Hadoop源代码分析【IO专题-序列化机制】
1. 基本概念
序列化可被定义为将对象的状态存储到存储媒介中的过程。在此过程中,对象的公共字段和私有字段以及类的名称(包括包含该类的程序集)都被转换为字节流,然后写入数据流。在以后反序列化该对象时,创建原始对象的精确复本。
当在面向对象的环境中实现序列化机制时,您需要在简化使用和保持灵活性之间进行许多权衡。只要您对该过程具有充分的控制,就可以在很大程度上自动化该过程。例如,在简单二进制序列化不充分时可能导致一些情况发生,或者可能有特定原因确定在类中哪些字段需要进行序列化。Serialization is the process of turning structured objects into a byte stream for trans-mission over a network or for writing to persistent storage. Deserialization is the process of turning a byte stream back into a series of structured objects.
Serialization appears in two quite distinct areas of distributed data processing: for interprocess communication and for persistent storage.
In Hadoop, interprocess communication between nodes in the system is implemented using remote procedure calls (RPCs). The RPC protocol uses serialization to render the message into a binary stream to be sent to the remote node, which then deserializes the binary stream into the original message. In general, it is desirable that an RPC serialization format is:
n 数据设计紧凑,充分利用网络带宽
n 系列化和反序列化的工程能够迅速完成
n 协议时高可扩展的
n 支持互操作
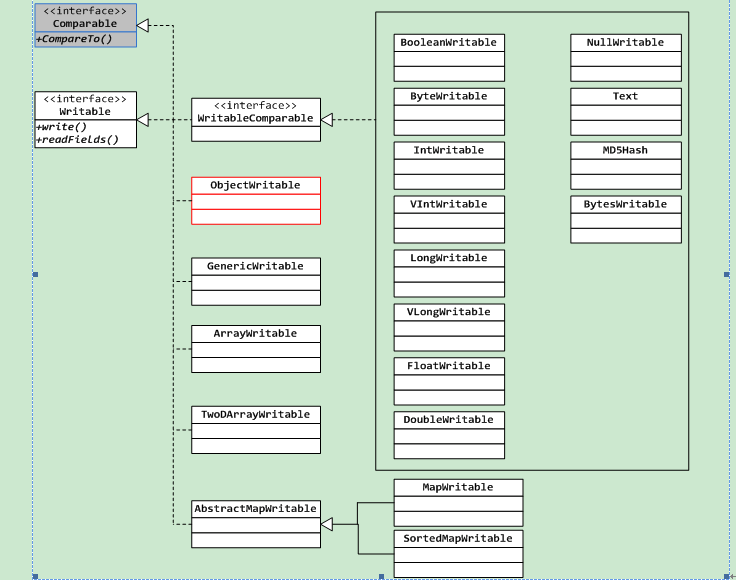
Hadoop的系列化是通过Writable接口来实现的,只满足了前两条设计,在org.apache.hadoop.io包下包含了大量的可序列化的组件,它们都实现了Writable接口,Writable接口提供了两个方法,write和readFields,分别用来序列化和反序列化,实现该接口的典型例子如下:
public class MyWritable implements Writable {
// some data
private int counter;
private long timestamp;
// 序列化方法
public void write(DataOutput out) throws IOException {
out.writeInt(counter);
out.writeLong(timestamp);
}
// 反序列化方法
public void readFields(DataInput in) throws IOException {
counter = in.readInt();
timestamp = in.readLong();
}
// 反序列化的对外使用接口
public static MyWritable read(DataInput in) throws IOException {
MyWritable w = new MyWritable();
w.readFields(in);
return w;
}
}
2. 比较器
在Map/Reduce中有多处要进行排序,所以元素的相互比较是比较重要的,Hadoop中通过如下几个接口和类来支持比较操作:
1) WritableComparable
public interface WritableComparable<T> extends Writable, Comparable<T> {
}
2) RawComparator
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
This interface permits implementors to compare records read from a stream without
deserializing them into objects, thereby avoiding any overhead of object creation.
3) WritableComparator
is a general-purpose implementation of RawComparator for WritableComparable classes. It provides two main functions:
First, it provides a default implementation of the raw compare() method that deserializes the objects to be compared from the stream and invokes the object compare() method.
Second, it acts as a factory for RawComparator instances (that Writable implementations have registered,通过一个HashMap<Class, WritableComparator> comparators来保持所有注册的comparator).For example, to obtain a comparator for IntWritable, we just use:
RawComparator<IntWritable> comparator = WritableComparator.get(IntWritable.class);
获得这个comparator之后就可以来比较两个IntWritable的对象:
IntWritable w1 = new IntWritable(100);
IntWritable w2 = new IntWritable(101);
assertThat(comparator.compare(w1,w2), greatherThan(0));
或者对序列化的对象进行比较:
byte[] b1 = serialize(w1);
byte[] b2 = serialize(w2);
assertThat(comparator.compare(b1,0,b1.length, b2, 0, b2.length), greatherThan(0));
3. Writable Classes
Hadoop提供的可序列化的类型主要分成如下几种:
1) Java基本数据类型
There are Writable wrappers for all the Java primitive types except short and char (both of which can be stored in an IntWritable). All have a get() and a set() method for retrieving and storing the wrapped value.
| Java 基本数据类型 |
Writable实现 |
Serialized size(bytes) |
| boolean |
BooleanWritable |
1 |
| byte |
ByteWritable |
1 |
| int |
IntWritable |
4 |
| VIntWritable |
1-5 |
|
| float |
FloatWritable |
4 |
| long |
LongWritable |
8 |
| VLongWritable |
1-9 |
|
| double |
DoubleWritable |
8 |
2) Text
Text is a Writable for UTF-8 sequences, the max length is 2GB, 这个类的系列化和反序列化都是比较显而易见的,实现上大部分代码在做 UTF-8编解码和String(java中的String用的是unicode)的转换等。
3) BytesWritable
BytesWritable is a wrapper for an array of binary data. Its serialized format is an integer field (4 bytes) that specifies the number of bytes to follow, followed by the bytes them-
selves. For example, the byte array of length two with values 3 and 5 is serialized as a
4-byte integer (00000002) followed by the two bytes from the array (03 and 05):
BytesWritable b = new BytesWritable(new byte[] { 3, 5 });
byte[] bytes = serialize(b);
assertThat(StringUtils.byteToHexString(bytes), is("000000020305"));
BinaryComparable是针对array of binary data而设计的比较器!
4) NullWritable
NullWritable is a special type of Writable, as it has a zero-length serialization. No bytes are written to, or read from, the stream. It is used as a placeholder; for example, in MapReduce, a key or a value can be declared as a NullWritable when you don’t need to use that position—it effectively stores a constant empty value.
5) ObjectWritable和GenericWritable
ObjectWritable is a general-purpose wrapper for the following: Java primitives, String, enum, Writable, null, or arrays of any of these types. It is used in Hadoop RPC to marshal(包装) and unmarshal method arguments and return types. 其实主要的通途就是对多于1个的域组成对象进行序列化!在对端进行反序列化的时候用到了WritableFactory和WritableFactories(用来根据类名来生成对象)
6) Writable Collections
There are four Writable collection types in the org.apache.hadoop.io package: Array Writable, TwoDArrayWritable, MapWritable, and SortedMapWritable.
ArrayWritable and TwoDArrayWritable are Writable implementations for arrays andtwo-dimensional arrays (array of arrays) of Writable instances. All the elements of an
ArrayWritable or a TwoDArrayWritable must be instances of the same class, which is
specified at construction, as follows:
ArrayWritable writable = new ArrayWritable(Text.class);
MapWritable and SortedMapWritable are implementations of java.util.Map<Writable,Writable> and java.util.SortedMap<WritableComparable, Writable>, respectively. The type of each key and value field is a part of the serialization format for that field.