺度增强;并应用了字典学习和稀疏编码,计算量较大(感觉Ali Borji的论文计算量都很大,计算很多特征或很多显著性图)。代码还在调试,论文图示中结果还可以,边缘显著性较突出。
2.Ali Borji, DickyN.Sihite, Laurent Itti, Salient Object Detection:A Benchmark, ECCV2012
1) 主要贡献:一篇关于显著性模型的综合论文,总结了自2011年以及之前发表的,能容易得到的(代码或者Saliency Map),具有很好的准确率的,或者具有很高引用率的模型。
全文共用5个数据库:MSRA,ASD,SED1,SED2,SOD(这个五个数据 库都是包含物体的数据库,该文的重点也是考察包含物体的数据库上比较各 个模型)。
具体参见博客:http://www.cnblogs.com/hSheng/archive/2012/12/06/2804385.html
3.Xiaoshuai Sun, Hongxun Yao, Rongrong Ji, What Are We Looking For: Towards Statistical Modeling of Saccadic Eye Movements and Visual Saliency, CVPR2012
1) 基本思想:该文的基本假设从视觉注视点的统计分析得出。得出的基本假设为两点:a:显著性是非常稀疏的,也就是说大多数地方的显著值都是0,而只有图中的很小区域的显著值有很大的值;b:具有很大的显著值的区域的周围区域通常具有丰富结构信息。而超高斯(super-Gaussianity)分布刚好具有这两点特征。
根据特征融合理论,显著度是由多个特征通道融合而成的,用于显著度检测 的特征应该与显著度具有相似的统计特征;对于一个视觉统计点,显著度具 有超高斯性,我们的注视过程就是在寻找场景中的超高斯成分。
2) 算法流程:

① 超高斯成分分析:给定图像I,滑动窗扫描将其变换成基于块的表示X,存储为矩阵形式,每个列向量表示一个变形后的图像块;用PCA去相关,白化后得到特征矩阵Z;在统计学领域,通常利用kurtosis函数来模拟超高斯分布。本文通过定义一个随机映射矩阵w,将原始特征空间Z通过这个映射矩阵w,然后求其最大值的kurtosis。通过projection pursuit优化算法求这个w,而这个w也将决定哪些值是saliency。在得到一系列的映射向量w时,我们需要将他们进行格拉姆-施密特正交化,来确保当前的优化方向与前面的优化方向不一致。同样通过不停的迭代,能够得到不同的saliency点。本文能同时计算出saliency map和视线扫描的轨迹。
② WAT目光定位:在得到了投影向量W后,计算这个投影方向上的响应图RMi:这个响应图就是原图中的那个具有最大的单个超高斯分布的区域,这个分布是基于图像颜色的分布。这样RM1对应图中具有最大SGC(Super Gaussian Component)对应的响应图,表示人眼首次注视的区域,RM2则是对应的次大SGC分布,RM3,...依次推理,直到W收敛。而W收敛意味着下次转移的位置与上次转移的位置距离很小。也就是以后的SGC响应太小,不能引起注意力了。
根据winner-takes-all原则选取响应值最大的位置作为注视点。
③ 显著图计算:响应图的非线性组合,pi为第i个响应图的直方图概率。
3) 论文评价:本文的视角比较新颖,从“在图像中的什么成分能引起注意力”的问题出发。从大量tracker数据中得到假设:超高斯分布的数据更能吸引人们的注意力。因此文章致力于寻找那些具有超高斯分布的位置。实验结果看起来还可以,噪音抑制能力较强,saliency map有点模糊。
4.Stas Goferman,Lihi Zelnik-Manor, Ayellet Ta, Context-Aware Saliency Detection, CVPR2010
1) 基本思路:本文先提出了基于上下文感知的显著度准则,然后依照这4个准则来实现著度检测。
2) 准则提出与实现如下:
① Local low-level considerations:具有不同颜色和模式的区域对应显著性值高,均匀或模糊区域显著性值低;
② Global considerations:经常出现的特征应当被抑制;
③ Visual organization rules:显著的像素应当聚集在一起,而不是遍布整幅图像;
根据前3条准则,先进行单尺度的局部-全局显著性计算,再进行多尺度增强。
一对图像块pi与pj的颜色距离越大,位置距离越小,则它们的差异值越大。其中颜色距离为两图像块在Lab空间的欧几里得颜色距离,空间距离为欧几里得位置距离;若对于任意pj,得到的差异值都很大,则认为pi是显著的。
为简化计算,显著性值的计算中选取前k个最相似的图像块进行度量。
计算多个尺度下的显著性值,取平均值来进一步提高显著和非显著区域的对比度。
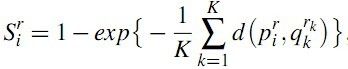
加入上下文修正:设定显著性阈值从saliency map中提取most attended localized areas,在attended areas 之外的像素显著性值由与它最近的attended pixel之间的欧几里得距离加权,得到新的显著性值。从而提高显著目标附近的显著性值,降低背景区域的显著性值。

④ High-level factors:作为后期处理,加入高层先验知识如人脸检测;
3) 论文评价:提出显著性准则作为算法的先验知识进行显著度检测,显著性思路思路与中央-周围机制大体相同,融合多尺度修正与上下文感知,导致saliency map中从目标往四周显著性值渐渐降低,边缘较模糊。代码速度与实验结果还可以,如果将颜色距离与空间距离的组合采用加权方式,会不会对显著性结果有所改变?
5.Tie Liu,Jian Sun,Nan-Ning Zheng,Learning to Detect A Salient Object,CVPR2007
1) 基本思想:先对显著目标进行特征提取,得到多尺度对比度,中央-周围对比度,颜色空间分布3种feature maps,再用条件随机场模型进行组合,得到最终的显著性检测结果。
2) 方法流程:
① Multi-scale contrast feature:高斯金字塔多层对比度的线性组合。
② Center-surround histogram:计算像素点x'为中心的显著矩形区域与其周 围矩形区域的RGB颜色直方图之间的x2距离;由于目标尺寸不同,选择不同纵横比的矩形区域进行测试,x2距离最大对应得到最独特矩形区域;像素点x的中央-周围直方图特征定义为其所属所有矩形区域的空间高斯加权x2距离之和。
③ Color spatial-distribution:图像中的所有颜色用高斯混合模型来表示,每一个像素被分配给具有某概率的颜色成分,计算每一个颜色成分的水平方差和垂直方差,得到该成分的空间方差;颜色空间分布特征定义为中央加权的 空间方差之和。颜色方差越小,该颜色越有可能属于显著目标。
④ 条件随机场结合:能量函数为K个显著特征和配对特征的线性组合,通 过条件随机场学习计算权重,得到最优化的线性组合。其中显著特征为前面 得到的3种feature map,用来描述一个像素点是否属于显著目标;配对特征 为两个相邻像素点的空间关系,是对相邻像素标记为不同值的惩罚项。
3) 论文评价:采用条件随机场模型进行特征组合,融合颜色独立性,颜色空间分布和多尺度分布,考虑了局部信息,全局信息以及尺度信息。效果也不错。
6.Jian Li, Martin D.Levine, Saliency Detection Based on Frequency and Spatial Domain Analysis,BMVC2011
1) 总体思路:本文结合频域的全局信息和时域的局部信息进行显著度检测。在频域分析中,根据全局信息对非显著区域进行建模,频繁出现的成分认为不显著,用频谱平滑进行抑制;在时域分析中,采用中央-周围机制加强信息量大的区域;最后将两个通道的输出结果相结合得到显著图。
2) 算法步骤:
① 频域分析:一幅图像中只有少部分是显著的,大部分是背景,即repeated patterns;基于该假设,我们可以寻找非显著的部分进行抑制,从而突出显著部分;对原始图像进行幅度谱分析,发现峰值对应图像中的repeated patterns,故采用高斯核进行平滑来抑制repeated patterns。为处理不同尺度下的幅度谱,提出频谱尺度空间(Spectrum Scale-Space),高斯核的尺度因子范围由图像的长和宽来决定。再根据显著图的熵来确定高斯核的最优尺度,计算每个尺度下的显著图的熵,选择熵最小的显著图作为最佳结果。(根据熵定义,等概分布时熵最大,说明画面均匀;则显著物体最突出最集中时对应熵最小)
② 时域分析:应用ICA(Independent Component Analysis)选用场景中的独立成分作为中央-周围滤波器,根据论文Dynamic visual attention: searching for coding length increments得到192个响应图,进行加权求和得到一幅显著图,权值为原始图像滤波后的熵取倒数。即熵越小,对应该响应图显著部分越集中,对最终显著图的贡献越大。
③ 显著图结合:将图像分解到图像空间I,RG,BY,分别计算三个图像通道的最佳尺度频域显著图,再进行熵值加权求和,得到频域saliency map Sg;时域saliency map的计算如②所述,得到Sl;最终的saliency map为二者加权组合:

3) 论文评价:文章结合时域和频域两种信息来进行显著度检测,频域分析应用全局信息突出显著度,时域分析增强那些具有很高局部对比度的显著区域,并在多尺度优化时加入熵的应用,值得借鉴。从论文的实验结果来看,对于目标较小的情况结果也不错,不过没有下载到代码,不知道速度和实际运算结果是否满意。