Java集合框架官方教程(1):Collection/Set/List接口
概述
一个集合,即collection,有时也被称为一个容器,是将多个元素聚集成一个单元的对象。Collections常被用来存储、检索、操纵聚集数据以及聚集数据间的通信。一般来说,Collections表示一组自然类群的数据项,比如一手扑克牌、一个信箱(由很多信件组成)或者电话簿(一组姓名到电话号码的映射)。 如果你熟悉Java语言或者任何一门其他编程语言,你可能已经对Collections比较熟悉了。
什么是集合框架?
一个集合框架是一个统一的构架,用于表示和操纵集合。所有集合框架都包含下面几项:
接口:即表示集合的抽象数据类型,ADT。接口使得在使用集合时不需要关注集合的实现细节。在面向对象语言中,接口一般会形成层次结构。
实现:集合接口的具体实现。实际上它们是可复用的数据结构。
算法:在实现集合接口的对象上进行的各种有意义的计算,如搜索、排序。实际上,算法是可复用的功能单元。
除了Java集合框架以外,其他有名的集合框架有C++ STL和Smalltalk语言的集合层次架构。历史上,集合框架因为他们相当复杂而具有相当陡峭的学习曲线,并因此而恶名昭著。Java集合框架则打破了这个传统。
使用Java集合框架的好处
Java集合框架提供了下面的好处:
减轻编程负担:集合框架通过提供有用的数据结构和算法,使得我们从底层算法中解脱出来而能更专注于代码逻辑。
提高编程效率和编程质量:Java集合框架提供了各种有用的数据结构算法的高性能、高质量实现。因为程序员从自己实现各种数据结构的艰苦工作中解放出来,因此有更多时间用来改善程序质量和程序性能。
允许互操作性
减少了学习和使用新API的负担
减少了设计新API的负担
促进软件复用:符合标准集合接口的新数据结构天生可复用。操作于实现集合接口的对象上的新算法亦然。
接口
核心集合接口封装了不同类型的集合,如下图所示。这些接口使得我们可以操作集合而不必关心它们的具体实现细节。核心集合接口是Java集合框架的基础。正如我们可以从下图看到的,核心集合接口形成了层次结构:
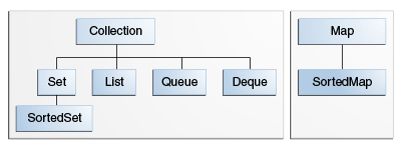
图1 核心集合接口
Set是一种特殊的集合,而一个SortedSet是一种特殊的Set,以此类推。注意上图的层次结构中包含两棵独立的树 — Map不是一个真正意义上的集合。
注意所有的核心集合接口都是泛型化的(generic)。例如下面是Collection接口的声明:
public interface Collection<E>...<E>语法告诉我们这个接口是泛型化的。当我们声明一个集合实例时,我们可以也必需指定集合中对象的类型。指定类型使得编译器能在编译时验证集合中的元素的类型都是正确的,从而减少运行时错误。如果想获取更多的关于泛型的信息,敬请参考 Java Generic Turtorial 。
当你学会使用这些接口后,你就了解了Java集合框架中的大部分内容。本章讨论关于如何有效使用这些接口的一些建议,包括何时使用何种接口。我们也将学会每个接口的一些习惯用法。
为了保证核心集合接口的数量可控,Java平台没有为每一种集合类型的变种(如不可变集合、固定大小集合以及只可追加集合)都提供单独的接口。相反,每个集合接口上的修改操作都被设计成可选的,也就是某个集合接口的实现可能不会支持所有的修改操作。如果调用集合不支持的一个操作,将抛出UnsupportedOperationException。集合接口的实现必需用文档记录它支持哪些可选操作。
The following list describes the core collection interfaces:
Collection— the root of the collection hierarchy. A collection represents a group of objects known as its elements.TheCollectioninterface is the least common denominator that all collections implement and is used to pass collections around and to manipulate them when maximum generality is desired. Some types of collections allow duplicate elements, and others do not. Some are ordered and others are unordered. The Java platform doesn't provide any direct implementations of this interface but provides implementations of more specific subinterfaces, such asSetandList. Also see The Collection Interface section.Set— a collection that cannot contain duplicate elements.This interface models the mathematical set abstraction and is used to represent sets, such as the cards comprising a poker hand, the courses making up a student's schedule, or the processes running on a machine. See also The Set Interface section.List— an ordered collection (sometimes called a sequence).Lists can contain duplicate elements.The user of aListgenerally has precise control over where in the list each element is inserted and can access elements by their integer index (position). If you've usedVector, you're familiar with the general flavor ofList. Also seeThe List Interface section.Queue— a collection used to hold multiple elements prior to processing. Besides basicCollectionoperations, aQueueprovides additional insertion, extraction, and inspection operations.Queues typically, but do not necessarily, order elements in a FIFO (first-in, first-out) manner. Among the exceptions are priority queues, which order elements according to a supplied comparator or the elements' natural ordering. Whatever the ordering used,the head of the queue is the element that would be removed by a call to
removeorpoll. In a FIFO queue, all new elements are inserted at the tail of the queue. Other kinds of queues may use different placement rules. EveryQueueimplementation must specify its ordering properties. Also seeThe Queue Interface section.Deque— a collection used to hold multiple elements prior to processing. Besides basicCollectionoperations, aDequeprovides additional insertion, extraction, and inspection operations.Deques can be used both as FIFO (first-in, first-out) and LIFO (last-in, first-out). In a deque all new elements can be inserted, retrieved and removed at both ends. Also see The Deque Interface section.
Map— an object that maps keys to values.AMapcannot contain duplicate keys; each key can map to at most one value. If you've usedHashtable, you're already familiar with the basics ofMap. Also see The Map Interface section.
The last two core collection interfaces are merely sorted versions of Set and Map:
SortedSet— aSetthat maintains its elements in ascending order. Several additional operations are provided to take advantage of the ordering.Sorted sets are used for naturally ordered sets, such as word lists and membership rolls. Also seeThe SortedSet Interface section.SortedMap— aMapthat maintains its mappings in ascending key order. This is theMapanalog ofSortedSet.Sorted maps are used for naturally ordered collections of key/value pairs, such as dictionaries and telephone directories.Also see The SortedMap Interface section.
To understand how the sorted interfaces maintain the order of their elements, see the Object Ordering section.
The Collection Interface
A Collection represents a group of objects known as its elements. The Collection interface is used to pass around collections of objects where maximum generality is desired. For example, by convention all general-purpose collection implementations have a constructor that takes a Collection argument. This constructor, known as a conversion constructor, initializes the new collection to contain all of the elements in the specified collection, whatever the given collection's subinterface or implementation type. In other words, it allows you to convert the collection's type.
Suppose, for example, that you have a Collection<String> c, which may be aList, a Set, or another kind ofCollection. This idiom creates a new ArrayList (an implementation of theList interface), initially containing all the elements in c.
List<String> list = new ArrayList<String>(c);
Or — if you are using JDK 7 or later — you can use the diamond operator:
List<String> list = new ArrayList<>(c);The
Collection interface contains methods that perform basic operations, such as
int size(),
boolean isEmpty(),
boolean contains(Object element),
boolean add(E element),
boolean remove(Object element), and
Iterator<E> iterator().
It also contains methods that operate on entire collections, such as boolean containsAll(Collection<?> c),boolean addAll(Collection<? extends E> c),boolean removeAll(Collection<?> c),boolean retainAll(Collection<?> c), and void clear().
Additional methods for array operations(such as Object[] toArray() and<T> T[] toArray(T[] a) exist as well.
In JDK 8 and later, the Collection interface also exposes methods Stream<E> stream() and Stream<E> parallelStream(), for obtaining sequential or parallel streams from the underlying collection. (See the lesson entitledAggregate Operations for more information about using streams.)
The Collection interface does about what you'd expect given that aCollection represents a group of objects. It has methods that tell you how many elements are in the collection (size,isEmpty), methods that check whether a given object is in the collection (contains), methods that add and remove an element from the collection (add,remove), and methods that provide an iterator over the collection (iterator).
add method is defined generally enough so that it makes sense for collections that allow duplicates as well as those that don't. It guarantees that the
Collection will contain the specified element after the call completes,
and returns true if the Collection changes as a result of the call. Similarly, the
remove method is designed to remove a single instance of the specified element from the
Collection, assuming that it contains the element to start with, and to return
true if the
Collection was modified as a result.
Traversing Collections
There are three ways to traverse collections: (1) using aggregate operations (2) with thefor-each construct and (3) by usingIterators.
Aggregate Operations
In JDK 8 and later, the preferred method of iterating over a collection is to obtain a stream and perform aggregate operations on it. Aggregate operations are often used in conjunction with lambda expressions to make programming more expressive, using less lines of code. The following code sequentially iterates through a collection of shapes and prints out the red objects:
myShapesCollection.stream() .filter(e -> e.getColor() == Color.RED) .forEach(e -> System.out.println(e.getName()));
Likewise, you could easily request a parallel stream, which might make sense if the collection is large enough and your computer has enough cores:
myShapesCollection.parallelStream() .filter(e -> e.getColor() == Color.RED) .forEach(e -> System.out.println(e.getName()));There are many different ways to collect data with this API. For example, you might want to convert the elements of a
Collection to
String objects, then join them, separated by commas:
String joined = elements.stream()
.map(Object::toString)
.collect(Collectors.joining(", "));
Or perhaps sum the salaries of all employees:
int total = employees.stream() .collect(Collectors.summingInt(Employee::getSalary)));These are but a few examples of what you can do with streams and aggregate operations. For more information and examples, see the lesson entitled Aggregate Operations.
The Collections framework has always provided a number of so-called "bulk operations" as part of its API. These include methods that operate on entire collections, such ascontainsAll, addAll,removeAll, etc. Do not confuse those methods with the aggregate operations that were introduced in JDK 8.The key difference between the new aggregate operations and the existing bulk operations (containsAll, addAll, etc.) is thatthe old versions are all mutative, meaning that they all modify the underlying collection. In contrast, the new aggregate operations do notmodify the underlying collection. When using the new aggregate operations and lambda expressions, you must take care to avoid mutation so as not to introduce problems in the future, should your code be run later from a parallel stream.
for-each Construct
The for-each construct allows you to concisely traverse a collection or array using afor loop — see The for Statement. The following code uses the for-each construct to print out each element of a collection on a separate line.
for (Object o : collection)
System.out.println(o);
Iterator
An Iterator is an object that enables you to traverse through a collection and to remove elements from the collection selectively, if desired. You get anIterator for a collection by calling itsiterator method. The following is the Iterator interface.
public interface Iterator<E> {
boolean hasNext();
E next();
void remove(); //optional
}
The hasNext method returns true if the iteration has more elements, and thenext method returns the next element in the iteration. The remove method removes the last element that was returned by next from the underlyingCollection. The remove method may be called only once per call tonext and throws an exception if this rule is violated.
Note that Iterator.remove is the only safe way to modify a collection during iteration; the behavior is unspecified if the underlying collection is modified in any other way while the iteration is in progress.
Use Iterator instead of the for-each construct when you need to:
- Remove the current element. The
for-eachconstruct hides the iterator, so you cannot callremove. Therefore, thefor-eachconstruct is not usable for filtering. - Iterate over multiple collections in parallel.
The following method shows you how to use an Iterator to filter an arbitraryCollection — that is, traverse the collection removing specific elements.
static void filter(Collection<?> c) {
for (Iterator<?> it = c.iterator(); it.hasNext(); )
if (!cond(it.next()))
it.remove();
}
This simple piece of code is polymorphic, which means that it works for any Collection regardless of implementation. This example demonstrates how easy it is to write a polymorphic algorithm using the Java Collections Framework.
Collection Interface Bulk Operations
Bulk operations perform an operation on an entire Collection. You could implement these shorthand operations using the basic operations, though in most cases such implementations would be less efficient. The following are the bulk operations:
containsAll— returnstrueif the targetCollectioncontains all of the elements in the specifiedCollection.addAll— adds all of the elements in the specifiedCollectionto the targetCollection.removeAll— removes from the targetCollectionall of its elements that are also contained in the specifiedCollection.retainAll— removes from the targetCollectionall its elements that arenot also contained in the specifiedCollection. That is, it retains only those elements in the targetCollectionthat are also contained in the specifiedCollection.clear— removes all elements from theCollection.
The addAll, removeAll, andretainAll methods all returntrue if the targetCollection was modified in the process of executing the operation.
As a simple example of the power of bulk operations, consider the following idiom to removeall instances of a specified element,e, from a Collection,c.
c.removeAll(Collections.singleton(e));More specifically, suppose you want to remove all of the
null elements from a
Collection.
c.removeAll(Collections.singleton(null));
This idiom uses Collections.singleton, which is a static factory method that returns an immutableSet containing only the specified element.
Collection Interface Array Operations
The toArray methods are provided as a bridge between collections and older APIs that expect arrays on input. The array operations allow the contents of aCollection to be translated into an array. The simple form with no arguments creates a new array ofObject. The more complex form allows the caller to provide an array or to choose the runtime type of the output array.
For example, suppose that c is a Collection. The following snippet dumps the contents ofc into a newly allocated array of Object whose length is identical to the number of elements inc.
Object[] a = c.toArray();Suppose that
c is known to contain only strings (perhaps because
c is of type
Collection<String>). The following snippet dumps the contents of
c into a newly allocated array of
String whose length is identical to the number of elements in
c.
String[] a = c.toArray(new String[0]);
The Set Interface
A Set is a Collection that cannot contain duplicate elements. It models the mathematical set abstraction. TheSet interface contains only methods inherited from Collection and adds the restriction that duplicate elements are prohibited.Set also adds a stronger contract on the behavior of theequals andhashCode operations, allowing Set instances to be compared meaningfully even if their implementation types differ. TwoSet instances are equal if they contain the same elements.
The Java platform contains three general-purpose Set implementations:HashSet,TreeSet,and LinkedHashSet. HashSet, which stores its elements in a hash table, is the best-performing implementation; however it makes no guarantees concerning the order of iteration.TreeSet, which stores its elements in a red-black tree, orders its elements based on their values; it is substantially slower thanHashSet. LinkedHashSet, which is implemented as a hash table with a linked list running through it, orders its elements based on the order in which they were inserted into the set (insertion-order).LinkedHashSet spares its clients from the unspecified, generally chaotic ordering provided by HashSet at a cost that is only slightly higher.
Here's a simple but useful Set idiom. Suppose you have a Collection, c, and you want to create another Collection containing the same elements but with all duplicates eliminated. The following one-liner does the trick.
Collection<Type> noDups = new HashSet<Type>(c);
It works by creating a Set (which, by definition, cannot contain duplicates), initially containing all the elements inc. It uses the standard conversion constructor described in theThe Collection Interface section.
Or, if using JDK 8 or later, you could easily collect into aSet using aggregate operations:
c.stream() .collect(Collectors.toSet()); // no duplicatesHere's a slightly longer example that accumulates a
Collection of names into a
TreeSet:
Set<String> set = people.stream() .map(Person::getName) .collect(Collectors.toCollection(TreeSet::new));And the following is a minor variant of the first idiom that preserves the order of the original collection while removing duplicate elements:
Collection<Type> noDups = new LinkedHashSet<Type>(c);The following is a generic method that encapsulates the preceding idiom, returning a
Set of the same generic type as the one passed.
public static <E> Set<E> removeDups(Collection<E> c) {
return new LinkedHashSet<E>(c);
}
Set Interface Basic Operations
The size operation returns the number of elements in the Set (its cardinality). The isEmpty method does exactly what you think it would. Theadd method adds the specified element to the Set if it is not already present and returns a boolean indicating whether the element was added. Similarly, theremove method removes the specified element from the Set if it is present and returns a boolean indicating whether the element was present. Theiterator method returns an Iterator over the Set.
The following program prints out all distinct words in its argument list.Two versions of this program are provided. The first uses JDK 8 aggregate operations. The second uses the for-each construct.
Using JDK 8 Aggregate Operations:
import java.util.*;
import java.util.stream.*;
public class FindDups {
public static void main(String[] args) {
Set<String> distinctWords = Arrays.asList(args).stream()
.collect(Collectors.toSet());
System.out.println(distinctWords.size()+
" distinct words: " +
distinctWords);
}
}Using the
for-each Construct:
import java.util.*;
public class FindDups {
public static void main(String[] args) {
Set<String> s = new HashSet<String>();
for (String a : args)
s.add(a);
System.out.println(s.size() + " distinct words: " + s);
}
}
Now run either version of the program.
java FindDups i came i saw i leftThe following output is produced:
4 distinct words: [left, came, saw, i]Note that the code always refers to the
Collection by its interface type (Set) rather than by its implementation type. This is a strongly recommended programming practice because it gives you the flexibility to change implementations merely by changing the constructor. If either of the variables used to store a collection or the parameters used to pass it around are declared to be of the
Collection's implementation type rather than its interface type,
all such variables and parameters must be changed in order to change its implementation type.
Furthermore, there's no guarantee that the resulting program will work. If the program uses any nonstandard operations present in the original implementation type but not in the new one, the program will fail.Referring to collections only by their interface prevents you from using any nonstandard operations.
The implementation type of the Set in the preceding example isHashSet, which makes no guarantees as to the order of the elements in theSet. If you want the program to print the word list in alphabetical order, merely change theSet's implementation type from HashSet to TreeSet. Making this trivial one-line change causes the command line in the previous example to generate the following output.
java FindDups i came i saw i left 4 distinct words: [came, i, left, saw]
Set Interface Bulk Operations
Bulk operations are particularly well suited to Sets; when applied, they perform standard set-algebraic operations. Supposes1 ands2 are sets. Here's what bulk operations do:
s1.containsAll(s2)— returnstrueifs2is a subsetofs1. (s2is a subset ofs1if sets1contains all of the elements ins2.)s1.addAll(s2)— transformss1into the union ofs1ands2. (The union of two sets is the set containing all of the elements contained in either set.)s1.retainAll(s2)— transformss1into the intersection ofs1ands2. (The intersection of two sets is the set containing only the elements common to both sets.)s1.removeAll(s2)— transformss1into the (asymmetric) set difference ofs1ands2. (For example, the set difference ofs1minuss2is the set containing all of the elements found ins1but not ins2.)
To calculate the union, intersection, or set difference of two sets nondestructively (without modifying either set), the caller must copy one set before calling the appropriate bulk operation. The following are the resulting idioms.
Set<Type> union = new HashSet<Type>(s1); union.addAll(s2); Set<Type> intersection = new HashSet<Type>(s1); intersection.retainAll(s2); Set<Type> difference = new HashSet<Type>(s1); difference.removeAll(s2);The implementation type of the result
Set in the preceding idioms is
HashSet, which is, as already mentioned, the best all-around
Set implementation in the Java platform. However, any general-purpose
Set implementation could be substituted.
Let's revisit the FindDups program. Suppose you want to know which words in the argument list occur only once and which occur more than once, but you do not want any duplicates printed out repeatedly. This effect can be achieved by generating two sets — one containing every word in the argument list and the other containing only the duplicates. The words that occur only once are the set difference of these two sets, which we know how to compute. Here's howthe resulting program looks.
import java.util.*;
public class FindDups2 {
public static void main(String[] args) {
Set<String> uniques = new HashSet<String>();
Set<String> dups = new HashSet<String>();
for (String a : args)
if (!uniques.add(a))
dups.add(a);
// Destructive set-difference
uniques.removeAll(dups);
System.out.println("Unique words: " + uniques);
System.out.println("Duplicate words: " + dups);
}
} When run with the same argument list used earlier (
i came i saw i left), the program yields the following output.
Unique words: [left, saw, came] Duplicate words: [i]A less common set-algebraic operation is the symmetric set difference — the set of elements contained in either of two specified sets but not in both. The following code calculates the symmetric set difference of two sets nondestructively.
Set<Type> symmetricDiff = new HashSet<Type>(s1); symmetricDiff.addAll(s2); Set<Type> tmp = new HashSet<Type>(s1); tmp.retainAll(s2); symmetricDiff.removeAll(tmp);
Set Interface Array Operations
The array operations don't do anything special for Sets beyond what they do for any otherCollection. These operations are described in The Collection Interface section.
The List Interface
A List is an ordered Collection (sometimes called a sequence). Lists may contain duplicate elements. In addition to the operations inherited fromCollection, theList interface includes operations for the following:
Positional access— manipulates elements based on their numerical position in the list. This includes methods such asget,set,add,addAll, andremove.Search— searches for a specified object in the list and returns its numerical position. Search methods includeindexOfandlastIndexOf.Iteration— extendsIteratorsemantics to take advantage of the list's sequential nature. ThelistIteratormethods provide this behavior.Range-view— Thesublistmethod performs arbitrary range operations on the list.
The Java platform contains two general-purpose List implementations.ArrayList, which is usually the better-performing implementation, and LinkedList which offers better performance under certain circumstances.
Collection Operations
The operations inherited from Collection all do about what you'd expect them to do, assuming you're already familiar with them. If you're not familiar with them fromCollection, now would be a good time to read The Collection Interface section. The remove operation always removes the first occurrence of the specified element from the list. Theadd and addAll operations always append the new element(s) to theend of the list. Thus, the following idiom concatenates one list to another.
list1.addAll(list2);Here's a nondestructive form of this idiom, which produces a third
List consisting of the second list appended to the first.
List<Type> list3 = new ArrayList<Type>(list1); list3.addAll(list2);
Note that the idiom, in its nondestructive form, takes advantage of ArrayList's standard conversion constructor.
And here's an example (JDK 8 and later) that aggregates some names into a List:
List<String> list = people.stream() .map(Person::getName) .collect(Collectors.toList());
Like the Set interface, List strengthens the requirements on theequals and hashCode methods so that two List objects can be compared for logical equality without regard to their implementation classes.Two List objects are equal if they contain the same elements in the same order.
Positional Access and Search Operations
The basic positional access operations are get, set, add and remove. (The set and remove operations return the old value that is being overwritten or removed.) Other operations (indexOf and lastIndexOf) return the first or last index of the specified element in the list.
The addAll operation inserts all the elements of the specifiedCollection starting at the specified position. The elements are inserted in the order they are returned by the specified Collection's iterator. This call is the positional access analog ofCollection's addAll operation.
Here's a little method to swap two indexed values in a List.
public static <E> void swap(List<E> a, int i, int j) {
E tmp = a.get(i);
a.set(i, a.get(j));
a.set(j, tmp);
} Of course, there's one big difference. This is a polymorphic algorithm: It swaps two elements in any
List, regardless of its implementation type. Here's another polymorphic algorithm that uses the preceding
swap method.
public static void shuffle(List<?> list, Random rnd) {
for (int i = list.size(); i > 1; i--)
swap(list, i - 1, rnd.nextInt(i));
} This algorithm, which is included in the Java platform's
Collections class, randomly permutes the specified list using the specified source of randomness. It's a bit subtle: It runs up the list from the bottom, repeatedly swapping a randomly selected element into the current position.
Unlike most naive attempts at shuffling, it's fair (all permutations occur with equal likelihood, assuming an unbiased source of randomness) andfast (requiring exactly list.size()-1 swaps). The following program uses this algorithm to print the words in its argument list in random order.
import java.util.*;
public class Shuffle {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
for (String a : args)
list.add(a);
Collections.shuffle(list, new Random());
System.out.println(list);
}
} In fact, this program can be made even shorter and faster. The
Arrays class has a static factory method called
asList, which allows an array to be viewed as a
List.
This method does not copy the array. Changes in theList write through to the array and vice versa. The resulting List is not a general-purpose
List implementation, because it doesn't implement the (optional)
add and
remove operations: Arrays are not resizable. Taking advantage of
Arrays.asList and calling the library version of
shuffle, which uses a default source of randomness, you get the following
tiny program whose behavior is identical to the previous program.
import java.util.*;
public class Shuffle {
public static void main(String[] args) {
List<String> list = Arrays.asList(args);
Collections.shuffle(list);
System.out.println(list);
}
}
Iterators
As you'd expect, the Iterator returned by List'siterator operation returns the elements of the list in proper sequence.List also provides a richer iterator, called aListIterator, which allows you to traverse the list in either direction, modify the list during iteration, and obtain the current position of the iterator.
The three methods that ListIterator inherits from Iterator (hasNext,next, and remove) do exactly the same thing in both interfaces. ThehasPrevious and the previous operations are exact analogues ofhasNext and next. The former operations refer to the element before the (implicit) cursor, whereas the latter refer to the element after the cursor. Theprevious operation moves the cursor backward, whereas next moves it forward.
Here's the standard idiom for iterating backward through a list.
for (ListIterator<Type> it = list.listIterator(list.size()); it.hasPrevious(); ) {
Type t = it.previous();
...
}
Note the argument to listIterator in the preceding idiom. TheList interface has two forms of the listIterator method.The form with no arguments returns a ListIterator positioned at the beginning of the list; the form with anint argument returns a ListIterator positioned at the specified index. The index refers to the element that would be returned by an initial call tonext. An initial call to previous would return the element whose index wasindex-1. In a list of length n, there are n+1 valid values for index, from 0 to n, inclusive.
Intuitively speaking, the cursor is always between two elements — the one that would be returned by a call toprevious and the one that would be returned by a call to next. Then+1 valid index values correspond to the n+1 gaps between elements, from the gap before the first element to the gap after the last one.The following figure shows the five possible cursor positions in a list containing four elements.

The five possible cursor positions.
Calls to next and previous can be intermixed, but you have to be a bit careful. The first call toprevious returns the same element as the last call to next. Similarly, the first call tonext after a sequence of calls to previous returns the same element as the last call toprevious.
It should come as no surprise that the nextIndex method returns the index of the element that would be returned by a subsequent call tonext, and previousIndex returns the index of the element that would be returned by a subsequent call toprevious. These calls are typically used either to report the position where something was found or to record the position of theListIterator so that another ListIterator with identical position can be created.
It should also come as no surprise that the number returned by nextIndex is always one greater than the number returned bypreviousIndex. This implies the behavior of the two boundary cases: (1) a call to previousIndex when the cursor is before the initial element returns-1 and (2) a call to nextIndex when the cursor is after the final element returnslist.size(). To make all this concrete, the following is a possible implementation ofList.indexOf.
public int indexOf(E e) {
for (ListIterator<E> it = listIterator(); it.hasNext(); )
if (e == null ? it.next() == null : e.equals(it.next()))
return it.previousIndex();
// Element not found
return -1;
}
Note that the indexOf method returns it.previousIndex() even though it is traversing the list in the forward direction. The reason is thatit.nextIndex() would return the index of the element we are about to examine, and we want to return the index of the element we just examined. (注:next()是得到当前游标处的元素,然后把游标往后移一个位置,因此该函数需要返回previousIndex()。)
The Iterator interface provides the remove operation to remove the last element returned bynext from the Collection. For ListIterator, this operation removes the last element returned bynext or previous. The ListIterator interface provides two additional operations to modify the list —set and add. The set method overwrites the last element returned bynext or previous with the specified element. The following polymorphic algorithm usesset to replace all occurrences of one specified value with another.
public static <E> void replace(List<E> list, E val, E newVal) {
for (ListIterator<E> it = list.listIterator(); it.hasNext(); )
if (val == null ? it.next() == null : val.equals(it.next()))
it.set(newVal);
}
The only bit of trickiness in this example is the equality test between val and it.next. You need to special-case aval value of null to prevent a NullPointerException.
The add method inserts a new element into the list immediately before the current cursor position. This method is illustrated in the following polymorphic algorithm to replace all occurrences of a specified value with the sequence of values contained in the specified list.
public static <E>
void replace(List<E> list, E val, List<? extends E> newVals) {
for (ListIterator<E> it = list.listIterator(); it.hasNext(); ){
if (val == null ? it.next() == null : val.equals(it.next())) {
it.remove();
for (E e : newVals)
it.add(e);
}
}
}
Range-View Operation
The range-view operation, subList(int fromIndex, int toIndex), returns aList view of the portion of this list whose indices range from fromIndex, inclusive, to toIndex, exclusive. This half-open range mirrors the typicalfor loop.
for (int i = fromIndex; i < toIndex; i++) {
...
}
As the term view implies, the returnedList is backed up by the List on which subList was called, so changes in the former are reflected in the latter.
This method eliminates the need for explicit range operations (of the sort that commonly exist for arrays). Any operation that expects aList can be used as a range operation by passing a subList view instead of a wholeList. For example, the following idiom removes a range of elements from aList.
list.subList(fromIndex, toIndex).clear();Similar idioms can be constructed to search for an element in a range.
int i = list.subList(fromIndex, toIndex).indexOf(o); int j = list.subList(fromIndex, toIndex).lastIndexOf(o);
Note that the preceding idioms return the index of the found element in thesubList, not the index in the backing List.
Any polymorphic algorithm that operates on a List, such as thereplace and shuffle examples, works with the List returned bysubList.
Here's a polymorphic algorithm whose implementation uses subList to deal a hand from a deck. That is, it returns a newList (the "hand") containing the specified number of elements taken from the end of the specifiedList (the "deck"). The elements returned in the hand are removed from the deck.
public static <E> List<E> dealHand(List<E> deck, int n) {
int deckSize = deck.size();
List<E> handView = deck.subList(deckSize - n, deckSize);
List<E> hand = new ArrayList<E>(handView);
handView.clear();
return hand;
}
Note that this algorithm removes the hand from the end of the deck.For many common List implementations, such asArrayList, the performance of removing elements from the end of the list is substantially better than that of removing elements from the beginning.
The following is a program that uses the dealHand method in combination withCollections.shuffle to generate hands from a normal 52-card deck. The program takes two command-line arguments: (1) the number of hands to deal and (2) the number of cards in each hand.
import java.util.*;
public class Deal {
public static void main(String[] args) {
if (args.length < 2) {
System.out.println("Usage: Deal hands cards");
return;
}
int numHands = Integer.parseInt(args[0]);
int cardsPerHand = Integer.parseInt(args[1]);
// Make a normal 52-card deck.
String[] suit = new String[] {
"spades", "hearts",
"diamonds", "clubs"
};
String[] rank = new String[] {
"ace", "2", "3", "4",
"5", "6", "7", "8", "9", "10",
"jack", "queen", "king"
};
List<String> deck = new ArrayList<String>();
for (int i = 0; i < suit.length; i++)
for (int j = 0; j < rank.length; j++)
deck.add(rank[j] + " of " + suit[i]);
// Shuffle the deck.
Collections.shuffle(deck);
if (numHands * cardsPerHand > deck.size()) {
System.out.println("Not enough cards.");
return;
}
for (int i = 0; i < numHands; i++)
System.out.println(dealHand(deck, cardsPerHand));
}
public static <E> List<E> dealHand(List<E> deck, int n) {
int deckSize = deck.size();
List<E> handView = deck.subList(deckSize - n, deckSize);
List<E> hand = new ArrayList<E>(handView);
handView.clear();
return hand;
}
} Running the program produces output like the following.
% java Deal 4 5
[8 of hearts, jack of spades, 3 of spades, 4 of spades,
king of diamonds]
[4 of diamonds, ace of clubs, 6 of clubs, jack of hearts,
queen of hearts]
[7 of spades, 5 of spades, 2 of diamonds, queen of diamonds,
9 of clubs]
[8 of spades, 6 of diamonds, ace of spades, 3 of hearts,
ace of hearts]
Although the subList operation is extremely powerful, some care must be exercised when using it.The semantics of the List returned bysubList become undefined if elements are added to or removed from the backingList in any way other than via the returned List. Thus, it's highly recommended that you use theList returned by subList only as a transient object — to perform one or a sequence of range operations on the backingList. The longer you use the subList instance, the greater the probability that you'll compromise it by modifying the backingList directly or through another subList object. Note that it is legal to modify a sublist of a sublist and to continue using the original sublist (though not concurrently).
List Algorithms
Most polymorphic algorithms in the Collections class apply specifically toList. Having all these algorithms at your disposal makes it very easy to manipulate lists. Here's a summary of these algorithms, which are described in more detail in theAlgorithms section.
sort— sorts aListusing a merge sort algorithm, which provides a fast, stable sort. (Astable sort is one that does not reorder equal elements.)shuffle— randomly permutes the elements in aList.reverse— reverses the order of the elements in aList.rotate— rotates all the elements in aListby a specified distance.swap— swaps the elements at specified positions in aList.replaceAll— replaces all occurrences of one specified value with another.fill— overwrites every element in aListwith the specified value.copy— copies the sourceListinto the destinationList.binarySearch— searches for an element in an orderedListusing the binary search algorithm.indexOfSubList— returns the index of the first sublist of oneListthat is equal to another.lastIndexOfSubList— returns the index of the last sublist of oneListthat is equal to another.
Original: http://docs.oracle.com/javase/tutorial/collections/interfaces/index.html