Spring Batch(3): 基本概念(批处理DSL)
第三章 Spring Batch基本概念
批处理原型:

批处理领域语言:
(参考官方文档中的批处理领域语言)
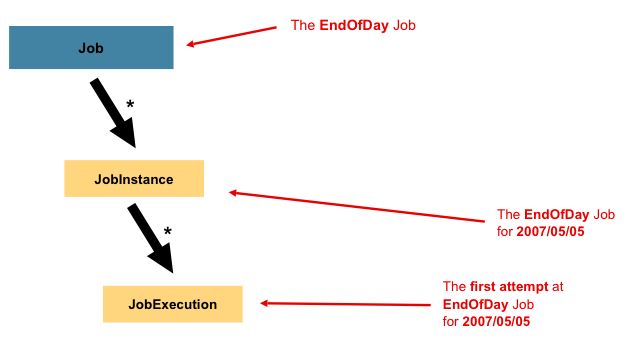
3.1 Job
作业是批处理的逻辑封装。在Spring Batch中,作业是Step容器。
一个简单的Job配置如下:
<job id="footballJob">
<step id="playerload" next="gameLoad"/>
<step id="gameLoad" next="playerSummarization"/>
<step id="playerSummarization"/>
</job>- JobInstance
作业实例是Job的一个实例化,例如对于一个每天处理一次的Job,它的一个实例可能是针对2016-03-26这一天的一个作业实例。 - JobParameter
同一个Job的不同实例,通过JobParameter作业参数来区分,例如上面提到的2016-03-26。

JobInstance=Job + identifying JobParammeter
3. JobExecution
作业执行是某个作业的一次执行尝试(execution attempt),可能成功可能失败,只有作业执行成功之后JobInstance才算完成。
JobExecution包括以下典型的属性:
| 属性名称 | 例子 | 描述 |
|---|---|---|
| status | started/failed/completed | 状态,描述此次执行的当前状态 |
| startTime | 2016-03-26 02:00:00 | java.util.Date对象 |
| endTime | 2016-03-26 02:30:00 | java.util.Date对象 |
| exitStatus | completed | 表示任务的执行结果 |
| createTime | 2016-03-26 0:30:00 | 作业创建时间,已经创建的作业可能还没开始执行 |
| lastUpdated | - | 最后更新时间 |
| executionContext | - | 执行上下文 |
| failureException | - | 失败异常信息 |
已经完成的JobInstance,不能被重新执行
在同一时刻,一个JobInstance只能有一个JobExecution
3.2 Step
Step是组成Job的基础单元,是整个Job的其中一个步骤的封装。
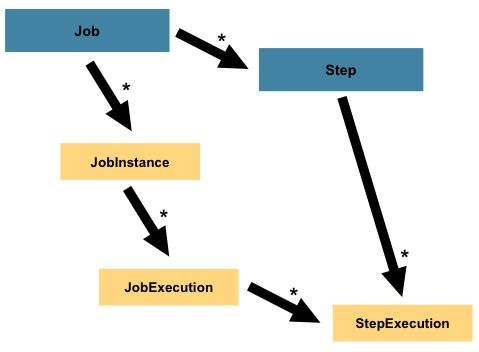
一次Step的执行尝试成为StepExecution,它有下面一些属性:
| 属性名称 | 例子 | 描述 |
|---|---|---|
| status | started/failed/completed | 状态,描述此次执行的当前状态 |
| startTime | 2016-03-26 02:00:00 | java.util.Date对象 |
| endTime | 2016-03-26 02:30:00 | java.util.Date对象 |
| exitStatus | completed | 表示任务的执行结果 |
| executionContext | - | 执行上下文 |
| readCount | - | 成功读取的item数 |
| writeCount | - | 成功写入的item数 |
| commitCount | - | 提交的事务数 |
| rollbackCount | - | 回滚事务数 |
| readSkipCount | - | 因读取失败而跳过的item数 |
| writeSkipCount | - | 因写入失败而跳过的item数 |
| processSkipCount | - | 因处理失败而跳过的item数 |
| filteredCount | - | 被过滤的item数 |
3.3 ExecutionContext
ExecutionContext是Job或Step的执行上下文,保存执行过程中需要的所有信息,类似于Quartz中的JobDataMap。例如下面代码段保存当前已经读取的行数:
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());这些上下文信息会被持久化到JobRepository,用于后续处理,例如失败的Step可以从上次失败的地方继续执行,续点执行。
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) {
log.debug("Initializing for restart. Restart data is: " + executionContext);
long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT));
LineReader reader = getReader();
Object record = "";
while (reader.getPosition() < lineCount && record != null) {
record = readLine();
}
}ExecutionContext也可以包含一些统计信息,例如用于根据处理进度。
在某一个时刻,一个StepExecution只有一个ExecutionContext,一个JobExecution至少包含一个ExecutionContext。
3.4 JobRepository
JobRepository是批处理的持久化机制,用于存储作业的元数据及其他信息,为JobLauncher、Job、Step提供CRUD操作。
<job-repository id="jobRepository"/>Spring Batch提供了2中实现:
1)内存实现:MapJobRepositoryFactoryBean
2)数据库实现:可以指定数据源,事务级别等。
3.5 JobLauncher
该组件用于启动Job的执行,接口定义如下:
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException;
}该接口的实现从Repository中获取一个JobExecution,然后启动该Job。
外部系统通过Launcher与批处理应用交互。
3.6 ItemReader
ItemReader用于在Step中读取item,一次一个Item。如果没有更多的item,将返回null。
接口定义如下:
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException;
}默认提供了多种实现,包括文本、XML、数据库、JMS等。如IbatisPagingItemReader提供了通过MyBatis分页读取数的功能。ListItemReader从List中读取Item。
另外,可以很方便的扩展实现自己的ItemReader。
3.7 Item Writer
ItemWriter用于在Step中输入结果,可以批次(batch,chunk)写入。
接口定义如下:
public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}Spring Batch自带了诸多的实现,例如MongoItemWriter,CompositeItemWriter、ClassifierCompositeItemWriter、IbatisBatchItemWriter.
3.8 ItemProcessor
该组件处理ItemReader读入的Item,执行逻辑处理并提价给ItemWriter写入,如果认为item非法不该被写入,则返回null。接口定义如下:
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}默认提供了下面一些组件:
- CompisiteItemProcessor: 组合处理器,可以封装多个业务出路
- ItemProcessorAdapter:适配器,复用现有业务自检
- PassThroughProcessor: 什么也不做,直接返回数据
- ValidatingItemProcessor: 验证组件
3.9 job命名空间
以上这些组件都可以通过常规的Spring Bean配置,但是Spring Batch提供了一个特有的命名空间用于简化配置。
<beans:beans xmlns="http://www.springframework.org/schema/batch" xmlns:beans="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch-2.2.xsd">
<job id="ioSampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
</tasklet>
</step>
</job>
</beans:beans>