Linux I/O及 I/O Cache
总结一下平时使用的文件操作方法:
1. 通过标准c的库函数访问文件
2. 通过Linux系统调用访问文件
3. 通过内存映射(mmap)访问文件
其中,标准c的库函数里,实际也是调用了系统调用完成IO,但是库函数有自己的缓存机制。内存映射是将文件映射到虚存中的一块空间,将文件读写操作转变成了页交换操作。
默认情况下这三种方式都会使用文件系统的页缓存( page cache ),也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。缓存 I/O 有以下这些优点:
- 缓存 I/O 使用了操作系统内核缓冲区,在一定程度上分离了应用程序空间和实际的物理设备。
- 缓存 I/O 可以减少读盘的次数,从而提高性能
在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输,这样的话,数据在传输过程中需要在应用程序地址空间和页缓存之间进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
Linux 中的直接 I/O 技术非常适用于自缓存这类应用程序,该技术省略掉缓存 I/O 技术中操作系统内核缓冲区的使用,数据直接在应用程序地址空间和磁盘之间进行传输,从而使得自缓存应用程序可以省略掉复杂的系统级别的缓存结构,而执行程序自己定义的数据读写管理,从而降低系统级别的管理对应用程序访问数据的影响。例如,关系型数据库一般都会使用直接IO。
下面是一组实验数据:
读取1.7G的数据,各种文件读取方式的时间成本为:
1. 标准c的库函数fread():
首次读取: 14.756932 s
再次读取:1.930997 s
2. 通过Linux系统调用read()访问文件:
首次读取:14.069852 s
再次读取:1.858485
3. 通过内存映射mmap()访问文件:
首次读取:
11.798804 s
再次读取:2.101747 s
4.
通过Linux系统调用read(O_DIRECT)访问文件,访问方式为直接IO:
首次读取:
14.1502176 s
再次读取:14.2386592 s
通过上述实验证实,
read(O_DIRECT)的第二次读写没有使用缓存。
篇外话:
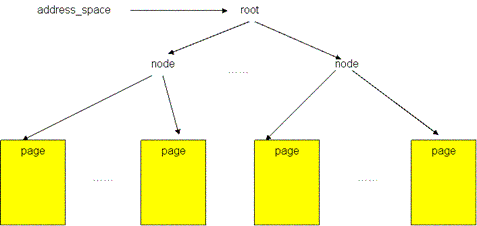
文件的 page cache 结构图1显示了一个文件的 page cache 结构。文件被分割为一个个以 page 大小为单元的数据块,这些数据块(页)被组织成一个多叉树(称为 radix 树)。树中所有叶子节点为一个个页帧结构(struct page),表示了用于缓存该文件的每一个页。在叶子层最左端的第一个页保存着该文件的前4096个字节(如果页的大小为4096字节),接下来的页保存着文件第二个4096个字节,依次类推。树中的所有中间节点为组织节点,指示某一地址上的数据所在的页。此树的层次可以从0层到6层,所支持的文件大小从0字节到16 T 个字节。树的根节点指针可以从和文件相关的 address_space 对象(该对象保存在和文件关联的 inode 对象中)中取得(更多关于 page cache 的结构内容请参见参考资料)。
图1 文件的 page cache 结构
对于我们用来做实验的K均值算法,是一个迭代的过程,当数据量超过集群总内存大小的时候,已经无法建立完整的缓存,新数据的缓存覆盖了旧数据的缓存,所以在当前迭代过程中,实际上并没有使用到上次迭代建立的缓存。
两条路:
1,使用直接IO,在应用程序中建立完全属于自己的缓存机制。缓存替换机制与应用相关。
2,深入内核,调整Page Cache的替换机制。
对于迭代式的应用,可以通过调整文件块的读取顺序,使下次迭代可使用到一部分本次迭代的缓存。
通过MPI-KMeans的实验,提高了近50%的速度。