eclipselink + jpa + mysql 的用法
一个简单的eclipselink + jpa + mysql 的用法示例
基本环境准备
我们先来看看一个具体的JPA工程示例。要运行这个示例,我们需要如下的类库和软件安装配置好:
类库: EclipseLink, mysql-connector-j
数据库: Mysql
开发环境:eclipse
因为JPA是一个公开的规范,所以有不同的实现。我们需要一个JPA的类库。这里我们引用了如下类库:EclipseLink (可以让eclipse 帮我们下载去)。
在下载EclipseLink包后,解压。我们需要将里面jlib目录下的eclipselink.jar以及jlib/jpa目录里的java.persistence.x.jar引入到工程中就可以。
后面我们定义代码里的映射关系对应的底层实现就是由这两个包实现。 既然要实现ORM,肯定少不了数据库。这里我们用了比较传统的mysql数据库。所以少不了也需要引用mysql的jdbc驱动:mysql-connector-javax.jar。
准备好了这些之后,我们创建一个JPAProject的java工程。整体的项目结构如下图:

这里为了方便工程引用类库,首先将这些库文件拷贝到工程下面的一个lib目录里,再将这些库引入到工程中。
persistence.xml
在前面配置好基本的类库之后我们还有一个需要关心的就是,既然我们是ORM,就有一个要映射到数据库的地方。这里是怎么映射到数据库的呢?具体又映射到哪个数据库呢?这些都是在persistence.xml文件定义的。我们在创建好工程之后的src目录里建立一个META-INF的目录,然后在这个目录里建立一个persistence.xml文件。程序连接数据库和对象映射的配置信息就是通过读取这个目录下的文件来实现的。我们来看一个persistence.xml的示例:
- <?xml version="1.0" encoding="UTF-8" ?>
- <persistence xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
- http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
- version="2.0" xmlns="http://java.sun.com/xml/ns/persistence">
- <persistence-unit name="EmployeeService" transaction-type="RESOURCE_LOCAL">
- <class>model.PersonInformation</class>
- <properties>
- <property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
- <property name="javax.persistence.jdbc.url"
- value="jdbc:mysql://localhost:3306/simpleDb" />
- <property name="javax.persistence.jdbc.user" value="root" />
- <property name="javax.persistence.jdbc.password" value="root" />
- <!-- EclipseLink should create the database schema automatically -->
- <property name="eclipselink.ddl-generation" value="create-tables" />
- <property name="eclipselink.ddl-generation.output-mode"
- value="database" />
- </properties>
- </persistence-unit>
- </persistence>
这里都是xml的配置项,看起来也很容易懂。在一个<persistence-unit>的单元里定义了这个unit的名字以及详细的数据库连接驱动,数据库用户名,密码。前面<class>里面定义的是需要映射到数据库的具体实体类。比如model.Employee就对应于我们在package model里定义的Employee类。因为我们要连的数据库是mysql,这里的javax.persistence.jdbc.driver值被设为com.mysql.jdbc.Driver。而我们具体要连接的数据库名字在javax.persistence.jdbc.url对应的值里面定义了,为simpleDb。为了后面实际程序运行的时候能够读写这个库,我们需要事先在数据库里创建simpleDb。
OK,有了这些基本的设置。我们就能连上数据库进行实际的操作了。
实体对象定义
现在,我们需要定义一个可以具体实例化到数据库里的对象。我们定义一个PersonInformation的类如下:
- package model;
- import javax.persistence.Entity;
- import javax.persistence.Id;
- @Entity
- public class PersonInformation {
- @Id
- private int id;
- private String name;
- private int age;
- public int getId() {
- return id;
- }
- public void setId(int id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public int getAge() {
- return age;
- }
- public void setAge(int age) {
- this.age = age;
- }
- }
这里只是很简单的一个entity bean对象定义。我们针对每个可以操作的对象定义了get, set方法。这里比较有意思的地方是我们用了两个annotation,一个是@Entity,一个是@Id。这里的@Entity表示一个可以序列化映射的的对象。如果我们希望这个对象被映射到数据库中的某个表,则必须要加上这个annotation。而@Id则表示对应表的主键。我们建一个表要求有对应的主键。这里指定id为主键。如果我们不指定主键的话则运行的时候会出错。有兴趣的可以尝试一下。
有了这些定义之后,我们就可以来使用他们了。这里是通过他们访问数据库的代码:
- package main;
- import javax.persistence.EntityManager;
- import javax.persistence.EntityManagerFactory;
- import javax.persistence.Persistence;
- import model.PersonInformation;
- public class Main {
- private static final String PERSISTENCE_UNIT_NAME = "EmployeeService";
- private static EntityManagerFactory factory;
- public static void main(String[] args) {
- factory = Persistence.createEntityManagerFactory(
- PERSISTENCE_UNIT_NAME);
- EntityManager em = factory.createEntityManager();
- em.getTransaction().begin();
- PersonInformation person = new PersonInformation();
- person.setId(1);
- person.setAge(30);
- person.setName("fred");
- em.persist(person);
- em.getTransaction().commit();
- em.close();
- }
- }
第一个需要创建的对象是EntityManagerFactory, 这里通过Persistence.createEntityManagerFactory方法。而这个"EmployeeService"是哪里来的呢?我们看前面的persistence.xml文件,那里有<persistence-unit name="EmployeeService" transaction-type="RESOURCE_LOCAL">这个定义。EmployeeService就是对应到这里一个persistence-unit的名字。他们必须一致。实际上,如果我们需要访问多个库的话,在配置文件里也可以定义多个persistence-unit。有了这个factory之后我们再创建一个EntityManager对象。
为了使得对象的创建成为一个事务来提交,我们通过em.getTransaction().begin(); em.getTransaction().commit();这两个方法来完成整个数据插入的过程。
现在运行程序,我们再去查看数据库的话,则会发现如下的信息:
回顾一下我们前面定义的PersonInformation对象的信息,我们定义的字段都是小写格式的。映射到数据库里包括表名和表里面字段名都是大写格式的。前面我们指定了id字段为主键之后,对应的表里这个字段就有了primary key not null的限制。
修改
从前面的运行结果,我们可以看到一些实体对象和数据库表之间的映射关系。可是在实际情况中,有时候我们希望数据库表名或者里面的字段名能够更加可以定制化一点。不是简单的将对象里的字段变成大写的。这样可以增加一点可读性,那我们该怎么修改呢?
很显然,我们需要指定对象应该对应哪个表名以及每个属性应该对应什么名字。这是修改后的代码:
- package model;
- import javax.persistence.Column;
- import javax.persistence.Entity;
- import javax.persistence.GeneratedValue;
- import javax.persistence.GenerationType;
- import javax.persistence.Id;
- import javax.persistence.Table;
- @Entity
- @Table(name="PersonInformation")
- public class PersonInformation {
- @Id
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- @Column(name="id")
- private int id;
- @Column(name="name")
- private String name;
- @Column(name="age")
- private int age;
- public int getId() {
- return id;
- }
- public void setId(int id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public int getAge() {
- return age;
- }
- public void setAge(int age) {
- this.age = age;
- }
- }
和前面的代码比起来,我们这里增加了几个描述属性。一个是@Table,这里通过它来设定对应的数据库表名字是什么。@Column这个用来设定对应的数据库字段名。还有一个比较有意思的地方就是我们在id字段增加了@GeneratedValue(strategy = GenerationType.IDENTITY)这个描述属性。它表示什么意思呢?它表示这个主键的值可以自动来生成,而后面的GenerationType.IDENTITY表明它的生成方式是自动增长,类似于auto increment.
针对前面修改之后我们再来看数据库的运行结果:
这样,经过前面这些步骤的描述,我们已经能够完成一个简单的JPA示例了。也因此知道了将对象如何映射到数据库表中。
各种关系映射
前面的示例是简单的将一个实体对象映射到数据库中。在很多实际的情况下,我们并不是简单的一个对象映射,往往对象和对象之间还存在着一定的关联关系。我们在做ORM的时候,也需要针对不同的情况进行考虑。这个就牵涉到数据库中间表或者实体对象之间的关系。总的来说,实体对象之间的关系无非为以下几种:一对一,一对多,多对多。而对于多对一的情况来说,从另外一个角度来看也是一种一对多的关系。
一对一
我们都知道,对于不管是哪种对应的关系,实际上他们在对应到数据库的实现里,我们是可以有几种不同的映射实现方式的。我们以一对一的关系开始。假设我们有一个Employee的实体对象。它同时有一个属性是Address。这个Address和它是一对一的映射关系。那么在数据库的实现里,我们该怎么考虑呢?
我们实际上有几种实现方式。一种很简单,既然他们反正是一对一的关系,我们完全可以把他们当成一个表来使。也就是说这个Address虽然是Employee的属性,但是他们所有的属性放到一个表里是完全没问题的。还有一种就是我们可以定义两个分离的表,他们之间通过外键关联。当然,除了这种,我们也可以定义一个单独的映射表来保存他们之间的映射关系。
现在我们来看看以上各种方式的实现:
合并成一个表
我们定义的Employee对象如下:
- package model;
- import javax.persistence.Embedded;
- import javax.persistence.Entity;
- import javax.persistence.Id;
- import javax.persistence.Table;
- @Entity
- @Table(name="Employee")
- public class Employee {
- @Id
- private int id;
- private String name;
- private long salary;
- @Embedded
- private Address address;
- public Address getAddress() {
- return address;
- }
- public void setAddress(Address address) {
- this.address = address;
- }
- public Employee() {}
- public Employee(int id) { this.id = id; }
- // ...
- }
这里出于篇幅的限制,省略了那些属性的get, set方法。
Address类的定义实现如下:
- package model;
- import javax.persistence.Access;
- import javax.persistence.AccessType;
- import javax.persistence.Column;
- import javax.persistence.Embeddable;
- @Embeddable
- public class Address {
- private String street;
- private String city;
- private String state;
- @Column(name="Zip_Code")
- private String zip;
- //...
- }
我们来看代码里加入的标注。这里Employee有一个Address的属性。我们在Employee里对这个属性增加了@Embedded标注。而定义Address的类里增加了@Embeddable标注。其中@Embedded表示Address元素被嵌入到Employee表中间。为了能够嵌入到Employee表中,我们还需要将Address属性增加@Embeddable,表示它是能够被嵌入到其他对象里面的。
我们运行如下的代码:
- package main;
- import javax.persistence.EntityManager;
- import javax.persistence.EntityManagerFactory;
- import javax.persistence.EntityTransaction;
- import javax.persistence.Persistence;
- import model.Address;
- import model.Employee;
- public class EmployeeTest {
- public static void main(String[] args) {
- EntityManagerFactory entityManagerFactory =
- Persistence.createEntityManagerFactory("EmployeeService");
- EntityManager em = entityManagerFactory.createEntityManager();
- EntityTransaction userTransaction = em.getTransaction();
- userTransaction.begin();
- Employee employee = new Employee();
- employee.setName("frank");
- employee.setSalary(2000);
- Address address = new Address();
- address.setCity("Beijing");
- address.setState("BJ");
- address.setStreet("Shuangying");
- address.setZip("100000");
- employee.setAddress(address);
- em.persist(employee);
- userTransaction.commit();
- em.close();
- entityManagerFactory.close();
- }
- }
我们现在来看数据库的结果:
外键约束
在采用这种外键约束的时候我们需要首先考虑一下。根据我们定义的逻辑关系,可以认为是Employee里有Address这么一个字段。那么就相当于Employee里要引用到Address的信息。而按照外键的定义,是一个表引用另外一个表的主键。那么,我们就需要给Address定义一个主键,同时我们也要标注一下在Employee里引用的Address字段该是什么名字。我们定义的Employee如下:
- package model;
- import javax.persistence.CascadeType;
- import javax.persistence.Entity;
- import javax.persistence.GeneratedValue;
- import javax.persistence.GenerationType;
- import javax.persistence.Id;
- import javax.persistence.JoinColumn;
- import javax.persistence.OneToOne;
- import javax.persistence.Table;
- @Entity
- @Table(name="Employee")
- public class Employee {
- @Id
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- private int id;
- private String name;
- private long salary;
- @OneToOne(cascade=CascadeType.ALL)
- @JoinColumn(name="address_id")
- private Address address;
- public Address getAddress() {
- return address;
- }
- public void setAddress(Address address) {
- this.address = address;
- }
- public Employee() {}
- public Employee(int id) { this.id = id; }
- // ...
- }
这里,我们增加了一个标注@OneToOne(cascade=CascadeType.ALL)和@JoinColumn(name="address_id")。@OneToOne表示他们是一对一的关系,同时cascade表示他们的级联关系。如果我们仔细观察一下的话会发现前面应用代码里有一个比较有趣的地方,我们em.persist()只是保存了employee对象。而对应的Address对象只是设定为employee对象的一个属性。我们希望是employee对象被保存到数据库里的时候address对象也自动保存进去。那么我们就需要设定这个cascade的级联访问属性。否则我们就需要显式的利用em.persist()来保存address对象。这也就是为什么我们要用一个cascade的属性。
@JoinColumn里面指定了Employee表里引用到Address时关联的名字是什么。
和前面的定义比较起来,Address的定义如要增加了一个id:
- @Id
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- private int id;
在我们运行程序前需要将Address加入到persistence.xml文件里。因为我们将它映射到一个单独的表里。我们再运行前面的程序,发现生成如下的表结构:
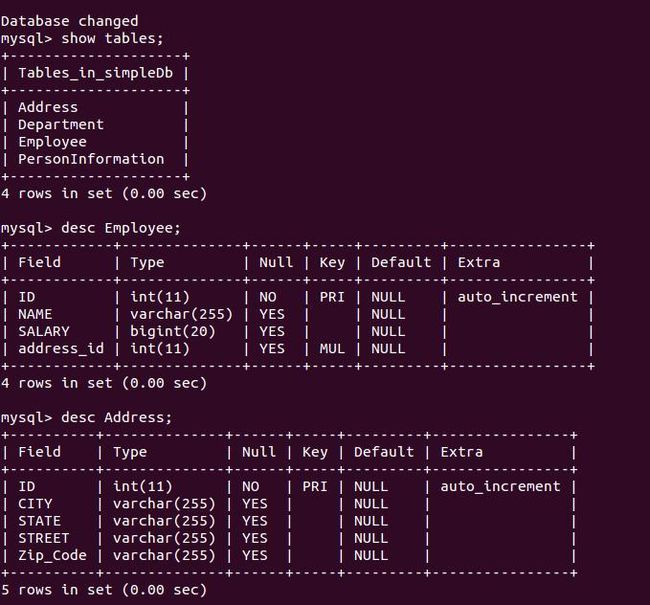
单独的映射表
采用这种映射方式的实现很简单,只需要在Employee里面做一点如下的修改:
- @OneToOne(cascade=CascadeType.ALL)
- @JoinTable(name="employee_address",joinColumns=@JoinColumn(name="address_id"),inverseJoinColumns=@JoinColumn(name="employee_id"))
- private Address address;
其他地方都不需要改变。这里的@JoinTable描述了关联表的名字,他们相互关联的时候里面包含的字段。一个为address_id,一个为employee_id。
运行结果如下图:

一对多
讨论完了前面的一对一映射,我们再来看看一对多的关系。其实和前面一对一的关系很类似,我们可以猜想得到,既然前面描述一对一的关系有@OneToOne,我们这里应该有@OneToMany的映射关系。而且比较有意思的是,在JPA里,除了一对多的关系,也存在着一个多对一的关系描述。那么,在哪些情况下该使用一对多来描述,哪些情况下用多对一来描述呢?我觉得这主要还是取决于我们设计的对象逻辑关系。通过对象的逻辑关系来设置不同的选择。
我们来看一个示例。
Many to one
假定我们有一个Employee类,然后还有一个Department类。对于每个Employee来说,他属于且仅属于一个Department。这样对于Employee和Department来说,他们就构成一个多对一的关系。而从Department的角度来说,他们则是一个一对多的关系。假定我们要求Employee对象有一个方法来取得他所在的Department。这样从面向对象的角度来说,我们可能希望Employee有一个指向Department的引用。于是按照这种思路,我们设计Employee的代码如下:
- package model;
- import javax.persistence.CascadeType;
- import javax.persistence.Entity;
- import javax.persistence.GeneratedValue;
- import javax.persistence.GenerationType;
- import javax.persistence.Id;
- import javax.persistence.JoinColumn;
- import javax.persistence.ManyToOne;
- import javax.persistence.Table;
- @Entity
- @Table(name="Employee")
- public class Employee {
- @Id
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- private int id;
- private String name;
- private long salary;
- @ManyToOne(cascade=CascadeType.ALL)
- @JoinColumn(name="Dept_Id")
- private Department department;
- public Employee() {}
- public Employee(int id) { this.id = id; }
- // ...
- }
这里我们省略了对所有属性get, set方法。这里用了一个@ManyToOne的标注。并设定了映射的名字为“Dept_Id”。
而Department的定义则如下:
- package model;
- import javax.persistence.Column;
- import javax.persistence.Entity;
- import javax.persistence.GeneratedValue;
- import javax.persistence.GenerationType;
- import javax.persistence.Id;
- import javax.persistence.Table;
- @Entity
- @Table(name="Department")
- public class Department {
- @Id
- @Column(name="Dept_Id")
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- private long id;
- @Column(name="name")
- private String name;
- // ...
- }
这个类的定义则没有什么特殊的。和前面定义的差不多。
运行完之后的数据库情况如下:
One to many
还是前面那个示例,不过这次我们换一个角度来考虑一下。前面是我们希望Employee有一个取得所在Department的属性的方式。这里我们希望从Department对象得到里面所有的员工。从面向对象的角度来说,我们可以在Department里面定义一个集合类来保存一系列的Employee对象。那么,这里两个类的定义形式则如下:
Employee:
- package model;
- import javax.persistence.Entity;
- import javax.persistence.GeneratedValue;
- import javax.persistence.GenerationType;
- import javax.persistence.Id;
- import javax.persistence.Table;
- @Entity
- @Table(name="Employee")
- public class Employee {
- @Id
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- private int id;
- private String name;
- private long salary;
- public Employee() {}
- public Employee(int id) { this.id = id; }
- // ...
- }
Employee的定义基本上不需要做什么特殊的关系映射定义。
Department:
- package model;
- import java.util.List;
- import javax.persistence.CascadeType;
- import javax.persistence.Column;
- import javax.persistence.Entity;
- import javax.persistence.FetchType;
- import javax.persistence.GeneratedValue;
- import javax.persistence.GenerationType;
- import javax.persistence.Id;
- import javax.persistence.JoinColumn;
- import javax.persistence.OneToMany;
- import javax.persistence.Table;
- @Entity
- @Table(name="Department")
- public class Department {
- @Id
- @Column(name="Dept_Id")
- @GeneratedValue(strategy = GenerationType.IDENTITY)
- private long id;
- @Column(name="name")
- private String name;
- @OneToMany(cascade=CascadeType.ALL,fetch=FetchType.LAZY)
- @JoinColumn(name="Dept_Id")
- private List<Employee> employees;
- // ...
- }
这里一个比较有意思的地方是在定义了employees的地方加了一个@OneToMany的标注。它同时也通过@JoinColumn说明了关联的项。
这里我们运行的程序稍微修改了一下,代码如下:
- package main;
- import java.util.ArrayList;
- import java.util.List;
- import javax.persistence.EntityManager;
- import javax.persistence.EntityManagerFactory;
- import javax.persistence.EntityTransaction;
- import javax.persistence.Persistence;
- import model.Department;
- import model.Employee;
- public class EmployeeTest {
- public static void main(String[] args) {
- EntityManagerFactory entityManagerFactory =
- Persistence.createEntityManagerFactory("EmployeeService");
- EntityManager em = entityManagerFactory.createEntityManager();
- EntityTransaction userTransaction = em.getTransaction();
- userTransaction.begin();
- Employee employee = new Employee();
- Department dept = new Department();
- dept.setName("Information");
- List<Employee> employees = new ArrayList<Employee>();
- employee.setName("frank");
- employee.setSalary(2000);
- employees.add(employee);
- employee = new Employee();
- employee.setName("fred");
- employee.setSalary(3000);
- employees.add(employee);
- dept.setEmployees(employees);
- em.persist(dept);
- userTransaction.commit();
- em.close();
- entityManagerFactory.close();
- }
- }
我们写入了一个Employee的集合。所以最后运行结果生成的表和结果如下:
和我们前面一对一映射的关系类似。我们也可以将一对多或者多对一的关系用一个中间关系表来保存。在这里实现就很简单,之需要将Department里面的@JoinColumn去掉就可以了。因为在JPA里,如果我们设定了两个对象之间的一对多属性关系,它会默认生成一个中间表,并且表名以两个表的名字加一个下划线拼接起来。
多对多
对于多对多的场景,看起来它会显得更复杂一些。实际上则未必。因为当我们典型的针对这种关系来设计数据库表的时候,肯定会考虑将他们拆分出一个中间的映射表来。这样的话,基本上要实现这样关系的映射,肯定就只有拆分映射表这么一条路。这里定义了另外一个示例。假定Student和Department是一个多对多的关系。
这里,我们定义了Student:
- package model;
- import java.util.ArrayList;
- import java.util.Collection;
- import javax.persistence.Entity;
- import javax.persistence.GeneratedValue;
- import javax.persistence.GenerationType;
- import javax.persistence.Id;
- import javax.persistence.JoinColumn;
- import javax.persistence.JoinTable;
- import javax.persistence.ManyToMany;
- @Entity
- public class Student {
- @Id @GeneratedValue(strategy=GenerationType.IDENTITY)
- private int id;
- private String name;
- @ManyToMany
- @JoinTable(name="Student_Dept",
- joinColumns=@JoinColumn(name="Stut_ID"),
- inverseJoinColumns=@JoinColumn(name="DEPT_ID"))
- private Collection<Department> departments;
- public Student() {
- departments = new ArrayList<Department>();
- }
- public void addDepartment(Department department) {
- if (!getDepartments().contains(department)) {
- getDepartments().add(department);
- }
- if (!department.getStudents().contains(this)) {
- department.getStudents().add(this);
- }
- }
- public String toString() {
- return "\n\nID:" + id + "\nName:" + name ;
- }
- // ...
- }
这里省略了元素的get, set方法。为了实现对象的双向关联,这里定义的addDepartment需要将自己加入到目标Department对象的列表里。另外,我们在对多的关系部分添加了一个@ManyToMany的标注,同时也指定@JoinTable的属性。
而对于Department:
- package model;
- import java.util.ArrayList;
- import java.util.Collection;
- import javax.persistence.Entity;
- import javax.persistence.GeneratedValue;
- import javax.persistence.GenerationType;
- import javax.persistence.Id;
- import javax.persistence.ManyToMany;
- @Entity
- public class Department {
- @Id @GeneratedValue(strategy=GenerationType.IDENTITY)
- private int id;
- private String name;
- @ManyToMany(mappedBy="departments")
- private Collection<Student> students;
- public Department(){
- students = new ArrayList<Student>();
- }
- public void addStudent(Student student) {
- if (!getStudents().contains(student)) {
- getStudents().add(student);
- }
- if (!student.getDepartments().contains(this)) {
- student.getDepartments().add(this);
- }
- }
- public String toString() {
- return "Department id: " + getId() +
- ", name: " + getName();
- }
- // ...
- }
这里引用Student集合的地方也用了一个@ManyToMany的标注,同时,里面还设置了一个mappedBy属性。这个属性有什么用呢?它是指定我们这个students的集合是映射到Student类里面的departments列表。这样后面生成的对象才找到对应的映射一方。还有一个就是,既然是多对多的映射,在Student里面定义了jointable的属性,这和我们在Department里面定义有什么差别呢?
这个问题在于我们想定义这个关系的拥有方。我们把jointable的定义放在哪个类这个类就成为了拥有方。那么这个拥有方来绑定和解除他们的关系。另外一方则不能用来绑定和解除他们的关系。
我们调用的代码实现如下:
- package main;
- import java.util.List;
- import javax.persistence.EntityManager;
- import javax.persistence.EntityManagerFactory;
- import javax.persistence.Persistence;
- import javax.persistence.Query;
- import model.Department;
- import model.Student;
- public class Main {
- static EntityManagerFactory emf = Persistence.createEntityManagerFactory("EmployeeService");
- static EntityManager em = emf.createEntityManager();
- public static void main(String[] a) throws Exception {
- em.getTransaction().begin();
- Student student = new Student();
- student.setName("Joe");
- em.persist(student);
- Student student1 = new Student();
- student1.setName("Joe");
- em.persist(student1);
- Department dept = new Department();
- dept.setName("dept name");
- dept.addStudent(student);
- dept.addStudent(student1);
- em.persist(dept);
- em.flush();
- Query query = em.createQuery("SELECT e FROM Student e");
- List<Student> list = (List<Student>) query.getResultList();
- System.out.println(list);
- query = em.createQuery("SELECT d FROM Department d");
- List<Department> dList = (List<Department>) query.getResultList();
- System.out.println(dList);
- em.getTransaction().commit();
- em.close();
- emf.close();
- }
- }
这里,我们添加了两个Student对象到一个Department对象中。他们运行后的数据表结构如下:

多对多关系对应的对象关系还有一个比较麻烦的地方在于。一旦建立了双方的对象关系之后,就基本上形成了一个对象之间的循环引用。从面向对象的角度来说这不是一个合适的设计。另外,从内存管理的角度来看,这样也容易导致内存泄漏。因为我们一不小心就容易导致一些引用的对象没有被释放。在将这些关系映射到不同对象的时候,一定要非常的慎重。
总结
以前使用一些语言和开发框架的时候用到ORM。这里针对一个最基本的JPA示例一并探讨了几种典型的对象映射关系在JPA中的实现。有了这些对象关系的定义作为基础我们可以定义很多面向对象的方法而不用采取直接拼接sql字符串的方式与数据库交互。由于要针对这些关系一一讨论,本文的篇幅就会显得长一些。
参考材料
pro jpa2
http://www.java2s.com/Tutorial/Java/0355__JPA/ManyToManyJoinTableJoinInverseJoinColumn.htm